






1.项目背景介绍
1.1背景
目前大多数油田的开采进入中后期,开采难度及成本上升,抽油机、抽油杆、抽油泵组合是最主要的开采装备,对抽油泵的可靠性要求也越来越高。油井下情况复杂多变,因此抽油泵在运行过程中会发生故障。示功图是抽油系统故障诊断中的最主要的依据,示功图反映了抽油泵的工况,通过分析示功图特征,可以判断抽油泵是否存在故障。快速准确地利用示功图诊断出抽油泵故障,这将会极大提高石油的产量、开采效率,对保障油田生产有着重要意义。
抽油泵的故障诊断是通过传感器收集抽油机悬点的载荷及位移数据,制出示功图,对示功图的特征进行判断,诊断出抽油泵故障并及时进行修复。
1.2示功图故障分类及其出现原因
1.2.1示功图种类
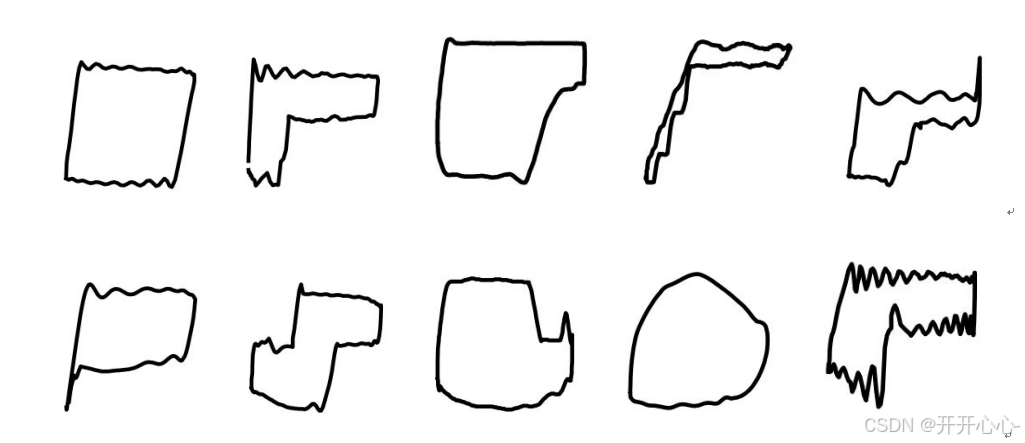
本文一共研究了十种示功图,为了便于分类,分别命名为A01-A10,下面我们选取部分示功图进行具体分析故障原因。
1.2.2示功图分析
理论示功图:

理论示功图是光杆只承受抽油杆柱与活塞截面积以上液柱的静载荷时,理论上所得到的示功图,它需要满足以下假设:深井泵质量合格,工作正常;不考虑活塞在上、下冲程中,抽油杆柱所受到的摩擦力、惯性力、振动载荷与冲击载荷等的影响,假设力在抽油杆柱中传递是瞬时的,凡尔的起落也是瞬时的;抽油设备在工作过程中,不受砂、蜡、水、气等因素的影响,认为进入泵内的液体不可压缩;油井没有连抽带喷现象;油层供油能力充足,泵能够完全充满。
深井泵的活塞在做往复运动。活塞在最低位置时,两个凡尔之间有一余隙,充满了液体。当活塞下行程快接近死点时,固定凡尔关闭,游动凡尔打开,活塞上下液体连通,光杆上只承受抽油杆柱在油中的重量;油管承受了全部液柱重量。
当活塞开始上行程的瞬间,游动凡尔立即关闭,使活塞上下不连通。液柱的重量加在活塞上,并经过抽油杆加在光杆上(光杆此时还承受抽油杆柱在油中的重量)。油管此时只承受它与活塞之间环形截面上液柱的重量。在下死点前后,抽油杆柱上多了一个活塞截面以上液柱的重量,油管上少了一个活塞截面以上液柱的重量。这时,就要发生弹性变形,油管就要缩短,抽油杆就要伸长(细长的油管和抽油杆柱,本身是一个弹性体,在负荷变化时,就产生相应的变形,此变形的多少和负荷变化的多少成正比)此时,光杆虽然在上移,但活塞相应于泵筒来说,实际未动,这样,就画出了图1-1中AB斜直线。AB线表示了光杆负载增加的过程,称为增载线。
