






在机器学习的浩瀚星空中,决策树无疑是一颗闪耀着经典光辉的恒星。尽管在如今这个技术飞速发展、新算法不断涌现的时代,决策树被看作是一种传统的机器学习技术,但它在汽车性能评估领域的价值依然不可低估。
汽车,作为现代社会的重要交通工具,其性能关乎着安全、效率以及驾驶体验等诸多关键因素。对汽车性能进行准确评估是汽车制造商、经销商以及消费者都非常关注的事情。传统的评估方式往往存在主观片面性或者需要复杂的测试流程。而决策树,这个有着简洁结构和明确逻辑的传统机器学习技术,就像是一把精准的手术刀,能够剖析汽车众多的参数和特性,从而对汽车性能做出较为客观的评估。现在,就让我们开启机器学习实战:基于决策树的汽车性能评估之旅。
一、实验目的
本实验通过对汽车评估数据集的机器学习实战项目,探索和应用决策树和随机森林模型根据车辆的属性预测其评估等级。通过对比不同特征选择方法和模型建立参数的选择,评估模型的准确性和稳定性,并探究特征值对预测结果的重要性。
主要目标包括:
1.使用决策树模型对汽车评估数据集进行分类预测。
2.比较信息增益和基尼系数两种特征选择方法在决策树模型中的表现。
3.通过交叉验证和剪枝确定决策树的最佳高度和剪枝参数。
4.建立随机森林模型并评估其预测性能。
5.分析和比较不同模型的准确率和特征重要性。
二、实验原理
在本实验中,我们使用了UCI Machine Learning Repository(UCI机器学习库)提供的汽车评估数据集。数据处理我们主要进行了数据预处理。 数据预处理是指将原始数据转换为模型能够使用的格式。在本实验中,我们使用pandas库读入csv格式数据,并通过一些数据处理流程将String类型的数据转换为数值类型,以便于模型运用。
1.决策树
决策树是一种基于树结构的分类算法,它通过逐步选择最优特征并根据特征值进行分割来构建树模型。它的核心思想是将数据集按照特征值分割为更纯的子集,直到子集中的样本具有相同的类别标签或达到预定的停止条件。
(1)特征选择
特征选择是决策树构建中的关键步骤。本实验中使用的特征选择方法有信息增益和基尼系数。
①信息增益:信息增益是基于信息熵的概念,它描述了在已知某个特征值的情况下,对目标变量的不确定性减少的程度。信息熵衡量了系统的无序程度,信息增益越大则表示该特征对目标变量的影响越大。
②基尼系数:基尼系数描述了从一个数据集中随机选取两个样本,它们类别不一致的概率。基尼系数越小表示数据集中的样本越倾向于同一类别。基尼系数的选择与信息增益类似,都是寻找最优特征。基尼系数是信息增益的一种替代方法,在实际应用中常常效果相似。
决策树模型的优点包括易于解释和可视化、能处理多类别问题、对异常值不敏感。但它也容易过拟合训练数据,并且对数据中的噪声和不相关特征比较敏感。
(2)交叉验证和剪枝
为了完善决策树模型并提高预测性能,可以通过交叉验证和剪枝来选择合适的决策树高度和剪枝参数。
①交叉验证:交叉验证是一种用于评估模型性能和选择参数的技术。通过将训练集划分为多个子集,然后依次使用每个子集作为验证集并在剩余的子集上训练模型,从而获得多个模型的性能评估结果。
②剪枝:剪枝是决策树模型优化的一种方法,主要目的是减少过拟合。剪枝通过去除决策树中某些节点和分支来简化模型,从而使其更加泛化。剪枝包括预剪枝(在构建过程中进行剪枝)和后剪枝(构建完整的树后再进行剪枝)等策略。
2.随机森林
随机森林是一种集成学习方法,它通过创建多个决策树并结合它们的预测结果来进行分类。随机森林可以减少决策树的过拟合问题,并通过投票或平均来提高模型的稳定性和准确性。
随机森林的核心思想是每个决策树的训练样本和特征都是通过有放回的抽样来获得的。这种抽样方式称为bootstrap采样。另外,在决策树的分割过程中,对于每个节点,只考虑随机选择的一部分特征。通过集成多个决策树的预测结果,随机森林可以更好地适应复杂的数据集,并具有较低的过拟合风险。同时随机森林还可以通过测量特征的重要性来提供更多信息。在随机森林中,特征的重要性是通过计算每个特征在所有决策树中被使用的频率和相对重要性来确定的。通过分析特征重要性,我们可以了解哪些特征对于预测目标变量来说是最重要的,从而进行特征选择、特征工程或进一步的模型优化。
本实验通过决策树和随机森林模型对汽车评估数据集进行处理和分析。决策树使用信息增益或基尼系数作为特征选择方法,并使用交叉验证和剪枝来优化模型。随机森林通过组合多个决策树的预测结果来提高模型的性能,同时还进行分析特征重要性。
三、实验数据收集
数据集选取自网站Car Evaluation - UCI Machine Learning Repository,使用了car-evaluation数据集中的car.data。该数据集含有六个特征分别为buying(购买价格)分别包括low,med,high,vhigh四种价格;maint(保养价格)也包括同样的四个价格;doors(门的个数)分别为2,3,4,5more;persons(载人个数)包括2,3,more;lug_boot(车身大小),分别为small,med,big;safety(安全性)包括low,med,high。包含四个标签,分别为unacc(不能接受),acc(可以接受),good(好),vgood(非常好)。
