






本文目录
1 一个像素就是一个 token!探索 Transformer 新范式
(来自 FAIR, Meta AI,阿姆斯特丹大学)
1 PiT 论文解读
1.1 局部性这个归纳偏置可以在 Transformer 中去除
1.2 ConvNets 中的局部性
1.3 ViTs 中的局部性
1.4 像素 Transformers
1.5 实验1:监督学习
1.6 实验2:自监督学习
1.7 实验3:图像生成
1.8 ViT 中的局部性设计
1.9 PiT 的局限性
太长不看版
本文不是提出新视觉 Transformer 架构的工作,而是质疑视觉 Transformer 中 归纳偏置 (inductive bias),即现代视觉 Transformer 中局部性 (locality) 的必要性。
本文的发现:原始 Transformer 中可以直接将每个单独的像素 (pixel) 视为 token。 这可以在目标检测,MAE 自监督训练以及基于扩散模型的图像生成这3大任务上实现高性能的结果。本文的模型为 Pixel Transformer (PiT)。
这个发现与当前 ViT 的范式,即将每个 16×16 的 Patch 视为 token 有很大不同。这就是将 ConvNets 的归纳偏差维持在局部的邻域内。
尽管本文直接对单个像素进行操作在计算复杂度来讲不太实用,但作者也相信在为计算机视觉设计下一代神经架构时,社区会意识到这个问题。
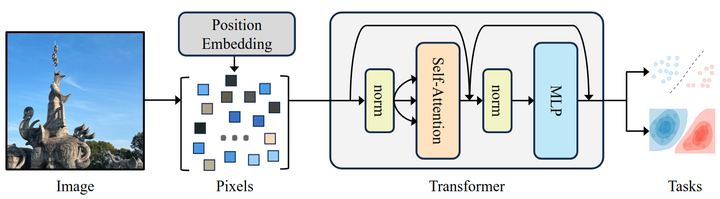 图1:Pixel Transformer (PiT) 架构:给定一个图像,简单地将其视为一组像素。作者还使用了随机初始化和可学习的位置嵌入,没有任何关于 2D 结构的信息,因此从 ViT 中删除了剩余的局部归纳偏置
图1:Pixel Transformer (PiT) 架构:给定一个图像,简单地将其视为一组像素。作者还使用了随机初始化和可学习的位置嵌入,没有任何关于 2D 结构的信息,因此从 ViT 中删除了剩余的局部归纳偏置
本文的模型适配的任务
- 作者密切遵循标准 Transformer 编码器的设计,将该架构直接应用于输入图像中具有可学习位置嵌入的无序像素集。这消除了 ViT 中局部性的剩余归纳偏置。作者将其命名为 Pixel Transformer (PiT),如图1所示。从概念上讲,PiT 可以看作是 ViT 的简化版本,具有 1×1 大小 Patch 而不是 16×16。
- 使用 Masked Autoencoding (MAE) 的框架作掩码图片建模预训练,然后微调做分类任务。数据集 CIFAR-100。
- 使用 Diffusion Transformer (DiT) 的框架作图像生成任务。
在这3个任务上,作者发现 PiT 表现合理,且比配备局部归纳偏置的基线获得了更好的结果。
1 一个像素就是一个 token!探索 Transformer 新范式
论文名称:An Image is Worth More Than 16 ×16 Patches: Exploring Transformers on Individual Pixels (Arxiv 2024.06)
论文地址:
http://arxiv.org/pdf/2406.09415
1.1 局部性这个归纳偏置可以在 Transformer 中去除
深度学习的革命可以被归结为计算机视觉中归纳偏置 (inductive bias) 的革命。在神经网络之前,人们手工设计特征。对于特定的任务,编码一些预先定义好的有用的模式和结构。但是在神经网络之后,特征不再通过手工设计,而是通过大量数据使用预定义的神经网络架构直接学习得到。这种范式的转变强调了减少特征偏差的重要性,这样得以创建更加通用和强大的视觉系统。
除了特征之外,模型架构还具有归纳偏置。减少架构上的归纳偏置,不仅可以促进不同任务的大一统,也可以促进不同数据模态的大一统。Transformer[1]架构就是一个典型的例子。一开始是为了语言任务设计的,后来它可以被应用于图像[2]、点云[3]、代码[4]和许多其他模态的数据中。值得一提的是,与 ConvNets 相比,Vision Transformer (ViT) 携带的图像特定的归纳偏置要少得多。但是尽管如此,这种归纳偏置得初始优势很快就会被大量数据和大尺寸的模型所抵消,最终反而成为防止 ConvNets 进一步缩放的限制。
当然,ViT 也不是完全没有归纳偏置。它摆脱了 ConvNet 中的金字塔结构 (spatial hierarchy),使用一个 plain 的架构进行建模。对于 ConvNets 的其他归纳偏差并没有完全去掉。比如这里讨论3种归纳偏置:Spatial Hierarchy,Translation Equivariance, Locality。后面的 Translation Equivariance 和 Locality 仍然存在于 ViT 中。其中,Translation Equivariance 存在于 Patch projection 层和中间 Block 中,Locality 存在于 Patchify 步骤中。因此,出现了一个自然的问题:究竟能否完全消除其余的这2个归纳偏差中的任何一个或者全部消除?本文旨在回答这个问题。
本文的发现令人惊讶:Locality 可以完全被去除。 作者通过直接将每个单独的像素 (Pixel) 视为 Transformer 的 token 并使用从头开始学习的位置编码,得出这一结论。通过这种方式,作者引入了关于图像二维网格结构的零先验。作者将 Pixel Transformer 的缩写命名为 PiT。有趣的是,PiT 的训练不仅没有发散,也没有陡峭的性能退化,而是可以获得更好的结果。这说明 Transformer 架构可以将图片视为单个 Pixel 的集合,而不是仅仅是 16×16 的 Patch。这个发现挑战了传统的观念,即:“局部性是视觉任务的基本归纳偏置”。