当弹性变形完毕光杆带动活塞开始上行(B点),固定凡尔打开,液体进入泵筒并充满活塞所让出的泵筒空间,此时,光杆处所承受的负荷,仍和B点时一样没有变化,所以,画出一条直线BC。
当活塞到达上死点,在转入下行程的瞬间,固定凡尔关闭,游动凡尔打开,活塞上下连通。活塞上原所承受的液柱重量又加在油管上。抽油杆卸掉了这一载荷,油管上加上了这一载荷,于是,这二者又发生弹性变形,此时,油管伸长,抽油杆柱缩短,光杆下行,活塞相对于泵筒没有移动,于是画出了CD斜线。CD斜线表示了光杆上负荷减少的过程,称为减载线。
当弹性变形完毕,活塞开始下行,液体就通过游动凡尔向活塞以上转移,在液体向活塞以上转移的过程中,光杆上所受的负荷不变,所以画出一条和BC平行的直线DC。
当光杆行到下死点,在下行程完毕又将开始的瞬间,游动凡尔关闭,负荷又发生转移,开始了一个新的往复,这样,就画成了一个封闭的曲线,我们叫它做示功图。
示功图表示了光杆受力情况和位置的关系,也就是泵的工作状况和位置的关系。理想条件下的示功图具有平行四边形的模样。
正常示功图:

该图形与理论图形差异较小,近似为平行四边形。且增、减载线,上、下行程线均与理论线平行。由于设备振动而引起上、下负荷线有波纹。同时有些图形因泵挂较深、冲数较大产生的惯性力影响,使示功图沿着顺时针方向产生偏转,图形与基线有一夹角。
供液不足:

在泵体活塞向下运动的过程中,泵体内部液体液位较低,没有产生足够的向上应力,不足以抵消游动凡尔受到的重力作用,活塞下行时撞击到液面,在液体推动下凡尔发生唯一此时光杆会突然失去载荷,该图的增载情况是正常的,光杆突然失去载荷后,卸载滞后。
在一般情况下,示功图中增载线应与卸载线处于相互平衡的位置。如果示功图中卸载线存在明显的向左位移现象,说明泵体内部液位较低,导致光杆出现卸载滞后的现象,可以认定为该并存在供液不足的问题,属于典型的供液差示功图,基本没有沉没度,抽油泵工作异常或工作效率严重降低。
抽油泵出现液位不足时,活塞在上行过程中,由于液位较低,液体吸入量十分有限,活塞在做下行运动时需要触底位置才可以接触到液面,如前文所述光杆会出现突然卸载的问题,活塞在短暂接触液面后马上会进行上行运动,导致上行携夜能力进一步下降逐步形成恶性循环导致泵效降低。
气锁:
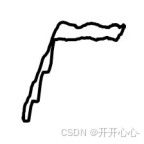