四、实验环境
在实验过程中,使用了以下工具和库:
Python编程语言
Jupyter Notebook环境
Pandas库和Numpy库:读取car.data数据集并对数据集进行处理和分析。
Scikit-learn库:用于机器学习算法的建模和评估包括:解决决策树和随机森林分类问题,衡量模型的性能和预测结果的准确性,模型的训练和评估。
Matplotlib库:可视化曲线或柱状图。
Graphviz库:可视化决策树。
Seaborn库:可视化混淆矩阵热力图。
五、实验步骤
1.数据处理与划分
(1)数据预处理
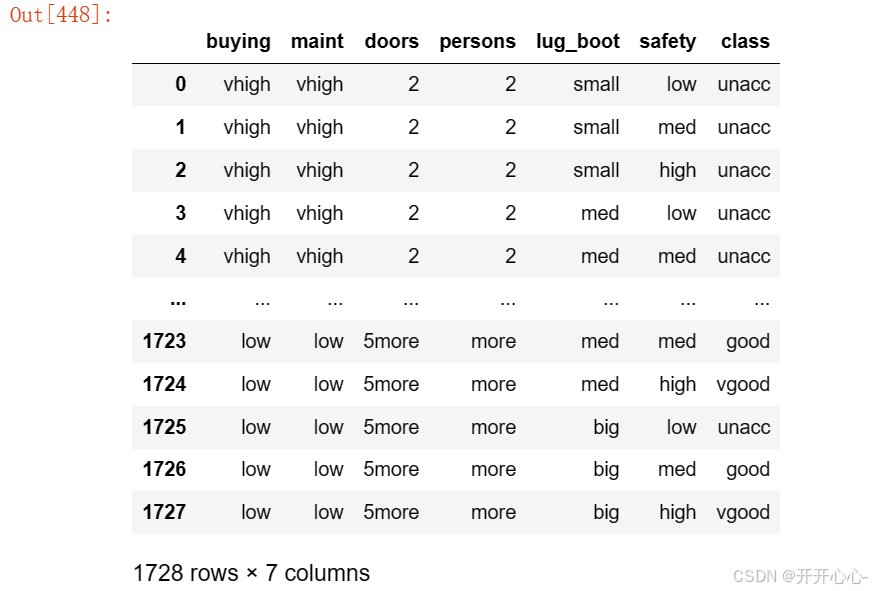
读取汽车评估数据集,并对数据集进行预处理,检查有无缺失值,为列加上对应属性和标签。
预处理后数据如下:
(2)数据处理
原始部分数据如下:

我们可以看到属性和标签类型均为object类型,这些字符串不能直接输入到机器学习模型中进行训练。为了能够对这些特征进行处理和分析,使用了preprocessing.LabelEncoder()来将字符串类型的特征转换为整数类型。将处理后的数据分别保存到属性集dataset_X和标签集dataset_y中。
处理后部分数据如下:

该数据集中的四种标签分别映射为四个数值:0(acc),1(good),2(unacc),3(vgood)。
(3)划分数据集
将数据集划分为训练集和测试集,用于模型训练和性能评估。在本次实验中一共有1728个数据,随机选取1382个作为训练集,346个数据作为测试集,比例为4:1。
2.决策树模型
(1)建立决策树模型
调用sklearn.tree库中的决策树分类器分别使用信息增益特征选择方法和基尼系数特征选择方法建立决策树模型并对训练集进行训练。
(2)信息增益可视化
信息增益特征选择决策树的构建原理就是根据信息增益确定划分属性,构建信息增益决策树模型时虽然直接调用了库函数,但了解每种属性的相对重要性还是很有必要的,因此计算了每个属性的信息增益值并进行了可视化。
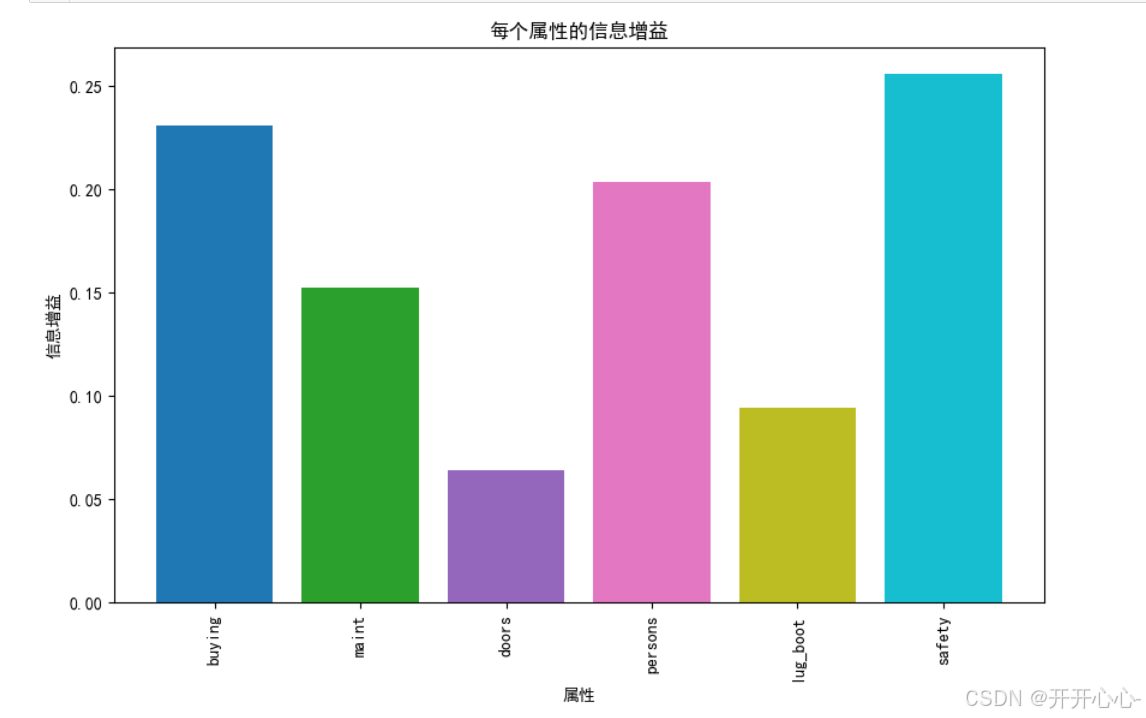
从图中我们可以看出安全性的信息增益最大,是人们最为关心的特征,其次就是该车的价格和可容纳人数,该划分属性形象的展示了人们对汽车性能评估的侧重方向。
(3)预测结果、正确率、混淆矩阵可视化
模型训练完成之后就要对测试集进行预测,数据处理时我们已经将数据集转换为数值,因此预测结果也应该是一个数值列表。两种模型分别进行可视化:

从图中可以看出两种模型的差别不大,只有极少数不同,接下来就是对两种模型的准确率进行预测:
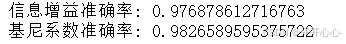
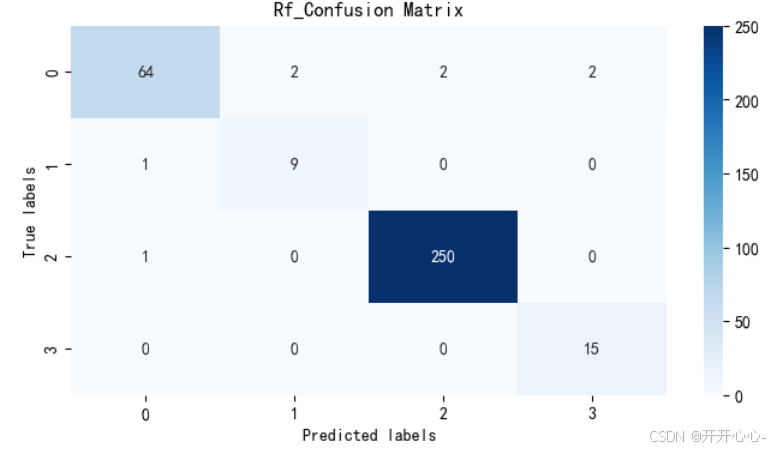
准确率也相差不大,为了更直观的显示预测值和真实值之间的差别,我们以热力图的形式分别对两种模型的混淆矩阵进行可视化:
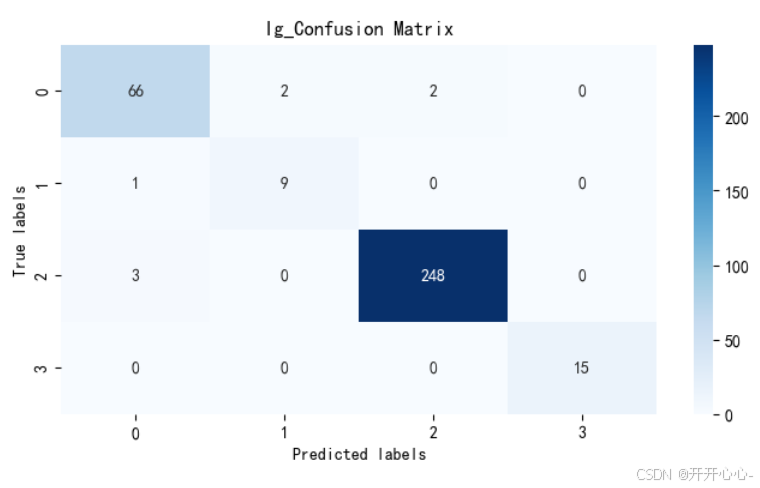
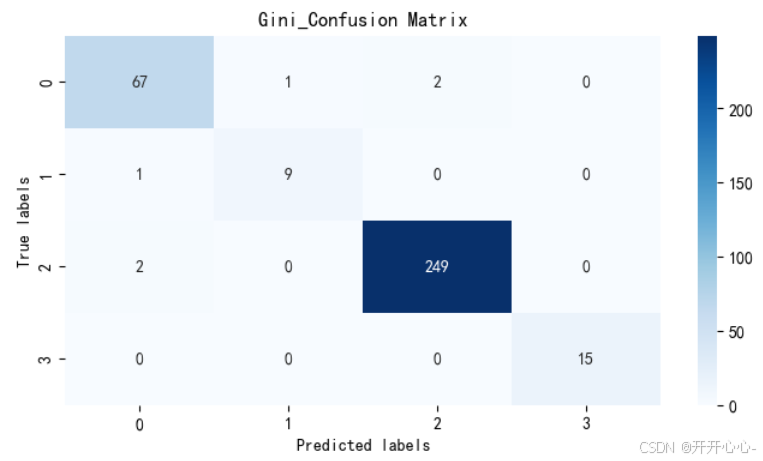
混淆矩阵主对角线上的元素为正确分类数量,通过混淆矩阵我们可以直观地了解模型的分类准确性,发现模型在哪些类别上容易出现错误,直观地比较不同分类方法的分类准确性和错误情况,但两种模型的差距很小。
3.随机森林模型
(1)建立随机森林模型
和建立决策树模型差不多调用sklearn.tree库中的随机森林分类器,起初不知道决策树的数量初始化为多少,随机取一个值,以100棵决策树为例建立随机森林模型,然后用训练集对模型进行训练。
(2)预测结果和特征重要性可视化
打印预测结果和准确率:

同样,随机森林模型也能得到较准确的预测,然后对结果进行更直观的可视化:
在使用信息增益构建决策树模型时我们对每个属性的信息增益进行了可视化,信息增益代表了每种属性的相对重要性,同理,在随机森林模型中,我们同样可以通过对特征的重要性进行可视化来帮助我们理解不同特征在随机森林模型中的重要性,有利于进一步的数据分析,特征重要性可视化如下:
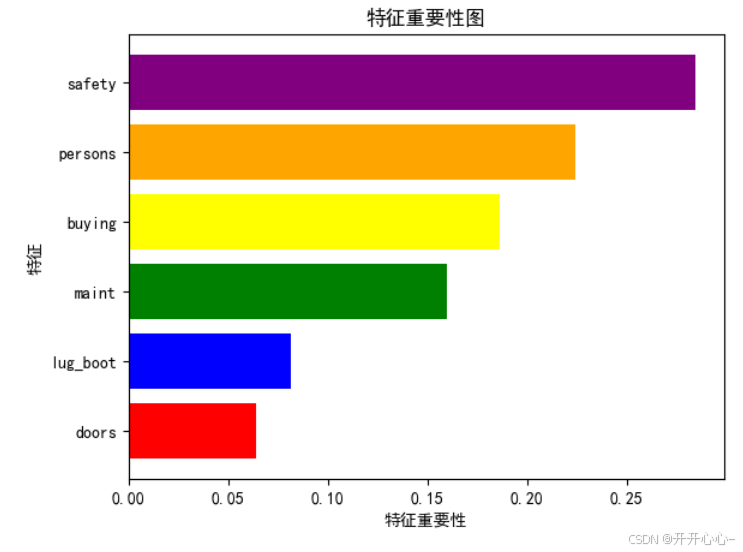
从图中我们可以看出安全不管在任何情况下都是最重要的特征,可容纳人数和购买价格紧随其后,这三大特征占所有特征的70%,而其他三个特征对于汽车性能的评估占比较少。
(3)林模型的进一步分析
起初我们构建随机森林模型时随机选取由100棵决策树构成的随机森林进行预测和评估,虽然也得到了比较好的效果,但也值得探讨对于不同决策树数量的随机森林模型效果又会如何呢,因此将决策树的数量变为一个列表,探讨决策树数量对预测效果的影响。
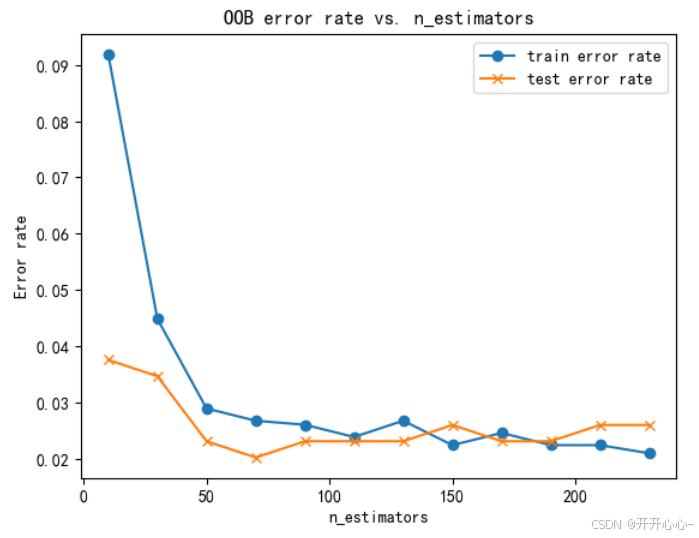
①OOB error rate vs.n_estimators
通过对决策树数量的改变来观察训练集和测试集(主要是测试集)错误率的影响,可视化效果如下:
②Accuracy vs. n_estimators
