






SSD
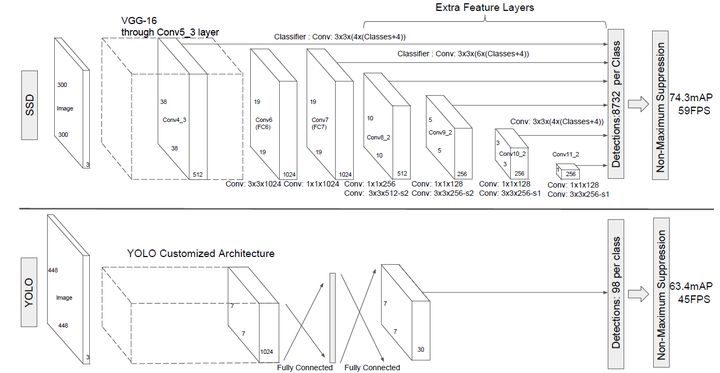
正负样本选择
- 同YOLO
选择与GT IOU最大的anchor作为正样本。(此时正负样本很不平衡) - 对于剩余未匹配anchor,将与GT IOU超过0.5的作为正样本。这样一个GT就可以匹配多个anchor,增加正样本的数量。(此时负样本依然多于正样本)
- hard negative mining,难负样本挖掘。将所有负样本按照预测的背景置信度进行降序排序(预测背景的置信度越小,误差越大),选择误差大的前几个作为负样本,以保证正负样本比例接近1:3。
毕设项目演示地址: 链接
毕业项目设计代做项目方向涵盖:
目标检测、语义分割、深度估计、超分辨率、CNN、GAN、目标跟踪、竞赛解决方案、人脸识别、数据增广、人脸检测、数据集、图像分割、SLAM、实例分割、人体姿态估计、视频目标分割、Re-ID、医学图像分割、显著性目标检测、自动驾驶、人群密度估计、PyTorch、人脸、车道线检测、去雾 、全景分割、行人检测、文本检测、OCR 边缘检测、场景文本检测、视频实例分割、模型压缩、人脸对齐、超分辨、去噪、强化学习、行为识别、OpenCV、场景文本识别、去雨、机器学习。
损失
位置损失:smoothL1。同faster RCNN
置信度误差(类别+背景一体):softmax loss而不是BCE
问题
为什么要在conv4_3使用L2 normalization?
因为conv4比较靠前,数据通道间的特征分布和后续的几层相差较大,所以通过在通道维度进行L2归一化。归一化后一般设置一个可训练的放缩变量gamma。
参考链接
RetinaNet
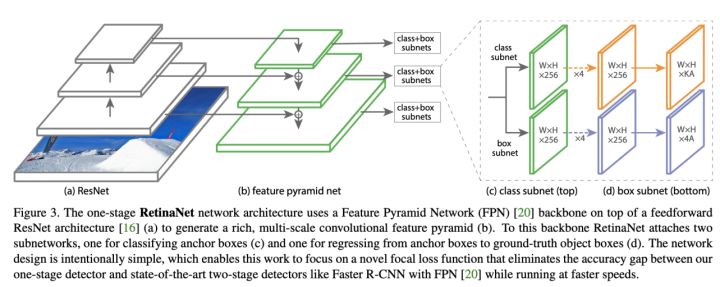
主要优点
1、多尺度:借鉴FPN网络通过自下而上、自上而下的特征提取网络,并通过无代价的横向连接构建增强特征提取网络,利用不同尺度的特征图检测不同大小的目标,利用了底层高分率的特征图有效的提高了模型对小尺度目标的检测精度
2、样本不平衡:引入Focal Loss用于候选框的【类别预测】,克服正负样本不平衡的影响及加大困难样本的权重。
主要不足
1、实时性:网络使用ResNet-101作为主干特征提取网络,检测效率略微不足















 272
272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