气锁是常见的抽油泵故障之一。抽油泵伴随使用年限的不断增加,在机械磨损以及腐蚀因素的作用下,抽油泵柱塞以及泵桶间隙不断加大,密封效果逐渐降低。活塞在上行过程中井内混合气体会通过柱塞和泵桶间隙不断进入泵桶内部,对活塞产生一个垂直向上的应力,当上行带入气体含量完全方满泵体内部空间以后,游动凡尔在关闭时受到的阻力增加不能及时关闭,上行载荷不能达到理论类值,上行增载速度显著降低。
在活塞下行运动时,活塞作用于井筒内部空间,让空间内气体发生压缩压力逐步增加,压缩气体产生的压力大于上液柱压力时,游动凡尔才可以被打开。因此,在光杆卸载缓慢时,示功图的卸载线一般为弯曲弧线,曲线的曲率与油并的油气比值呈正相关关系,可以认为,卸载曲线的曲率越大,抽油泵的工作效率越低。
气体充不满影响:

此图为高气油比井特征。气油比越高,圆弧的曲率半径越大,则表明油套管环空内有泡沫段存在,沉没压力偏小,充满不好。卸载时泵筒内气体受压缩卸载变缓,当气体压缩到一定程度,顶开游动凡尔时完成卸载。对受气体影响较大的井或易发生气锁的井应尽可能加深泵挂,增大泵的沉没度,大泵径长冲程机抽,特别是防冲距要调到最小,尽量减小余隙体积;下高效气锚和防气泵,合理放套气,控制套压生产,使之保持在较低值。
油稠:

此图的上、下行曲线呈凸状。原因为油稠,上下行程流动阻力增加。上行程时,流动阻力的方向向下,使悬点载荷增加;下行程时,流动阻力的方向向上,使悬点载荷减小。
2.相关技术介绍
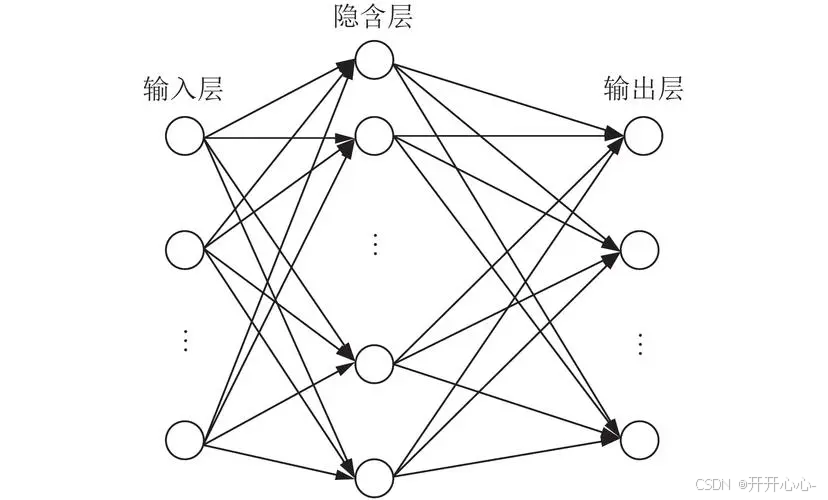
2.1卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN)是一种常用于图像识别、语音识别等领域的深度学习模型。CNN的核心思想是通过卷积操作来提取图像等数据的特征,从而实现对数据的分类、识别等任务。
总体结构如下图:
2.1.1输入层
输入层是网络接收数据的地方。对于图像数据,输入层通常由像素值组成的二维数组构成,每个像素值表示图像中的特定位置的亮度或颜色信息。
每个输入层的节点对应于图像中的一个像素。对于彩色图像,可能会有多个通道(如RGB),因此每个像素可能具有多个值。
输入层的任务是将原始数据传递给网络的下一层,通常是隐含层。
2.1.2隐含层
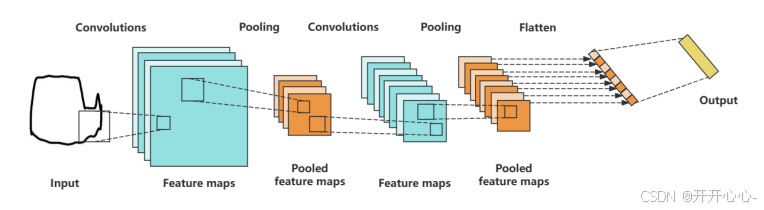
隐含层是卷积神经网络的核心部分,负责学习数据的特征。在卷积神经网络中,隐含层通常由多个卷积层、池化层和全连接层组成。下图为学习数据的过程图:
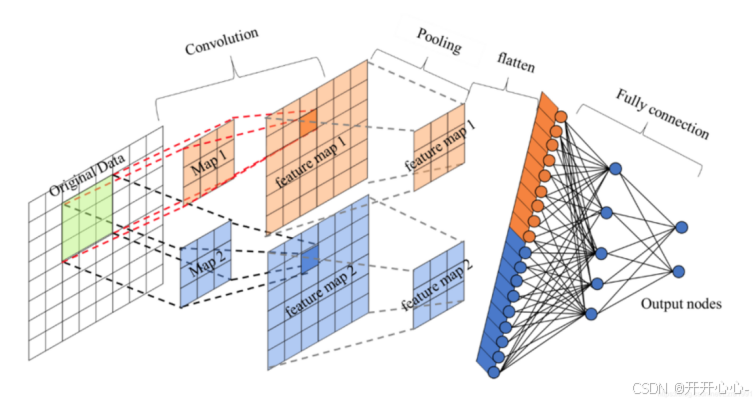
①卷积层(Convolutional Layers)
卷积层用于从图像中提取特征,它通过将一组卷积核与输入图像进行卷积操作来获取特征图。卷积核可以看作是一种滤波器,通过滑动在图像上进行卷积操作,可以识别出不同的特征,如边缘、纹理等。每个卷积核都会生成一个对应的特征图,这些特征图会捕捉到不同位置的相似特征。
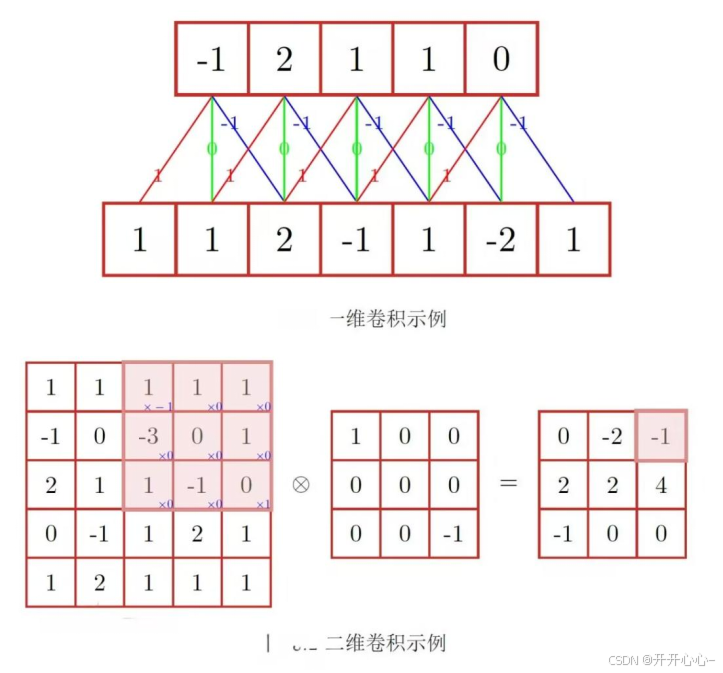
卷积层由多个卷积核构成,卷积核通常是一个比输入更小的、可学习的参数矩阵。卷积核在工作时,会对输入数据的每个局部区域进行卷积运算,即将卷积核的各个权重参数和它在图像上覆盖区域对应位置的元素进行加权求和,从而得到输出像素值,这个像素值就代表该局部区域的特征;接着卷积核会沿着输入数据的某个方向移动一定的距离,重复卷积运算,直到遍历完输入数据的所有局部区域;最后将每个局部区域的像素值进行拼接形成一个特征图。卷积具体工作示意图如图所示:
②激活函数
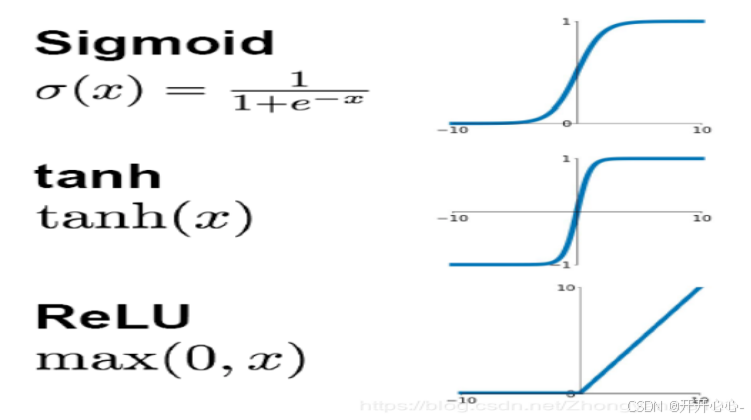
在诸如图像分类、目标检测等多种实际任务中,数据往往都是非线性的,在没有激活函数的情况下,网络的每一层都只是对输入进行线性变换,此时整个网络就会退化成一个单层的线性模型,无法学习非线性的模式和特征。激活函数存在的目的是在网络各层之间引入非线性特性,使得卷积神经网络具备解决非线性问题的能力。常见的激活函数包括Sigmoid函数、tanh函数以及Relu函数。
③池化层(Pooling Layers)
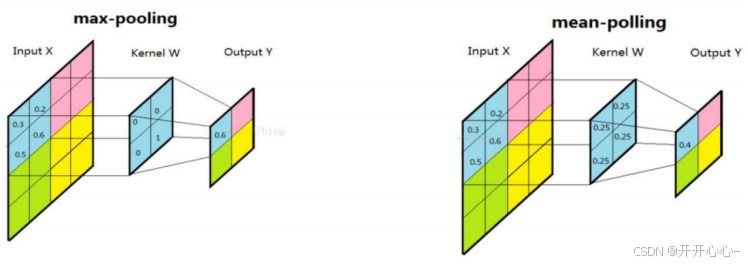
池化层(下采样层)用于降低特征图的空间大小和参数数量,从而减少计算量。最常见的池化操作是最大池化和平均池化,最大池化选择每个区域中的最大值作为输出 ,而平均池化选择每个区域中的平均值作为输出。最大池化能够提取出图像的主要特征,平均池化能够提取处图像的整体特征 ,同时两种池化操作均具备一定的平移和旋转不变性。
④全连接层(Fully Connected Layers)
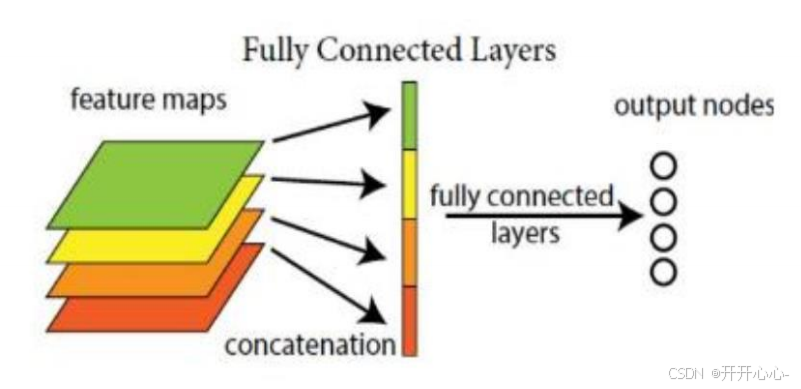