通过对决策树数量的改变来观察训练集和测试集(主要是测试集)正确率的影响,本质上和OOB error rate vs.n_estimators一样。
可视化效果如下:
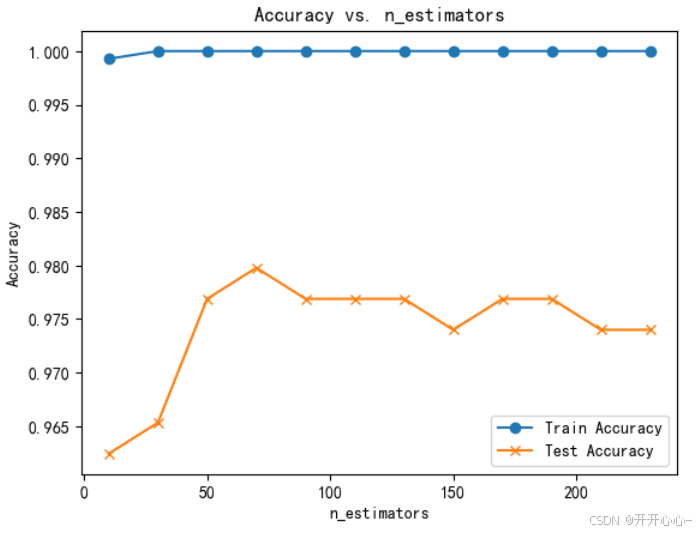
通过对这两种曲线的综合分析可以得出当决策树数量为70棵左右时,错误率最低,准确率最高,得到的效果最好,但由于原来模型的效果已经不错的情况下,优化后的效果和实际上和原来差别很小。
六、实验结果分析
通过比较信息增益决策树和基尼系数决策树对测试集的预测正确率,基尼系数决策树的正确率为98%,信息增益决策树的正确率为97%,虽然基尼系数正确率更高,但是效果都不错,但是由于细微差距我们可以选择基尼系数决策树作为最优模型。经过交叉验证和剪枝选择最优的决策树剪枝参数后,我们建立的信息增益决策树模型预测效果得到了提升,正确率达到了98%,基尼系数决策树没有提升,反而有时正确率降低,可能是由于过剪枝导致预测效果降低,但两种决策树均可以较为准确地预测汽车的等级。
通过信息增益决策树模型中信息增益值可视化和随机森林模型中特征值重要性的可视化中,我们发现“buying”和“safety”和“persons”是对预测汽车等级最重要的三个特征。这意味着,如果我们想要提高模型的准确性,重点应该放在这三个特征上,例如在数据预处理中对它们进行更精细的处理,由于已经取得较好效果,没有进一步处理。
通过绘制训练集错误率和测试集错误率 vs. n_estimators曲线以及训练集和测试集准确率vs. n_estimators曲线,我们观察到随着树的个数的增加,错误率先降低后提升然后逐渐稳定,准确率也是先提升再降低然后趋于稳定,在一定数量的决策树之后,随机森林模型不再获得显著的性能提升,我们可以通过比较正确率和错误率选择最佳决策树的数量,得到最优的随机森林模型。
综上所述,本次实验成功地建立了决策树和随机森林模型,并通过交叉验证和剪枝选择最优的模型参数,以获得更好的模型性能。通过比较特征重要性和模型性能变化,我们还深入了解了数据集的特征,并为其提供了更好的预测性能。
七、决策树的可视化与优化
1.决策树的可视化
通过调用graphviz对两种决策树分别进行可视化,并分别生成相应的pdf和png文件。
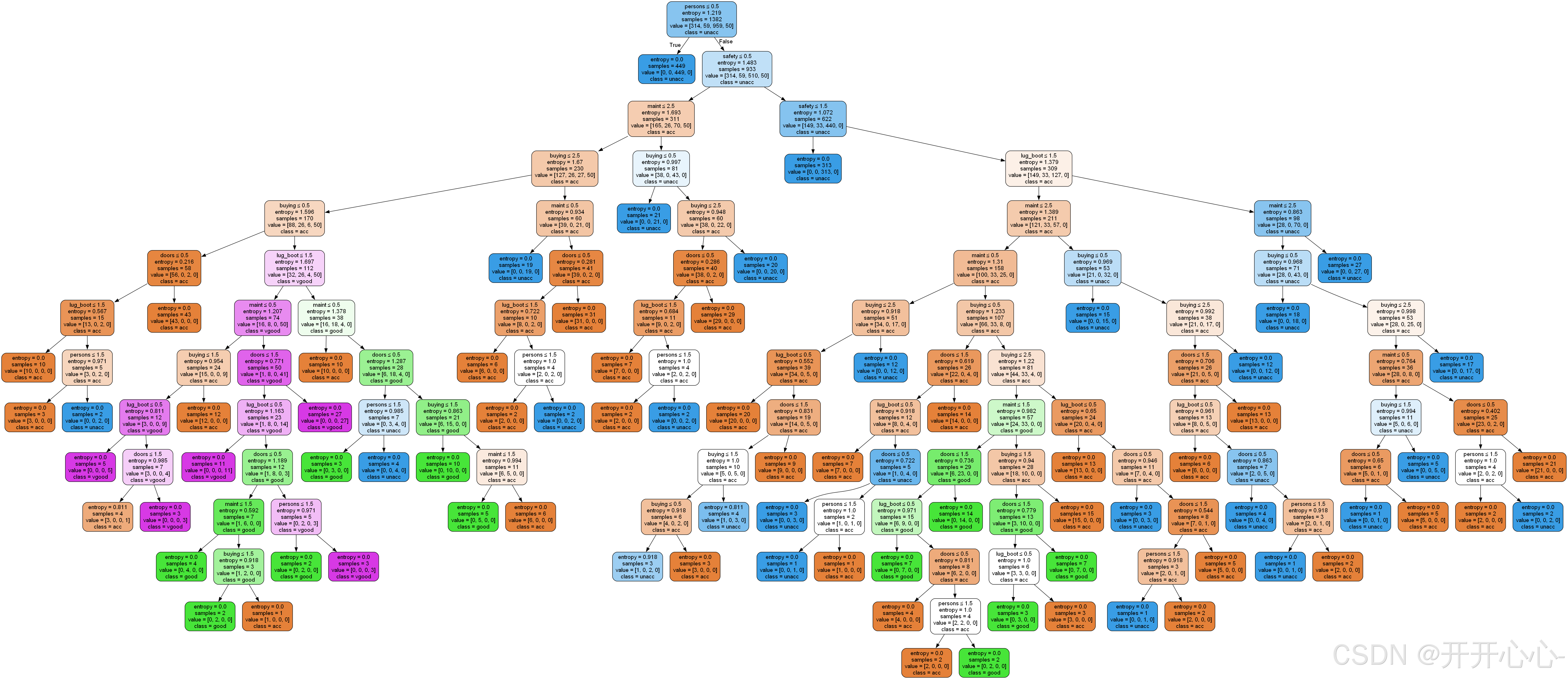
信息增益决策树可视化:
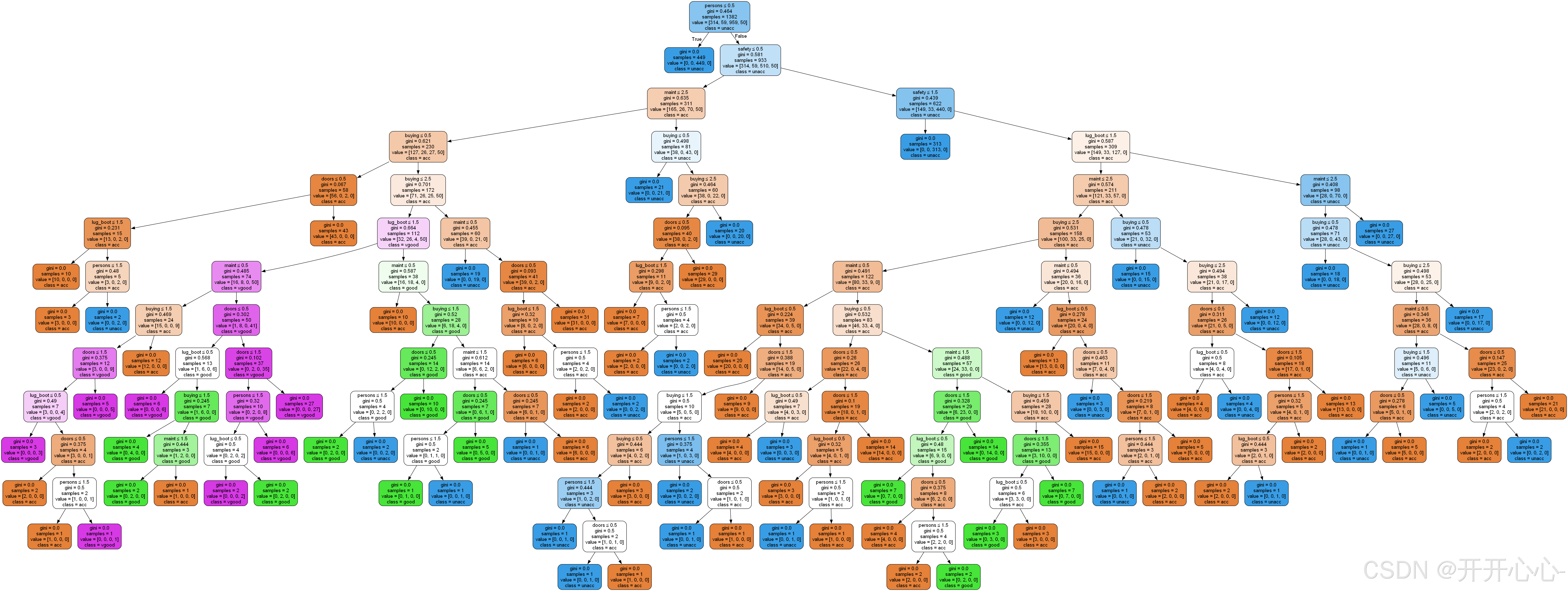
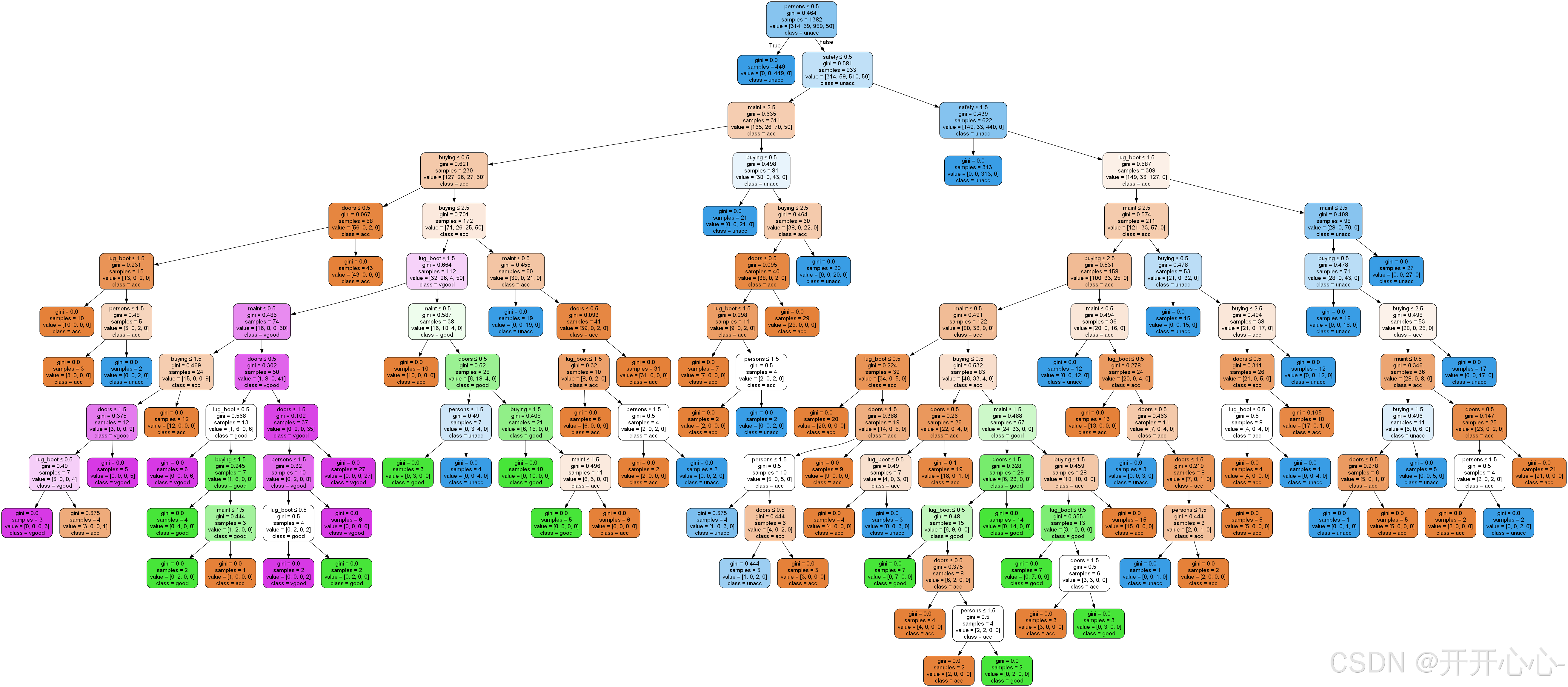
基尼系数决策树可视化:
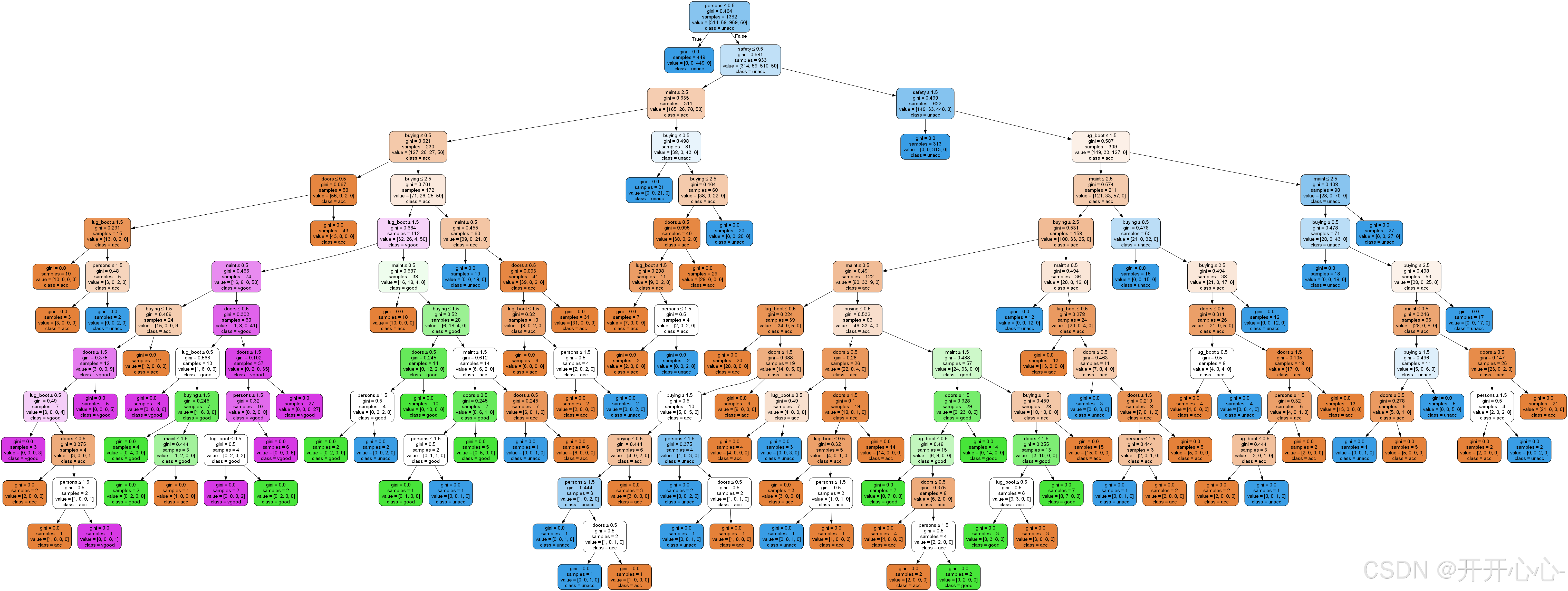
2.决策树剪枝
为了寻求最佳准确率,我们根据树的不同高度对预测效果进行可视化展示。通过交叉验证和剪枝方法,我们可以确定决策树的最佳剪枝参数。
信息增益决策树高度 vs 正确率:
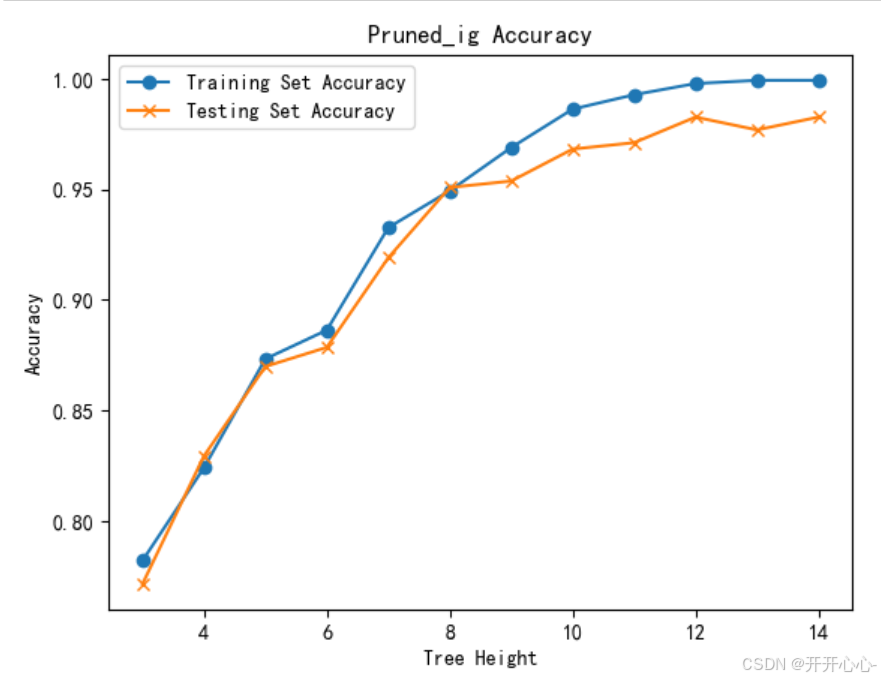
基尼系数决策树高度 vs 正确率:
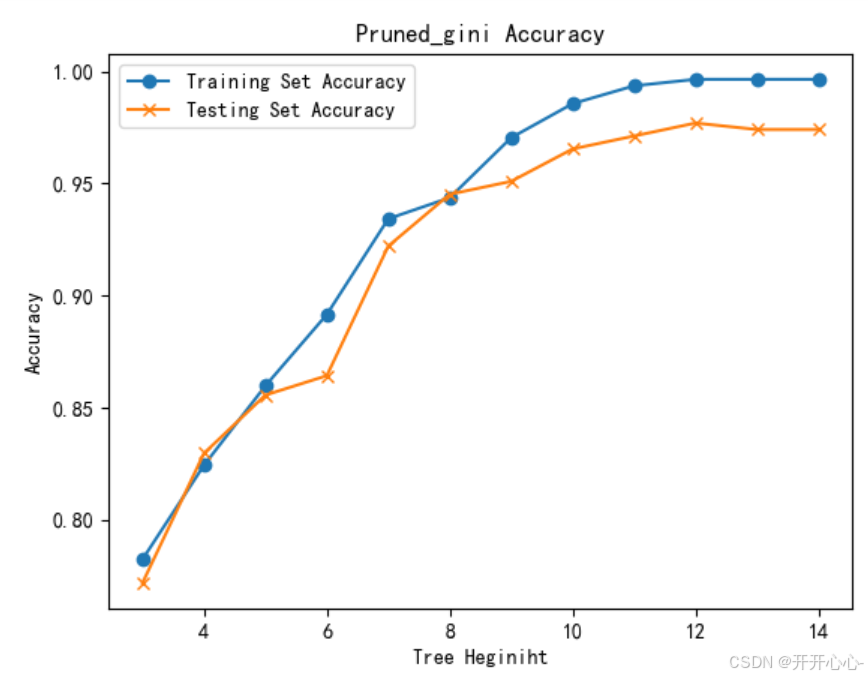
在每一个树的高度不同时我们确定不同的超参数ccp_alpha,最后选取预测效果最好的的参数,构建相应的决策树模型然后对决策树模型进行可视化。
剪枝后的信息增益可视化:
剪枝前后正确率对比:

剪枝后的基尼系数决策树可视化:
剪枝前后正确率对比:

综合上述结果我们可以看出剪枝后的决策树和原来相比略有简化,但由于原始决策树已经取得了比较好的效果,所以剪枝后正确率提升的也是微乎其微,有时甚至因为过度剪枝导致正确率还不如原始决策树。
八、全部源代码
# 导入库
import graphviz
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn import metrics
from sklearn.metrics import confusion_matrix
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier, export_graphviz
# 准备数据集
df=pd.read_csv("car.data",header=None)
# 数据预处理
# 检查有无缺失值
print(df.all().notnull())
# 为列加上对应属性和标签
df.columns = ["buying","maint","doors","persons","lug_boot","safety","class"]
#数据处理
# 数据集中的特征向量包括有多个String,故而type是object,需要转换为数值
raw_set=df.values
from sklearn import preprocessing
label_encoder=[]
encoded_set = np.empty(raw_set.shape)
for i,_ in enumerate(raw_set[0]):
encoder=preprocessing.LabelEncoder()
