








平均


前文介绍的TD算法很基础,只能求得给定策略的state value。
不能求得action value。
也不能寻找到最优策略。
2.
首先,对贝尔曼方程新的表述方式,对确定策略Π的state value定义如(4)

G是折扣回报,可以写成这样:
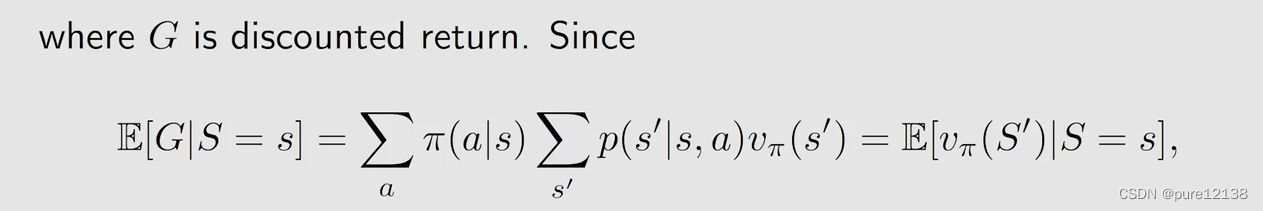
其中,S‘是下一时刻的state,重写上式则(5)

第二步,用RM算法求解贝尔曼方程。定义如下的解就是

由于我们只能采样r和s’,则

因此,RM算法:

RM算法(6)中有两个假设:
1)有很多个经验不停从s到s‘获取r。
2)假设任意的s’的都已知。

解决办法:


















 7126
7126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