在卷积层和池化层之后,通常会使用全连接层进行分类。全连接层将卷积层和池化层提取的特征转换为网络最终输出的形式,每个神经元与前一层的所有神经元连接,全连接层将特征图展平为一维向量,并通过多个全连接层进行映射和分类。最后一层通过激活函数进行非线性变换,一般使用softmax函数将输出转换为概率分布,表示输入图像属于每个类别的概率。
2.1.3输出层
输出层是网络的最后一层,负责生成网络的预测结果。输出层的配置取决于具体的任务。例如,在分类任务中,输出层通常是一个包含类别数量相同数量的节点的全连接层,并使用softmax函数将网络输出转换为每个类别的概率分布。而在回归任务中,输出层通常只有一个节点,输出预测的连续值。
2.2模型优化
2.2.1优化器
在实验中,通过调整优化器和学习率等参数,可以进一步优化模型的训练效果。优化器是训练神经网络时使用的算法,用于自适应地调整模型中的参数,以减小损失函数的值。常见的优化器包括RMSprop、SGD、Nadam和Adam。不同的优化器具有不同的优化策略,如动量、学习率衰减等。下面是这些优化器的具体介绍:
①RMSprop(Root Mean Square Propagation):RMSprop是一种自适应学习率优化算法,通过考虑最近梯度的平方平均来调整学习率。它可以解决标准梯度下降算法中学习率设置不合理的问题,并减少参数更新的方差。RMSprop具有一种保守的更新策略,能更好地适应不同维度的梯度变化。
②SGD(Stochastic Gradient Descent):SGD是一种基本的优化算法,它在每次迭代中随机选择一个样本进行梯度计算和参数更新。SGD的优势是计算简单、易于理解,但由于每次只使用一个样本进行更新,可能会导致参数更新的方向不稳定,使优化过程较慢。
③Nadam(Nesterov Accelerated Adaptive Moment Estimation):Nadam是一种整合了Nesterov动量(Nesterov Momentum)和Adam算法的优化算法。Nadam通过引入动量的思想,在更新参数时考虑了之前的动量信息,并结合Adam的自适应学习率方式。Nadam能够在处理非凸问题时更快地收敛,并具有较好的泛化性能。
④Adam(Adaptive Moment Estimation):Adam是一种自适应学习率优化算法,结合了Momentum和RMSprop的优点。Adam算法使用了一阶和二阶矩估计来自适应地调整学习率,能够更好地适应不同参数的梯度变化,并在训练过程中保持较低的学习率。Adam通常被认为是一种有效的优化算法,广泛应用于深度学习中。
