







 本文深入探讨了Python的Pandas库在数据分析中的应用,从Pandas的导入、Series和DataFrame类型创建及其操作开始,详细介绍了数据导入导出、索引操作、数据运算以及数据分析技巧,包括数据清理、合并、统计等。此外,还提到了Pandas在数据处理中的重要性和与其他Python库如NumPy的比较。
本文深入探讨了Python的Pandas库在数据分析中的应用,从Pandas的导入、Series和DataFrame类型创建及其操作开始,详细介绍了数据导入导出、索引操作、数据运算以及数据分析技巧,包括数据清理、合并、统计等。此外,还提到了Pandas在数据处理中的重要性和与其他Python库如NumPy的比较。

Pandas导入
Pandas是Python第三方库,提供高性能易用数据类型和分析工具 Pandas基于NumPy实现,常与NumPy和Matplotlib一同使用 两个数据类型:Series, DataFrame
import pandas as pd
Pandas与numpy的比较

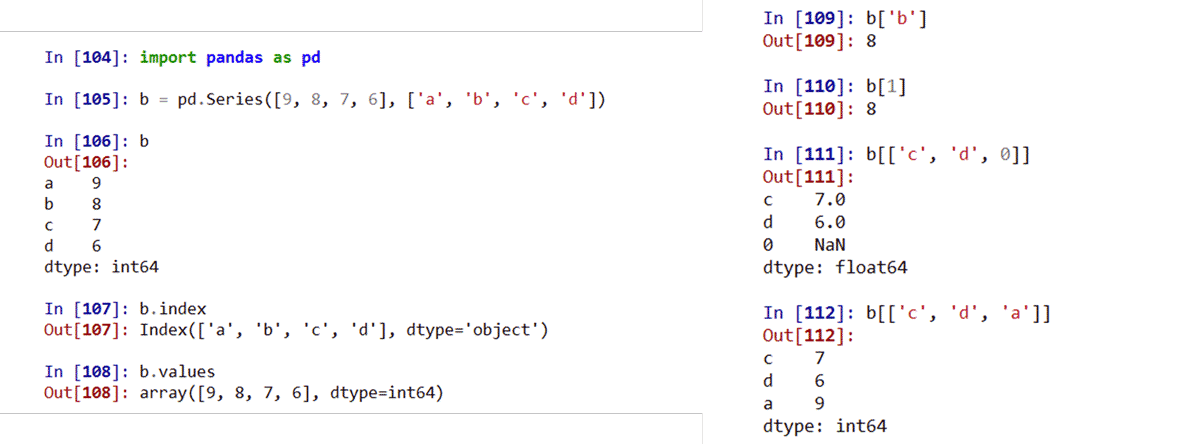
Pandas的Series类型
由一组数据及与之相关的数据索引组成

Pandas的Series类型的创建
Series类型可以由如下类型创建:
Python列表,index与列表元素个数一致 标量值,index表达Series类型的尺寸 Python字典,键值对中的“键”是索引,index从字典中进行选择操作 ndarray,索引和数据都可以通过ndarray类型创建 其他函数,range()函数等


Pandas的Series类型的基本操作
Series类型包含index和values两个部分:
index 获得索引 values 获得数据
由ndarray或字典创建的Series,操作类似ndarray或字典类型
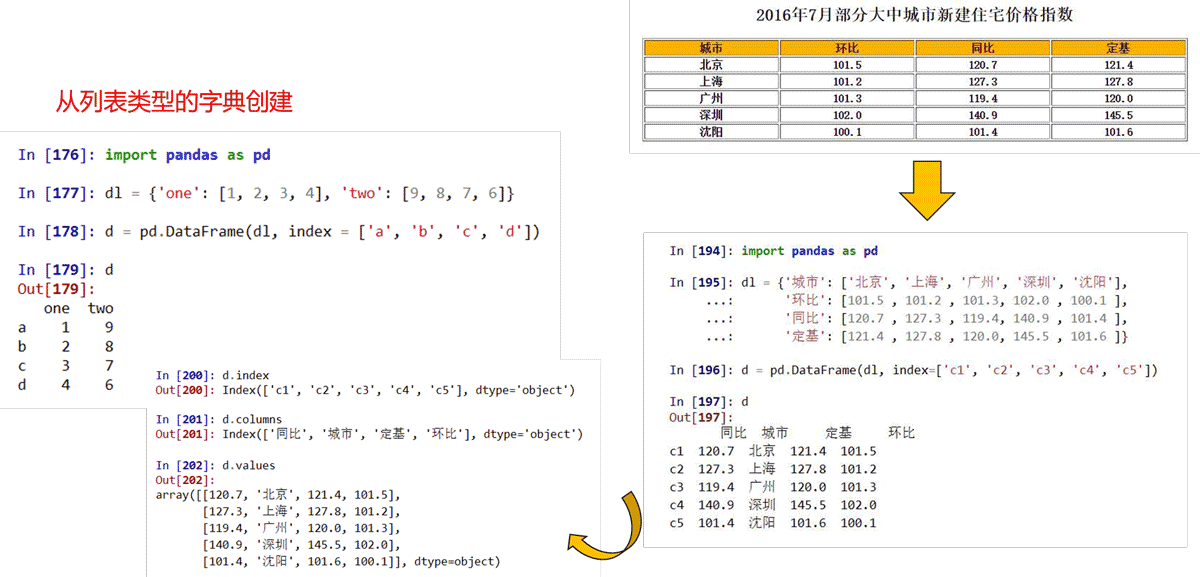
pandas的DataFrame类型
DataFrame类型由共用相同索引的一组列组成
DataFrame是一个表格型的数据类型,每列值类型可以不同
DataFrame既有行索引、也有列索引
DataFrame常用于表达二维数据,但可以表达多维数据
DataFrame是二维带“标签”数组
DataFrame基本操作类似Series,依据行列索引

