







LIFT: Learned Invariant Feature Transform
该文介绍了一种深度学习框架,并实现了图像特征点检测、方向估计和描述符提取,其中每一个部分都是基于卷积神经网络CNNs实现,采用了空间转换层来修正图像块得到特征点检测和方向估计。同时,使用argmax function代替传统的非极大值抑制方法,其性能由于其他在这之前已知的方法。总体结构如下:
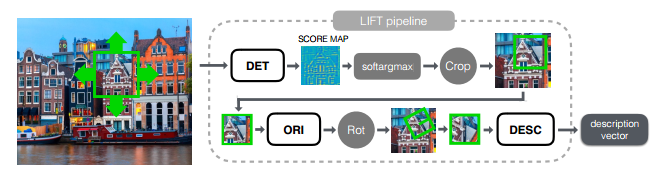
训练方法:
- 建立Siamese网络,训练所使用的特征点事来之SFM算法的结果,输入的是特征点所在的图像块;
- 首先训练描述符,然后用来训练方向估计,最后训练特征点检测;
- 训练是使用的图像块,并且是不同尺度。
训练步骤:
1. 首先训练描述符:训练图像块的位置和方向均来自SFM的特征点,其中会取四个图像块P1,P2,P3,P4;P1,P2是来自同一个3D点在不同视角下的图像,P3是不同3D点投影回来的图像块,P4是不包含任何特征点的图像块。那么损失函数的构建就为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 348
348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