2.2.2学习率
学习率是指每次参数更新时的调整幅度,它决定了模型在训练过程中的收敛速度和最终准确性。较小的学习率可能导致收敛速度慢,而较大的学习率可能导致模型无法收敛或在最优点附近震荡。因此,在实验中,通过尝试不同的学习率,可以找到最适合的学习率,以获得更好的模型性能。
在实验中,我们可以观察训练集和验证集的准确率和损失函数随轮次的变化情况,以评估模型的性能和训练效果。通过调整优化器和学习率等参数,可以进一步改善模型的准确性和泛化能力,提高对图片的分类效果。
3.项目实施过程
3.1数据处理与分析
统计数据集中的图片数量,一共有6564张示功图,然后再把数据集按照7:3的比例将图片分为训练集和测试集并打印分配结果和信息,对于前4596个图片,将其复制到训练集文件夹中,对于接下来的1968个文件,将其复制到测试集文件夹中。

接着将图像像素值缩放到[0,1]的范围内,将所有图像调整为150*150像素,指定批量大小为32,生成器返回的数据包括图像和对应的独热编码标签,用于训练和测试。

3.2卷积神经网络
3.2.1构建卷积神经网络
我们采用Keras深度学习框架搭建模型,构建了三个卷积层,三个池化层,一个展平层,两个全连接层,其中,卷积层和池化层用于提取特征,展平层为了方便连接全连接层,Relu激活函数和Sigmoid激活函数用于增加非线性性,全连接层用于输出预测结果。该卷积神经网络结构及该模型的具体参数如下:


由于每一层的结点数都非常多,因此我们以训练集中的一张图片为例,输入模型后经过第一个卷积层后得到的部分输出进行了可视化:

下面是图片输入后经过卷积神经网络学习的部分过程,因为步骤较长,所以中间省略了部分卷积层和池化层。
3.2.2训练卷积神经网络
在训练之前我们设置神经网络模型的编译参数,主要包括损失函数、优化器和评估指标。因为示功图分类为多分类任务,因此我们选择的是交叉熵损失函数,优化器随机选择的是SGD优化器,学习率设置为1e-2。对图像进行预处理,所有图像将按1/255重新缩放,对图像的大小(150x150),每个批次的图像数(32)和类别的模式进行设定,并创建了训练数据生成器和验证数据生成器,然后训练模型,训练了10轮。然后对训练集和验证集的正确率和损失进行了可视化:
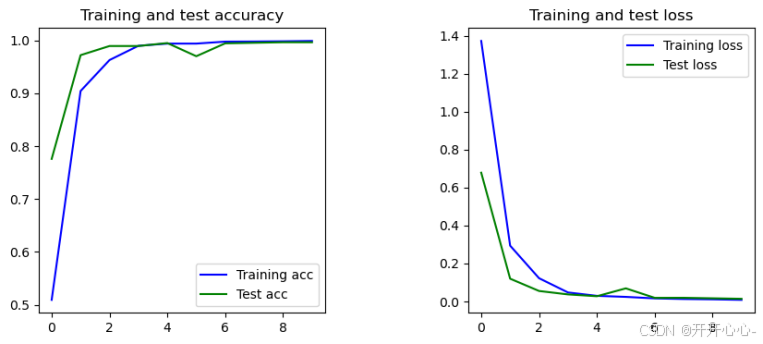