encoded_set[:,i]=encoder.fit_transform(raw_set[:,i])
print(encoder.classes_)
label_encoder.append(encoder)
dataset_X = encoded_set[:, :-1].astype(int)
dataset_y = encoded_set[:, -1].astype(int)
print(dataset_X[:5]) # 可以看出每个特征向量都将string转变为int
print(dataset_y[580:600]) # 检查没有问题
# 将数据集分为训练集和测试集
train_X, test_X, train_y, test_y = train_test_split(dataset_X, dataset_y, test_size=0.2, random_state=37)
#构建决策树模型
# 信息增益决策树模型
ig_model = DecisionTreeClassifier(criterion='entropy',random_state=37)
ig_model.fit(train_X, train_y)
# 基尼指数决策树模型
gini_model = DecisionTreeClassifier(criterion='gini',random_state=37)
gini_model.fit(train_X, train_y)
# 属性信息增益可视化
# 获取每个属性的信息增益
importances = ig_model.feature_importances_
# 生成颜色列表,长度与属性数量相同
num_features = len(feature_names)
colors = plt.get_cmap('tab10', num_features)
# 绘制条形图进行可视化
plt.figure(figsize=(10, 6))
for i, importance in enumerate(importances):
plt.bar(feature_names[i], importance, color=colors(i))
plt.xticks(rotation=90)
plt.rcParams["font.family"] = "SimHei"
plt.xlabel('属性')
plt.ylabel('信息增益')
plt.title('每个属性的信息增益')
plt.show()
# 进行预测
ig_predictions = ig_model.predict(test_X)
gini_predictions = gini_model.predict(test_X)
# 打印预测结果
print("信息增益预测结果:", ig_predictions)
print("基尼指数预测结果:", gini_predictions)
# 计算准确率
accuracy_ig = metrics.accuracy_score(test_y, ig_predictions)
accuracy_gini = metrics.accuracy_score(test_y, gini_predictions)
print("信息增益准确率:", accuracy_ig)
print("基尼系数准确率:", accuracy_gini)
#混淆矩阵
ig_confusion_mat = confusion_matrix(test_y, ig_predictions)
gini_confusion_mat=confusion_matrix(test_y, gini_predictions)
# 绘制信息增益混淆矩阵可视化
plt.figure(figsize=(8, 6))
sns.heatmap(ig_confusion_mat, fmt='d',annot=True, cmap="Blues")
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.title('Ig_Confusion Matrix')
plt.show()
# 绘制基尼系数混淆矩阵可视化
plt.figure(figsize=(8, 6))
sns.heatmap(gini_confusion_mat,fmt='d', annot=True, cmap="Blues")
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.title('Gini_Confusion Matrix')
plt.show()
# 生成信息增益决策树可视化
ig_dot_data = export_graphviz(ig_model, out_file=None, feature_names=df.columns[:-1], class_names=label_encoder[-1].classes_, filled=True, rounded=True, special_characters=True)
ig_graph = graphviz.Source(ig_dot_data)
