






hive中的数据分为真实数据与元数据,一般来说Hive的存储格式是指真实数据的存储格式。
Hive常用的存储格式(四种)
| 存储格式 | 存储格式 | 说明 |
|---|---|---|
| TEXTFILE | 文本文件格式,按行存储(常见:txt、csv、tsv) | Hive默认存储格式,支持使用Gzip压缩,但压缩后失去了使用集群并行处理的优势 |
| SEQUENCEFILE | “二进制序列化过的Key/Value字节流”组成的文本存储文件格式 | Hive无法直接导入,可分割的 |
| RCFILE | 面向列的数据存储格式 | 遵循“先水平划分,再垂直划分”的设计理念,可分割的 |
| ORCFILE | 对RCFILE的优化格式 | 支持压缩比很高的压缩算法,文件可切分、提供多种索引,支持复杂的数据结构 |
Hive数据单元
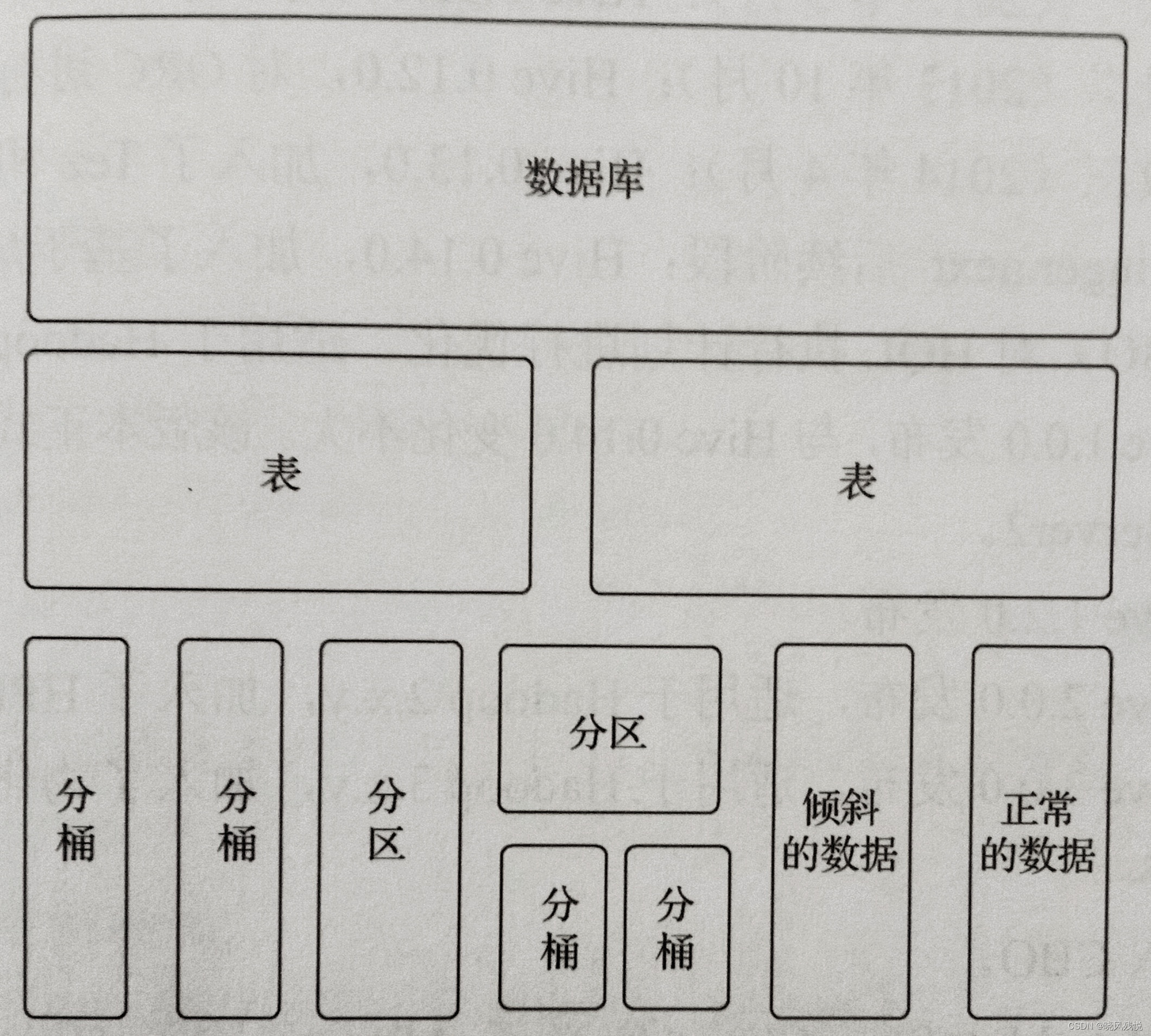
Hive所有真实数据都存储在HDFS中,这样更利于对数据做分布式计算。为了有效地对数据进行管理,根据粒度大小,进行真实数据划分如下数据单元:
-
数据库:在HDFS中表现为hive.metastore.warehouse.dir目录下的一个文件夹,本质用于避免命名冲突的命名空间。
-
表:由列构成,在表上可进行过滤、映射、连接和联合操作。
| 分类 | 说明 |
|---|---|
| 内部表 | 由Hive管理,类似与RDBMS中的表(删除后均被删除) |
| 外部表 | 真实数据不被Hive管理。已经存在HDFS中的数据,与内部表元数据组织是相同的,但数据存放位置是任意的(删除后只删除元数据,不删除真实数据) |
-
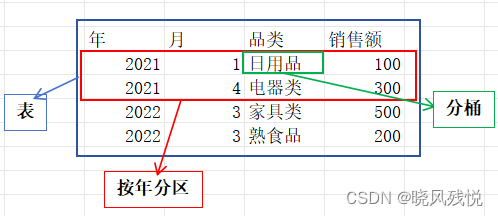
分区:按指定的键分为多个分区。
-
分桶:同一个目录下根据哈希散列之后的多个文件。
下图为划分数据存储的模型和示例:
注意:Hive表没有主键;不支持行级操作;不支持批量update操作,但可以先删除、再添加;分区和分桶可以极大地提升数据查询效率
拓展:MySQL内、左、右连接
MySQL内、左、右、全连接我们以表与表间的连接为例
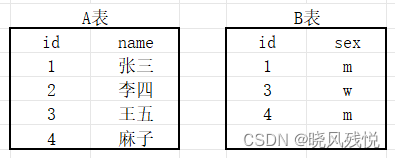
内连接
内连接查询的是两张表或者多个表的交集,也就是两张表的公共部分。
select * from A,B on A.id = b.id

左连接
左连接也称为左外链接,是将左表和左右表交集的组合。
左连接以左表为基础,根据on 后给出的条件将两表连接起来,最终的结果会将左表所有的信息列出,而右表只列出on条件与左表满足的部分,其余部分为空。
select * from A left join B on A.id = B.id;

右连接
右连接也称为右外链接,是将右表和左右表交集的组合。
右连接以右表为基础,根据on 后给出的条件将两表连接起来,最终的结果会将右表所有的信息列出,而左表只列出on条件与右表满足的部分,其余部分为空。
select * from A right join B on A.id = B.id;

最后,本篇文章是基于我所学所知进行的知识总结,如有误论,虚心接受指正。参考文献是《Hadoop数据仓库实战》,感兴趣的小伙伴可以对其进行深入阅读。(2024/03/11)















 675
675

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









