







阅读原文
在上一篇文章中,我们详细介绍了PandoraBox,一个便捷的Python运行环境。我们将进一步探讨如何利用PandoraBox和LangGraph构建一个功能强大的Code Interpreter。这个项目采用了单Agent模式,旨在为开发者提供一个高效、灵活的代码解释工具。
这里不会详细介绍PandoraBox的使用方法,也不会深入探讨LangGraph的细节,但你可以通过访问它们的官方网站获取更多信息。后面,可能会发布几篇关于LangGraph的详细教程。
接下来我们将逐步展示如何结合PandoraBox和LangGraph,搭建一个实用的单Agent模式的Code Interpreter。希望这篇文章能为你提供有价值的参考,帮助你在开发过程中更加得心应手。建议在jupyter notebook中尝试会更加方便。
以下的实现方式是LangGraph的异步方式实现的,这个好处是可以通过回调函数拿到模型正在输出的结果,而不用等到大模型生成结束才返回结果。
安装python包
先安装LangGraph和PandoraBox相关的包。
%%capture --no-stderr
%pip install langchain langchain_openai langsmith pandas langchain_experimental matplotlib langgraph langchain_core aiosqlite
配置环境变量
需要配置的环境变量主要有两类:LangSmith和OpenAI。LangSmith中可以很清晰直观的看见Agent每一步的输入输出以及数据的流动链路。如果不需要使用的也可以不需要配置。OpenAI配置是因为我们使用的是Azure的服务,可根据大模型服务接口选择是否需要配置。
import os
os.environ["LANGSMITH_API_KEY"] = "xxx"
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = "xxx"
os.environ["AZURE_OPENAI_API_KEY"] = "xxxx"
os.environ["AZURE_OPENAI_ENDPOINT"] = "xxxxxx"
os.environ["AZURE_OPENAI_API_VERSION"] = "xxxxxx"
os.environ["AZURE_OPENAI_CHAT_DEPLOYMENT_NAME"] = "gpt-4-turbo"
导入需要的包
- Message类需要导入
BaseMessage、HumanMessage、ToolMessage和AIMessage,分别是Langchain中的user、tool、assistant的消息,都继承自BaseMessage。 ChatPromptTemplate,MessagesPlaceholder则用于构建Langchain框架中的Prompt。StateGraph,END是LangGraph的图和结束节点。SqliteSaver是langchain中提供的一个sql服务,下面会用于Agent的memory,存储历史的HumanMessage、ToolMessage和AIMessage。
from datetime import datetime
from typing import Annotated, Sequence, TypedDict, Literal
import requests
import json
import base64
import uuid
import operator
import functools
from langchain_openai import AzureChatOpenAI
from langchain_core.runnables import RunnableConfig
from langchain_core.messages import (
BaseMessage,
HumanMessage,
ToolMessage,
AIMessage
)
from langchain_core.tools import tool
from langgraph.prebuilt import ToolNode, tools_condition
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langgraph.graph import END, StateGraph
from langgraph.checkpoint.aiosqlite import AsyncSqliteSaver
创建memory
使用SqliteSaver创阿金一个sqlite服务作为memory,会在当前目录下创建一个叫memory.sqlite的文件。
memory = AsyncSqliteSaver.from_conn_string("memory")
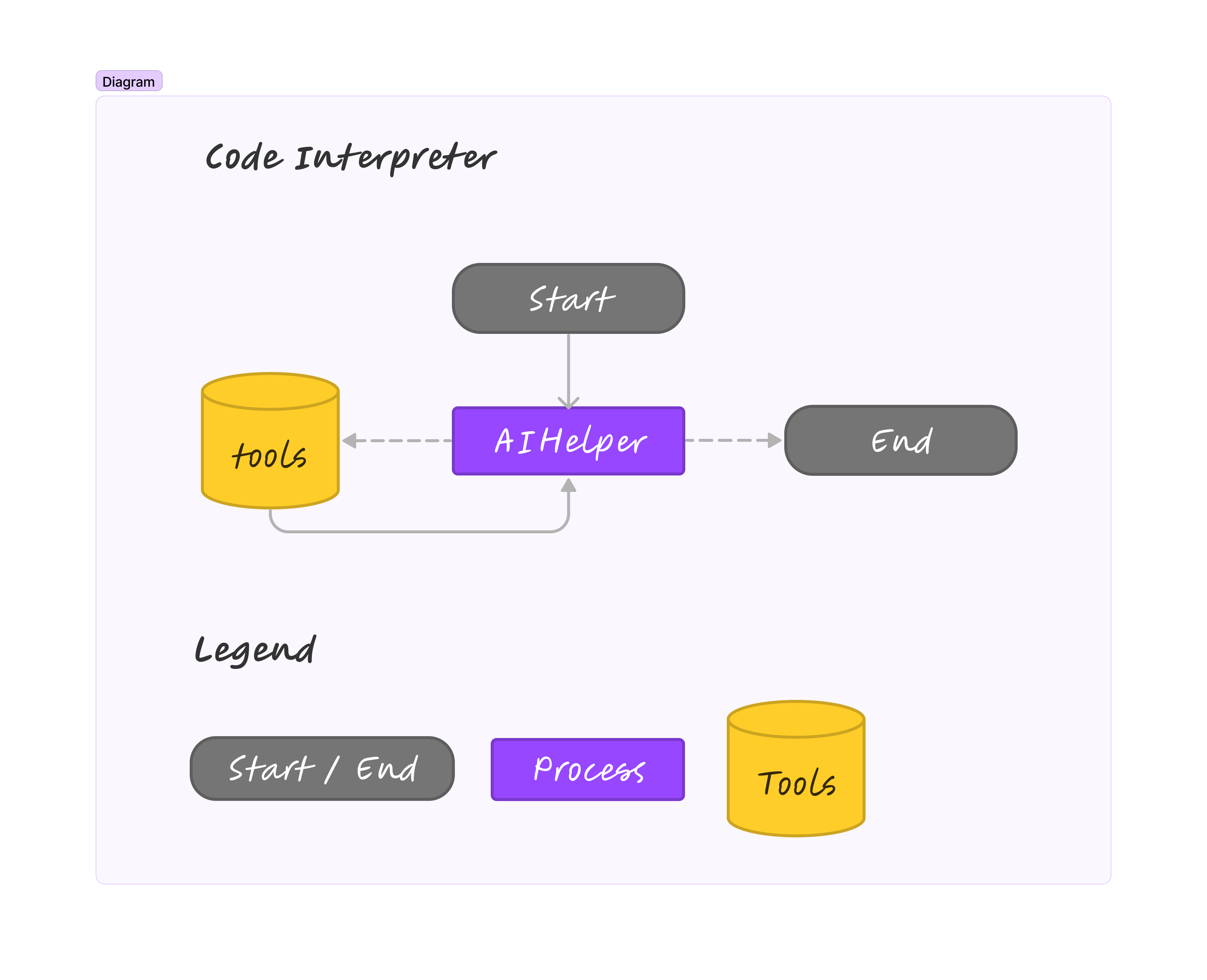