ig_graph.render("ig_decision_tree", format="png", cleanup=True)
ig_graph.view()
# 生成基尼指数决策树可视化
gini_dot_data = export_graphviz(gini_model, out_file=None, feature_names=df.columns[:-1], class_names=label_encoder[-1].classes_, filled=True, rounded=True, special_characters=True)
gini_graph = graphviz.Source(gini_dot_data)
gini_graph.render("gini_decision_tree", format="png", cleanup=True)
gini_graph.view()
train_accuracy = []
test_accuracy = []
decision_tree_height=list(range(3,15))
ccp_alphas = []
# 训练不同高度使用信息增益的决策树,并获取对应的ccp_alpha
for i in decision_tree_height:
ig = DecisionTreeClassifier(criterion='entropy', max_depth=i)
ig.fit(train_X, train_y)
ccp_alphas.append(ig.cost_complexity_pruning_path(train_X, train_y)['ccp_alphas'])
# 针对每个高度计算训练精度和测试精度
for i, ccp_alphass in zip(decision_tree_height, ccp_alphas):
scores_alphas = []
for ccp_alphas in ccp_alphass:
ig = DecisionTreeClassifier(criterion='entropy', max_depth=i, ccp_alpha=ccp_alphas)
# 交叉验证计算性能指标
scores = cross_val_score(ig, train_X, train_y, cv=5)
scores_alphas.append(np.mean(scores))
# 寻找最优的ccp_alpha和对应的测试精度
max_score = max(score for score in scores_alphas if score >= (max(scores_alphas)-0.01))
best_alpha = ccp_alphass[scores_alphas.index(max_score)]
# 构造一棵修剪后的决策树,并计算对应的测试和训练精度
pruned_ig = DecisionTreeClassifier(criterion='entropy',max_depth = i,ccp_alpha=best_alpha)
pruned_ig.fit(train_X, train_y)
pruned_ig_train_pred = pruned_ig.predict(train_X)
pruned_ig_test_pred = pruned_ig.predict(test_X)
train_acc = np.mean(pruned_ig_train_pred == train_y)
test_acc = np.mean(pruned_ig_test_pred == test_y)
train_accuracy.append(train_acc)
test_accuracy.append(test_acc)
# 绘制训练和测试精度曲线
plt.plot(decision_tree_height, train_accuracy, label='Training Set Accuracy', marker='o')
plt.plot(decision_tree_height, test_accuracy, label='Testing Set Accuracy', marker='x')
plt.xlabel('Tree Height')
plt.ylabel('Accuracy')
plt.title('Pruned_ig Accuracy')
plt.legend()
plt.show()
# 生成信息增益决策树可视化
ig_dot_data = export_graphviz(pruned_ig, out_file=None, feature_names=df.columns[:-1], class_names=label_encoder[-1].classes_, filled=True, rounded=True, special_characters=True)
ig_graph = graphviz.Source(ig_dot_data)
