







论文题目:Selective Kernel Networks
发表于 CVPR 2019
论文地址:https://arxiv.org/pdf/1903.06586.pdf
作为一下对比,这里再附上SEnet的结构图:
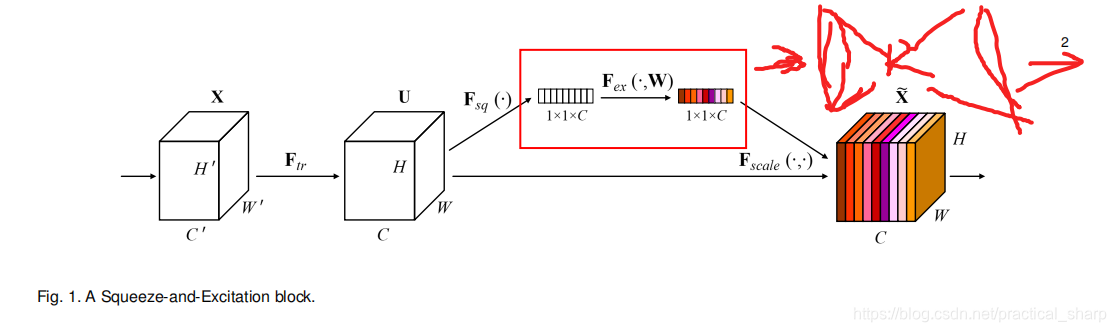
总结:SK注意力机制和SE注意力机制的不同之处:
- SE注意力只是在通道上施加MLP学习权重,来体现每个权重之间的重要性差异;
- SE注意力机制只需要用到一个全局池化和两个全连接层;
- SK注意力机制是SE注意力机制的升级版,特色之处体现在通过网络自己学习来选择融合不同感受野的特征图信息;
