







1.训练过程中存在的不平衡
在目标检测中,往往更加关注的是模型结构,但是与模型结构相比,训练过程对目标检测器来说也是很关键的。文中发现目标检测器性能往往收到训练过程中的不平衡的限制,这包括以下三点(如Fig1所示):1)sample level(样本层面),在训练一个检测器的时候,hard samples可以提高检测性能。然后使用随机采样的方式通常会导致选择的样本以简单样本为主。OHEM可以对这个缓解该问题,但是对噪声标签很敏感,并产生相当大的内存和计算成本。Focal Loss在一阶段算法中能有效缓解采样不平衡的问题,但是扩展到两阶段算法中由于大部分majority easy negatives被RPN过滤掉,所以效果也不是很好。2)feature level(特征层面),在backbone中深层特征具有更多的语义信息,而低层特征包含更多的细节信息(如轮廓,纹理等),在FPN中通过将高层特征与低层特征融合来提高检测的性能,本文认为,融合的信息应该包含每个分辨率的平衡信息。但是在FPN中使得融合的特征更多的关注于相邻的分辨率为不是其他分辨率。在信息传递过程中,每次融合操作,会使得非相邻层级的语义信息变得稀释。3)objective level(训练目标层面),在目标检测中需要完成两个任务,目标的分类和回归,可以将其看作是一个multi-task的训练优化问题,如果不能很好的平衡两个目标,可能导致整体性能的下降,此情形同样适用于训练过程中的样本,如果不能很好地平衡,容易样品产生的小梯度可能会被难样品产生的大梯度所淹没,从而限制进一步的细化。

2.文中给出的三点改进
2.1 IOU-balanced sampling
作者进行了一个实验,其目的是验证训练样本与其对应的ground truth之间的重叠是否与其困难有关。结果如下图Fig2所示,超过60%的hard negative samples的IoU都是大于0.05的,但是在随机抽样中,只有大约30%的样本IoU大于0.05,这将导致背景远远大于ground truth。本文提出一种平衡方法IOU-balanced sampling,这里假设要从M个候选样本中取N个负样本,那么随机采样的概率为:,为了增加hard negative samples被抽中的概率,本文提出了IOU-balanced sampling,其做法是根据IOU将采样区域分成K个格子。N个负样本平均分配到每个格子中,然后均匀的从中选择样本,此时被选中的概率为:
,k∈[0, K),其中
是用k表示的相应区间内候选样本的数量,文中默认为3。

2.2 Balanced Feature Pyramid
与以前使用的横向连接融合多层特征的方法不同,本文的关键思想是使用相同的深度集成的平衡语义特征来加强多级特征(如下图Fig3所示)。为了融合不同层级的特征,同时还要保留其语义信息,首先要将不同层级的特征,
,
,
基于插值或者max pooling resize到同一个尺寸,例如取
,然后取其平均值得到平衡后的语义特征。接下来作者参照Non-local neural networks使用Gaussian non-local attention来增强integrate后的特征,融合后得到的特征
,
,
,
用于后续的目标检测中,流程和FPN相同。

2.3 Balanced L1 Loss
在Fast R-CNN中使用如下所示公式1来解决分类和回归损失的。这里在回归损失前面加入了一个参数来对损失函数进行调整,引入参数的原因是这个损失函数是两个loss的相加,那么如果分类的效果已经很好了也会得到一个很好的损失值,这样的话就会忽略了回归的重要性。文中把样本损失大于等于 1.0 的叫做 outliers,小于的叫做 inliers。为了平衡不同的任务,就需要对参数进行调整,但是,由于回归目标是没有边界限制的,直接增加回归损失的权重将会使模型对 outliers 更加敏感。对于 outliers 会被看作是困难样本,这些困难样本会产生巨大的梯度不利于训练的过程,而 inliers 被看做是简单样本只会产生相比 outliers 大概 0.3 倍的梯度。
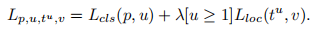
基于上述问题,作者提出balanced L1 loss,balanced L1 loss是受到了smooth L1 loss的启发,在smooth L1 loss中,通过设置一个拐点来区分inliers和outliers,并对outliers设置最大值1.0进行梯度截断,如下图Fig4(a)中的虚线所示。balanced L1 loss的主要目的就是提升inliers中的梯度,图Fig4(a)中虚线上面的部分,让位于拐点之前的nliers产生更大的梯度。 作者通过参数来调整回归损失的上界如图Fig4(b)所示,通过调整参数
,
,可以得到更加平衡的训练。

balanced L1 loss中的公式如下所示:
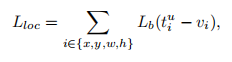
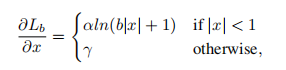
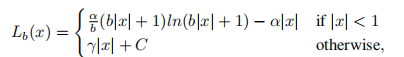
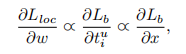
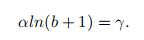
3.实验
1)对于IOU-balanced sampling的实验如下图Fig5所示,实验证明对于K的取值并不是很敏感,取不同的KK值在AP上表现的差别不是很大,那么文章提出这种方法最大的特点就是可以在IOU上均匀采样,使得hard negative在IOU上均匀分布。

2)对于Balanced Feature Pyramid的实验如下图Fig6所示,可以看出本文提出的方法在AP上有所提高。

3)对于balanced L1 loss的实验如下图Fig7所示,可以看出在=0.5,
=1.5的时候AP值最高。

4)从下图Fig8中可以看出在三种方法都使用的情况下AP值最好。

5)下图Fig9为在coco数据集上与其他模型的比较。

















 845
845











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