ig_graph.render("cut_ig_decision_tree", format="png", cleanup=True)
ig_graph.view()
# 正确率预测
print("ig_Accuracy on the training set: {:.6f}".format(ig_model.score(train_X, train_y)))
print("ig_Accuracy on the test set: {:.6f}".format(ig_model.score(test_X, test_y)))
print("ig_Accuracy on the training set after cut: {:.6f}".format(pruned_ig.score(train_X, train_y)))
print("ig_Accuracy on the test set after cut: {:.6f}".format(pruned_ig.score(test_X, test_y)))
train_accuracy = []
test_accuracy = []
decision_tree_height = list(range(3,15))
ccp_alphas = []
# 训练不同高度使用基尼系数的决策树,并获取对应的ccp_alpha
for i in decision_tree_heights:
gini = DecisionTreeClassifier(criterion='gini', max_depth=i)
gini.fit(train_X, train_y)
ccp_alphas.append(gini.cost_complexity_pruning_path(train_X, train_y)['ccp_alphas'])
# 针对每个高度计算训练精度和测试精度
for i, ccp_alphas_i in zip(decision_tree_heights, ccp_alphas):
scores_alphas = []
for ccp_alpha in ccp_alphas_i:
gini = DecisionTreeClassifier(criterion='gini',max_depth=i, ccp_alpha=ccp_alpha)
# 交叉验证计算性能指标
scores = cross_val_score(gini, train_X, train_y, cv=5)
scores_alphas.append(np.mean(scores))
# 寻找最优的ccp_alpha和对应的测试精度
max_score = max(score for score in scores_alphas if score >= (max(scores_alphas)-0.01))
best_alpha = ccp_alphas_i[scores_alphas.index(max_score)]
# 构造一棵修剪后的决策树,并计算对应的测试和训练精度
pruned_gini = DecisionTreeClassifier(criterion='gini', max_depth = i,ccp_alpha=best_alpha)
pruned_gini.fit(train_X, train_y)
pruned_gini_train_pred = pruned_gini.predict(train_X)
pruned_gini_test_pred = pruned_gini.predict(test_X)
train_acc = np.mean(pruned_gini_train_pred == train_y)
test_acc = np.mean(pruned_gini_test_pred == test_y)
train_accuracy.append(train_acc)
test_accuracy.append(test_acc)
# 绘制训练和测试精度曲线
plt.plot(decision_tree_height, train_accuracy, label='Training Set Accuracy', marker='o')
plt.plot(decision_tree_height, test_accuracy, label='Testing Set Accuracy', marker='x')
plt.xlabel('Tree Heginiht')
plt.ylabel('Accuracy')
plt.title('Pruned_gini Accuracy')
plt.legend()
plt.show()
# 生成信息增益决策树可视化
ig_dot_data = export_graphviz(pruned_gini, out_file=None, feature_names=df.columns[:-1], class_names=label_encoder[-1].classes_, filled=True, rounded=True, special_characters=True)