- SK注意力机制涉及到空洞卷积,组卷积,全局平均池化还有全连接层,不过是通过卷积实现的;
SK注意力机制是如何实现的?
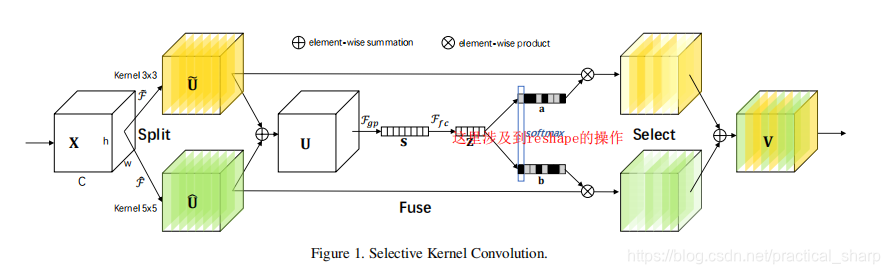
其实说白了,SK是可以选择融合不同感受野信息的卷积核。
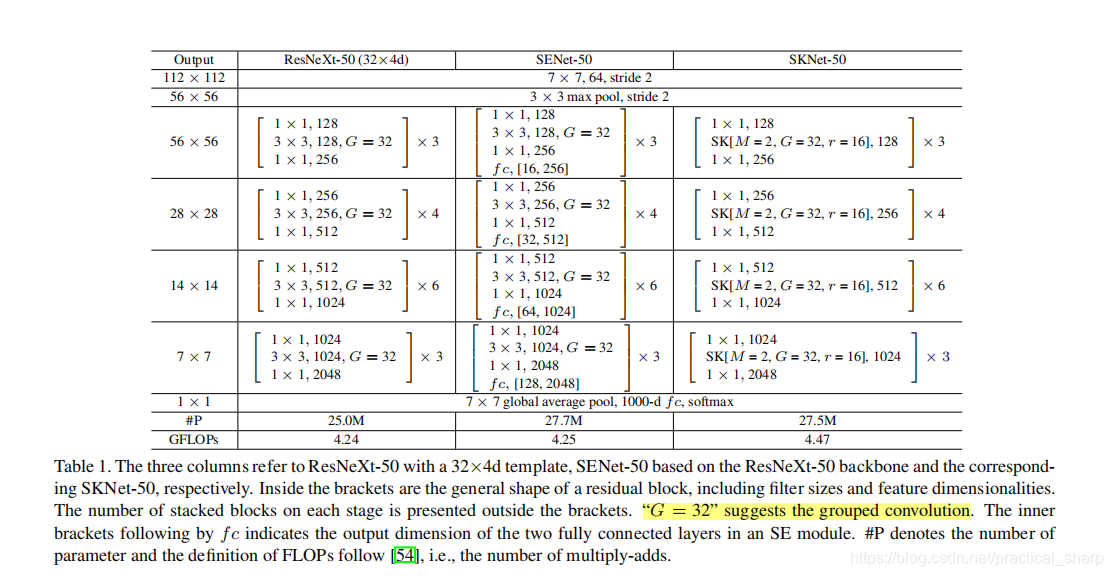
使用SK注意力机制构建ResNet,也就只是将original Residual Block中的3*3的普通卷积核,替换成SK卷积核。
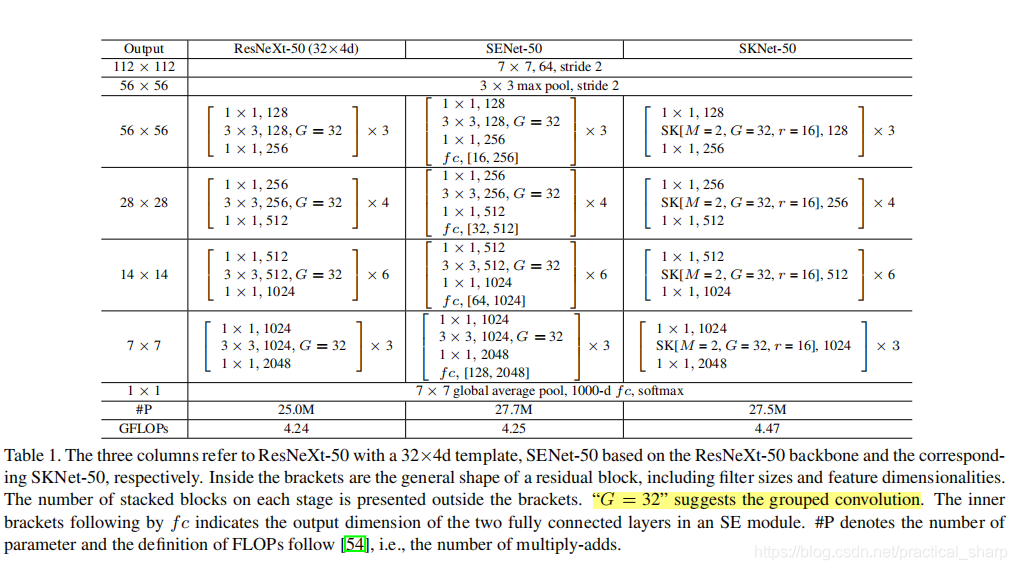
如上图,SK[M=2,G=32,r=16]表示的是什么意思呢?