从图中我们可以看出仅仅训练十轮,训练集和测试集的正确率均达到了较高水平,训练集的最高正确率达到了99.89%,测试集的最高正确率达到了99.64%,说明了数据集的特征清晰明确,具有很明显的特征,这些特征能够被神经网络很容易地学习到,也说明了卷积神经网络的优势。
3.3调整参数
实验正确率不仅与数据集有关,更与模型有关,而卷积神经网络模型更是有很多决定因素比如网络的架构、优化器的选择、学习率等超参数的选择等等,是不是所有情况下都有很好的分类效果呢,接下来我们从优化器的选择和学习率的调整两个方面入手来探究这一问题。
3.3.1优化器
我们选择不同的优化器训练模型,包括RMSprop、SGD、Nadam和Adam,因为数据集特征较明显,训练较少次数时便达到了很高的正确率,因此为了节约时间和内存,我们均训练10轮,此时的学习率均为1e-3,观察各优化器的性能。
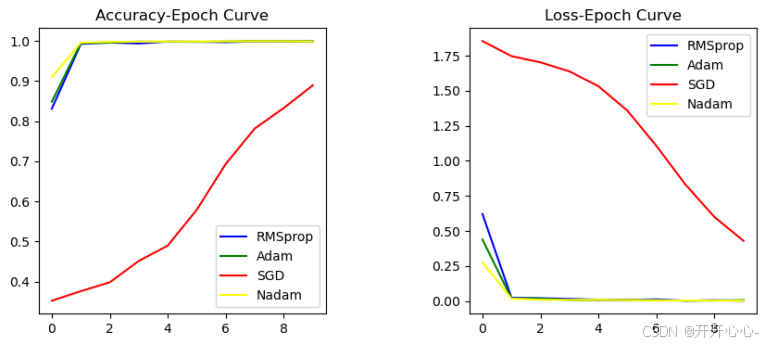
从图中我们可以看出当学习率均为0.001,使用SGD优化器时,随着训练次数的增多正确率逐渐增大,训练10轮后正确率达到了88.93%,当训练轮数增多时,正确率可能继续增大,但是对比其它三个优化器,SGD优化器的收敛速度非常慢,这也与它本身只能更新一个样本有关,造成了更新方向的不确定,进而减缓了收敛速度,RMSprop、Adam、Ndam的正确率在后期基本重合,最高正确率均达到了99.7%以上,说明识别效果很好,但是从前期来看,Nadam优化器还是略胜一筹。
3.3.2学习率
探究完优化器,接下来我们来探究学习率对实验结果的影响,我们选用了四个常用的学习率,均用最优的Nadam优化器进行训练,每次扩大10倍,可视化如下:

从图中我们可以看出当学习率为1e-3时模型的泛化性能最好,验证集正确率最高达到了99.80%。而步长为1e-1时正确率只有35.87%,模型的预测效果非常差。说明模型的正确率与学习率这个超参数也息息相关。
4.实现效果展示
下图为使用SGD优化器,学习率为0.01时训练时的正确率:
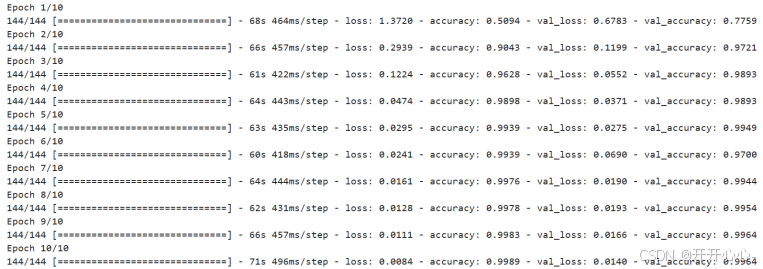
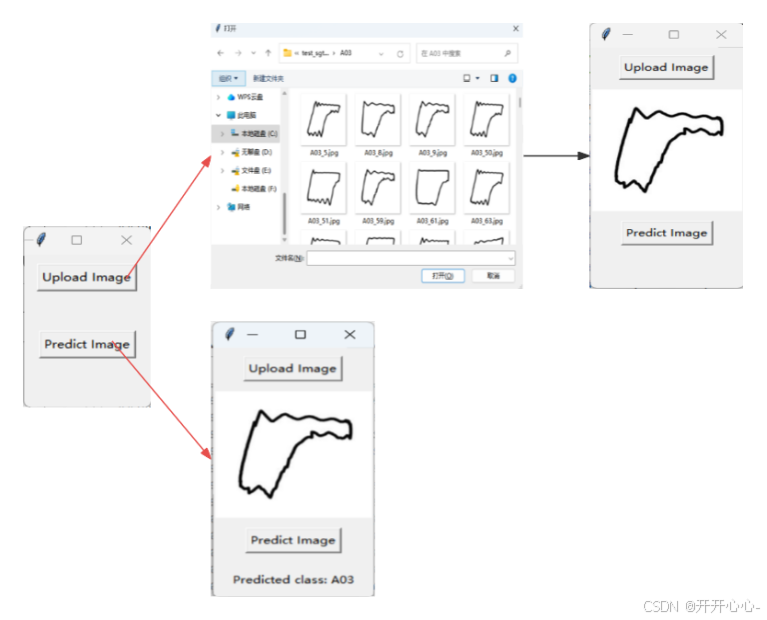
我们上传图片并对图片进行处理,经过模型预测会输出相应的示功图类型