ig_graph = graphviz.Source(ig_dot_data)
ig_graph.render("cut_gini_decision_tree", format="png", cleanup=True)
ig_graph.view()
# 正确率预测
print("gini_Accuracy on the training set: {:.6f}".format(gini_model.score(train_X, train_y)))
print("gini_Accuracy on the test set: {:.6f}".format(gini_model.score(test_X, test_y)))
print("gini_Accuracy on the training set after cut: {:.6f}".format(pruned_gini.score(train_X, train_y)))
print("gini_Accuracy on the test set after cut: {:.6f}".format(pruned_gini.score(test_X, test_y)))
cut_ig_predictions = pruned_gini.predict(test_X)
cut_gini_predictions = pruned_gini.predict(test_X)
cut_ig_confusion_mat = confusion_matrix(test_y, cut_ig_predictions)
cut_gini_confusion_mat=confusion_matrix(test_y, cut_gini_predictions)
# 绘制信息增益混淆矩阵可视化
plt.figure(figsize=(8, 6))
sns.heatmap(ig_confusion_mat, fmt='d',annot=True, cmap="Blues")
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.title('Cut_Ig_Confusion Matrix')
plt.show()
# 绘制基尼系数混淆矩阵可视化
plt.figure(figsize=(8, 6))
sns.heatmap(gini_confusion_mat,fmt='d', annot=True, cmap="Blues")
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.title('Cut_Gini_Confusion Matrix')
plt.show()
# 创建随机森林模型
rf_model = RandomForestClassifier(n_estimators=100,random_state=37)
rf_model.fit(train_X, train_y)
# 进行随机森林模型预测
rf_predictions = rf_model.predict(test_X)
# 打印随机森林模型预测结果
print("随机森林预测结果:", rf_predictions)
accuracy_rf = metrics.accuracy_score(test_y,rf_predictions)
print("随机森林准确率:", accuracy_rf)
rf_confusion_mat=confusion_matrix(test_y, rf_predictions)
# 绘制随机森林混淆矩阵可视化
plt.figure(figsize=(8, 6))
sns.heatmap(rf_confusion_mat, fmt='d',annot=True, cmap="Blues")
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.title('Rf_Confusion Matrix')
plt.show()
feature_names = ["buying","maint","doors","persons","lug_boot","safety"]
# 获取特征重要性
feature_importances = rf_model.feature_importances_
# 将特征重要性排序
sorted_idx = np.argsort(feature_importances)
colors = ["red", "blue", "green", "yellow", "orange", "purple"]
plt.barh(range(len(feature_importances)), feature_importances[sorted_idx], color=colors)
plt.yticks(range(len(feature_importances)), np.array(feature_names)[sorted_idx])
plt.rcParams["font.family"] = "SimHei"