首先,M表示的是使用不同感受野卷积核的数量,
G表示的是分组卷积的分组数,
r表示的是融合阶段的reduction系数
SK注意力机制的三部曲 Split、Fuse、Select
Split:
我们约定,输入特征图的维度是[batch_size, C, H, W]
首先Split是将输入的特征图X通过不同感受野的空洞卷积,上图中的M = 2,代表两组卷积操作,
一个kernel = 3 * 3,其实dilation = 1,得到特征图
这个特征图的维度仍然是[batch_size, C, H, W]
一个kernel = 5 * 5,得到特征图
其实真正的kernel_size = 3 * 3,
不过dilation = 2,所以实际的kernel = 5 * 5
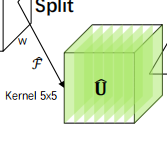
这个特征图的维度也是[batch_size, C, H, W]
Fuse:
然后这两个特征图通过 element wise sum得到特征图U:

两个相同维度的特征图进行按元素相加,得到的特征图U的维度 也是[batch_size, C, H, W]
然后对U进行全局平均池化得到S:

得到的Sc的维度是[batch_size, C, 1, 1]
对于得到的Sc,其实就是SE注意力机制中的通道注意力了,
论文中定义了一个压缩通道的系数d:
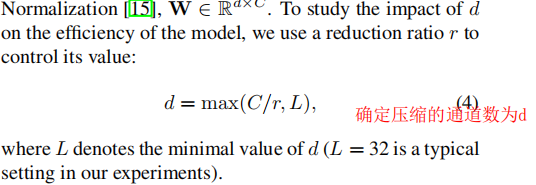
其中 C是输入特征图的channel,r是超参数reduction,论文中提到的是r = 16;
L也是超参数,论文中设定的是L = 32;
对于经过全局平均池化的Sc,再进入一个全连接层得到压缩后的通道特征Z,起到降维的作用。
得到的Z的特征图的维度是[batch_size, d, 1, 1] 注意: C>d,所以起到降维的作用
然后再经过一个全连接层得到进行还原成M*C维的向量,起到升维的作用。
还原之后的特征图的大小的维度[batch_size, M*C, 1, 1]
其实这两个全连接层和SE注意力机制中起到的作用是一样的。
就是一个感知机,对通道注意力进行压缩然后再还原成输入向量的M倍,起到一个线性变换的作用。
为什么是M倍呢?
很简单,因为Split这一阶段进行了多组卷积的处理,这里需要对这多组卷积生成的特征图都进行空间注意力的提取。
在这之后,需要做的就是对于[batch_size, M*C, 1, 1]的特征图进行维度上的调整,使得其维度能对应成M个特征图,然后softmax之后进行select操作。
[batch_size, M*C, 1, 1]的特征图进行维度上的调整,变为 [batch_size, M, C, 1] 的大小,对应M个特征图
Select:
然后进行softmax,这是维度上没有任何变化。

接着将 [batch_size, M, C, 1] 的向量 变成 M 个[batch_size, 1, C, 1]的向量。
再进行reshape操作,变成M个[batch_size, C, 1, 1]的特征图,这样正好就是通道注意力特征图了。
接下来的操作就和SE模块一样了。将通道注意力与对应的特征图element wise相乘,然后M个特征图再element wise相加

就得到了最后的输出特征图了。
talk is easy, show your my code:
import torch.nn as nn
import torch
from functools import reduce
class SKConv(nn.Module):
def __init__(self,in_channels,out_channels,stride=1,M=2,r=16,L=32):
'''
:param in_channels: 输入通道维度
:param out_channels: 输出通道维度 原论文中 输入输出通道维度相同
:param stride: 步长,默认为1
:param M: 分支数
:param r: 特征Z的长度,计算其维度d 时所需的比率(论文中 特征S->Z 是降维,故需要规定 降维的下界)
:param L: 论文中规定特征Z的下界,默认为32
采用分组卷积: groups = 32,所以输入channel的数值必须是group的整数倍
'''
super(SKConv,self).__init__()
d=max(in_channels//r,L) # 计算从向量C降维到 向量Z 的长度d
self.M=M
self.out_channels=out_channels
self.conv=nn.ModuleList() # 根据分支数量 添加 不同核的卷积操作
for i in range(M):
# 为提高效率,原论文中 扩张卷积5x5为 (3X3,dilation=2)来代替。 且论文中建议组卷积G=32
self.conv.append(nn.Sequential(nn.Conv2d(in_channels,out_channels,3,stride,padding=1+i,dilation=1+i,groups=32,bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)))
self.global_pool=nn.AdaptiveAvgPool2d(output_size = 1) # 自适应pool到指定维度 这里指定为1,实现 GAP
self.fc1=nn.Sequential(nn.Conv2d(out_channels,d,1,bias=False),
nn.BatchNorm2d(d),
nn.ReLU(inplace=True)) # 降维
self.fc2=nn.Conv2d(d,out_channels*M,1,1,bias=False) # 升维
self.softmax=nn.Softmax(dim=1) # 指定dim=1 使得两个全连接层对应位置进行softmax,保证 对应位置a+b+..=1