pandas的DataFrame类型创建
DataFrame类型可以由如下类型创建:
二维ndarray对象 由一维ndarray、列表、字典、元组或Series构成的字典 Series类型 其他的DataFrame类型

Pandas的Dataframe类型的基本操作
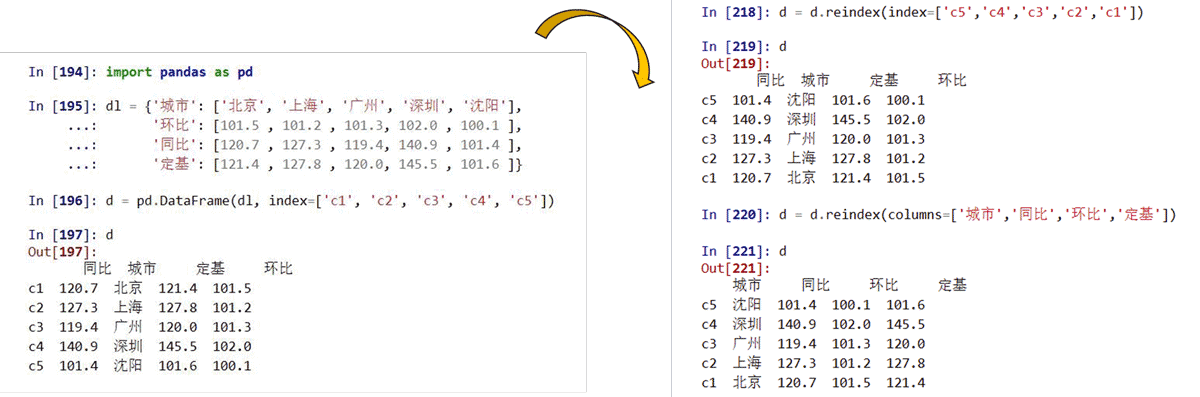
pandas索引操作
pandas重新索引
reindex()能够改变或重排Series和DataFrame索引
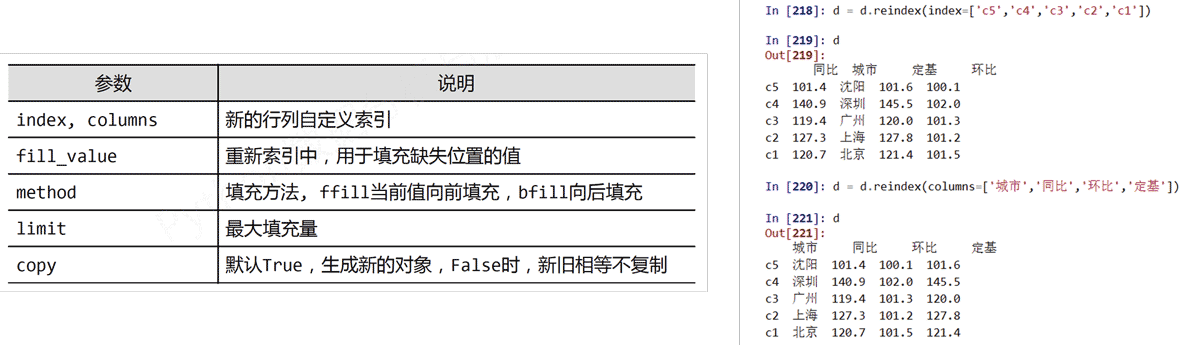
reindex(index=None, columns=None, …)的参数
pandas删除索引
dro
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 907
907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