plt.xlabel("特征重要性")
plt.ylabel("特征")
plt.title("特征重要性图")
plt.show()
# 定义n_estimators范围
n_estimators_range = range(10, 250, 20)
# 存储OOB错误率和测试集错误率
train_errors = []
test_errors = []
# 训练随机森林并计算OOB错误率和测试集错误率
for n_estimators in n_estimators_range:
rf_model = RandomForestClassifier(n_estimators=n_estimators, oob_score=True, random_state=37)
rf_model.fit(train_X, train_y)
train_error = 1 - rf_model.oob_score_
test_error = 1 - rf_model.score(test_X, test_y)
train_errors.append(train_error)
test_errors.append(test_error)
print(f"训练集错误率:{train_error}")
print(f"测试集错误率:{test_error}")
# 绘制训练集错误率和测试集错误率 vs. n_estimators曲线
plt.plot(n_estimators_range, train_errors, label="train error rate",marker='o')
plt.plot(n_estimators_range, test_errors, label="test error rate",marker='x')
plt.xlabel("n_estimators")
plt.ylabel("Error rate")
plt.title("OOB error rate vs. n_estimators")
plt.legend()
plt.show()
# 初始化 n_estimators 值列表和准确率列表
n_estimators_values = list(range(10,250,20))
train_accuracies = []
test_accuracies = []
# 构建随机森林模型,并在不同的 n_estimators 值下进行训练和评估
for n_estimators in n_estimators_values:
model = RandomForestClassifier(n_estimators=n_estimators, random_state=37)
model.fit(train_X, train_y)
train_predictions = model.predict(train_X)
test_predictions = model.predict(test_X)
train_accuracy = accuracy_score(train_y, train_predictions)
test_accuracy = accuracy_score(test_y, test_predictions)
train_accuracies.append(train_accuracy)
test_accuracies.append(test_accuracy)
print(f"训练集正确率:{train_accuracy}")
print(f"测试集正确率:{test_accuracy}")
# 绘制训练集和测试集准确率VSn_estimators曲线
plt.plot(n_estimators_values, train_accuracies, label='Train Accuracy',marker='o')
plt.plot(n_estimators_values, test_accuracies, label='Test Accuracy',marker='x')
plt.xlabel('n_estimators')
plt.ylabel('Accuracy')
plt.title('Accuracy vs. n_estimators')
plt.legend()
plt.show()至此,我们对基于决策树的汽车性能评估有了深入的了解。虽然决策树是传统的机器学习技术,但它在汽车性能评估这个复杂的任务中展现出了独特的魅力。它以一种相对简单却有效的方式处理汽车性能相关的数据,为汽车行业的各个环节提供了有价值的参考。
尽管如今有许多新兴的机器学习技术不断吸引着人们的目光,但决策树凭借其易于理解、可解释性强等优点,在汽车性能评估领域依然占据着一席之地。随着技术的不断发展,决策树或许还能与其他技术相结合,进一步提升汽车性能评估的准确性和效率,继续为汽车工业的发展贡献自己的力量。


















 5104
5104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