def forward(self, input):
batch_size=input.size(0)
output=[]
#the part of split
for i,conv in enumerate(self.conv):
#print(i,conv(input).size())
output.append(conv(input)) #[batch_size,out_channels,H,W]
#the part of fusion
U=reduce(lambda x,y:x+y,output) # 逐元素相加生成 混合特征U [batch_size,channel,H,W]
print(U.size())
s=self.global_pool(U) # [batch_size,channel,1,1]
print(s.size())
z=self.fc1(s) # S->Z降维 # [batch_size,d,1,1]
print(z.size())
a_b=self.fc2(z) # Z->a,b 升维 论文使用conv 1x1表示全连接。结果中前一半通道值为a,后一半为b [batch_size,out_channels*M,1,1]
print(a_b.size())
a_b=a_b.reshape(batch_size,self.M,self.out_channels,-1) #调整形状,变为 两个全连接层的值[batch_size,M,out_channels,1]
print(a_b.size())
a_b=self.softmax(a_b) # 使得两个全连接层对应位置进行softmax [batch_size,M,out_channels,1]
#the part of selection
a_b=list(a_b.chunk(self.M,dim=1))#split to a and b chunk为pytorch方法,将tensor按照指定维度切分成 几个tensor块 [[batch_size,1,out_channels,1],[batch_size,1,out_channels,1]
print(a_b[0].size())
print(a_b[1].size())
a_b=list(map(lambda x:x.reshape(batch_size,self.out_channels,1,1),a_b)) # 将所有分块 调整形状,即扩展两维 [[batch_size,out_channels,1,1],[batch_size,out_channels,1,1]
V=list(map(lambda x,y:x*y,output,a_b)) # 权重与对应 不同卷积核输出的U 逐元素相乘[batch_size,out_channels,H,W] * [batch_size,out_channels,1,1] = [batch_size,out_channels,H,W]
V=reduce(lambda x,y:x+y,V) # 两个加权后的特征 逐元素相加 [batch_size,out_channels,H,W] + [batch_size,out_channels,H,W] = [batch_size,out_channels,H,W]
return V # [batch_size,out_channels,H,W]
"""
x = torch.Tensor(8,32,24,24)
conv = SKConv(32,32,1,2,16,32)
print(conv(x).size())
"""
如何构建论文中的SKNet?
只需要将 ResNet的block中3*3卷积用SKconv来替代就行了。
class SKBlock(nn.Module):
'''
基于Res Block构造的SK Block
ResNeXt有 1x1Conv(通道数:x) + SKConv(通道数:x) + 1x1Conv(通道数:2x) 构成
'''
expansion=2 #指 每个block中 通道数增大指定倍数
def __init__(self,inplanes,planes,stride=1,downsample=None):
super(SKBlock,self).__init__()
self.conv1=nn.Sequential(nn.Conv2d(inplanes,planes,1,1,0,bias=False),
nn.BatchNorm2d(planes),
nn.ReLU(inplace=True))
self.conv2=SKConv(planes,planes,stride)
# 与 ResNet block最大的区别就在于中间的这个3*3的卷积 使用 SkConv进行取代
self.conv3=nn.Sequential(nn.Conv2d(planes,planes*self.expansion,1,1,0,bias=False),
nn.BatchNorm2d(planes*self.expansion))
self.relu=nn.ReLU(inplace=True)
self.downsample=downsample
def forward(self, input):
shortcut=input
output=self.conv1(input)
output=self.conv2(output)
output=self.conv3(output)
if self.downsample is not None:
shortcut=self.downsample(input)
output+=shortcut
return self.relu(output)

















 404
404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