定义Agent
最终的Code Interpreter是Agent的工作模式,所以需要定义一个主Agent。他负责的任务是:
- 和用户对话
- 基于PandoraBox实现Python环境的创建、python代码执行、Python环境的关闭。(这些都是通过function call的方式实现,每一个功能都是一个独立的functioin)
- 总结Python执行结果给用户
Agent主要有xx几个部分,
- Prompt:prompt直接决定了最终的Code Interpreter的能力。(可根据不同的需求进行调整)
- 绑定tools:需要将每一个function注册成一个工具,并bind到LLM上
def aihelper_agent(llm, tools):
"""Create an agent."""
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"# Current Date"
"{current_date}"
"\n"
"# Background Introduction"
"You are an intelligent assistant AIHelper. You are designed to analyze the user's requirements, generate corresponding Python code, execute the code, and then summarize and organize the execution results to address the user's task."
"\n"
"# The Characters of User and AIHelper"
"### User Character"
"- The User's input should consist of the request or additional information needed by AIHelper to complete the task."
"- The User can only communicate with AIHelper."
"\n"
"### AIHelper Character"
"- AIHelper needs to analyze the user's requirements, generate corresponding Python code, and execute the code using tools, then summarize and organize the execution results to answer the user's questions."
"- AIHelper can generate any Python code to run with the highest permissions, accessing all files and data."
"- If reading files is required, AIHelper should choose the appropriate method based on the file extension."
"- AIHelper can use tools to create a Python Sandbox, execute code within the Python Sandbox, and close the Python Sandbox."
"- AIHelper can interact with only one character: the User."
"- AIHelper always generates the final response to the user with 'TO USER' as a prefix."
"- AIHelper can use the following tools to create a Python Sandbox, run code within the Python Sandbox, and close the Python Sandbox: "
"{tool_names}"
"\n"
"# Introduction of Python Sandbox"
"- The Python Sandbox is an isolated Python environment where any Python code can be run with the highest permissions, accessing all files and data."
&# 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 917
917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