为了更方便观察对示功图的故障诊断情况,我们使用tkinter库创建了一个简单的图形用户界面,可以上传图像文件,然后使用预训练的深度学习模型对图像进行分类,并在界面上显示出预测结果。
5.总结
本次实验我们利用卷积神经网络对抽油机示功图进行了分类,并探究了优化器和学习率对实验结果的影响,具体的结论如下:
5.1优化器的选择
在本次实验中,我们尝试了不同的优化器,包括RMSprop、SGD、Nadam和Adam。结果显示,Nadam优化器在测试集上达到了最好的性能,测试集正确率达到了99.7%。而SGD优化器表现最差,测试集正确率只有88.9%。这说明不同的优化器对模型的性能有较大影响,Nadam是一种结合了Nesterov动量和Adam优化器的优化算法。相比于SGD优化器,Nadam具有更快的收敛速度和更好的稳定性。因此,通常在训练深度神经网络时,Nadam优化器可以帮助模型更快地达到更好的性能,选择合适的优化器可以提高模型在测试集上的准确率。
5.2学习率的选择
我们进一步分析了不同的学习率对模型性能的影响。通过尝试4个不同的学习率(1e-4、1e-3、1e-2、1e-1),发现最优的学习率是1e-3,模型在测试集上的正确率达到了99.8%左右。但当学习率为1e-1时,模型的测试集正确率一直在35.8%附近震荡。这表明较大的学习率可能导致模型在参数空间中跳跃过大,进而导致模型无法充分学习,无法有效地收敛到全局最优解或降低训练误差,从而影响了模型在测试集上的准确性。而较小的学习率可能会导致收敛速度过慢,在有限的训练时间内无法充分收敛,导致准确率较低。因此选择合适的学习率,对模型在训练过程中平衡收敛速度和性能表现具有重要作用。
通过探究优化器和学习率对实验结果的影响,我们成功实现了对抽油机示功图故障诊断模型的优化。但是示功图故障诊断目前仍存在诸多挑战:在某种特定的工作条件下,几种故障的示功图特征非常相似,诊断模型容易把故障判断混淆,仅凭一张示功图难以诊断;面对多故障耦合时,多种因素同时影响示功图,信号数据间发生交互,变成多维数据,因为耦合情况下的训练数据多样性与复杂性存在不足,因此许多方法诊断多故障耦合不准确,这也对示功图故障诊断技术提出了更高的要求。模型优化是一个复杂的过程,需要综合考虑多个因素的影响。在未来的研究中,可以继续探索其他优化方法,以进一步提高模型的性能和泛化能力。


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