作为相关研究,作者还研究了其他2个个局部性设计 (Position Embedding 和 Patchification) 在标准 ViT 架构中的重要性。对于Position Embedding 使用3种选择:sin-cos、learned 和 none。sin-cos 携带局部性偏置,其他两个没有。本文的结果表明,Patchification 提供了更强的局部性先验,并且平移等变性对于网络设计仍然是必不可少的。
 图2:视觉架构中的主要归纳偏置。ConvNets 包含所有的3种:空间金字塔,平移等变性以及局部性。ViT 没有第1种,减弱但仍保留了后两个。PiT 通过简单地将 Transformer 应用于像素完全去除了局部性。它的效果出奇地好,具有挑战性的主流观点,即局部性是视觉架构的必要条件
图2:视觉架构中的主要归纳偏置。ConvNets 包含所有的3种:空间金字塔,平移等变性以及局部性。ViT 没有第1种,减弱但仍保留了后两个。PiT 通过简单地将 Transformer 应用于像素完全去除了局部性。它的效果出奇地好,具有挑战性的主流观点,即局部性是视觉架构的必要条件
1.2 ConvNets 中的局部性
局部性这种归纳偏置指的是相邻像素比距离较远的像素更相关的属性。
在 ConvNet 中,局部性反映在网络每一层的特征的感受野中。直观地说,感受野覆盖了计算特定特征所涉及的像素,对于 ConvNets 而言这些区域是局部的。
具体来说,ConvNets 由很多层组成,每一层都包含一定大小的卷积核 (例如 7×7 或 3×3) 或池化操作的卷积操作,这两者都是局部有偏差的。例如,第一层的感受野通常仅对应于一个小的局部窗口。随着网络的深入,该区域逐步扩展,但窗口仍然是局部的,并以像素的位置为中心。
1.3 ViTs 中的局部性
乍一看,Transformer 架构是没有局部性的,因为大多数 Transformer 操作要么是全局的 (例如,Self-Attention),要么是纯粹在每个单独的 token (比如 MLP) 内部。然而,仔细观察 ViT 中的两个设计,这些设计仍然可以保留局部归纳偏置:Patchification 和 Position Embedding。
Patchification 的局部性: 在 ViT 中,输入到 Transformer Block 中的 token 是一个个 Patch,而不是 Pixel。每个 Patch 由 16×16 的 Pixel 所组成,成为第1个投影层之后的基本单元。这意味着 Patch 内的计算量与 Patch 的数量有很大不同:16×16 区域之外的信息只能通过 Self-Attention 传播,而 16×16 区域内部的信息总是被当做是 token 一起处理。虽然在第一个 Self-Attention 之后感受野变成了全局的,但是在 Patchification 步骤中已经引入了局部性这种归纳偏置。
Position Embedding 的局部性: Position Embedding 可以是可学习的,也可以在训练期间手动设计和固定。对于图像而言的正常选择是使用 2D sin-cos embedding[5][6]。由于 sin-cos 函数是平滑的,它们倾向于引入归纳偏置:附件的 token 更相似。位置编码还有其他的一些变体[2],但它们都可以携带有关图像的 2D 网格结构的信息,这与没有对输入做出假设的可学习的位置编码不同。
当位置嵌入作插值操作时,局部性归纳偏置也会被利用。通过双线性或双三次插值,使用空间接近的嵌入来生成当前位置的新嵌入,这也利用局部性作为先验。
与 ConvNets 相比,ViT 设计中的局部性归纳偏置要少很多。作者接下来通过完全删除这种偏置进一步推动这一点。
1.4 像素 Transformers


1.5 实验1:监督学习
作者从头开始训练和评估 PiT,无需任何预训练。基线是 Patch Size 为 2×2 的 ViT。
数据集:CIFAR-100, ImageNet。
虽然 CIFAR-100 由于其 32×32 的图像大小,适合于探索 PiT 的有效性,但 ImageNet 有更多的图像,这有助于进一步确认本文发现。
对于 CIFAR-100,由于即使对于 ViT 也缺乏最佳的训练配方,因此作者搜索训练配方并报告 Tiny 和 Small 模型的结果。作者使用[7]的增强从头开始训练,因为作者发现更高级的增强 (例如 AutoAug) 在这种情况下没有帮助。所有模型都使用 AdamW 进行训练。作者使用 1024 的 Batch Size、0.3 的 Weight Decay、0.1 的 Drop Path 和 0.004 的初始学习率,作者发现对于所有模型来说是最好的。使用 20 个 Epoch 的线性学习率 warmup,余弦学习率衰减到 1e-6。训练 2400 个 Epoch,补偿数据集的小尺寸。
在 ImageNet 上,作者密切关注 ViT 从头开始的训练配方,并使用 PiT-S 和 PiT-B 报告结果。由于计算的限制,默认情况下,图像被裁剪并调整为 28×28 作为低分辨率输入。全局平均池化输出用于分类。训练 Batch Size 为 4096,初始学习率为 ,权重衰减为 0.3,Drop Path 为 0.1,训练长度为 300 个 Epoch。使用 MixUp (0.8)、CutMix (1.0)、RandAug (9, 0.5) 和指数移动平均 (0.9999)。
虽然本文的2个 ViT 变体 (ViT-T 和 ViT-S) 的基线在 CIFAR-100 上得到了很好的优化 (例如,[8]报告了 ViT-B 的 72.6% 的 Acc@1,但是使用较小尺寸的模型实现了 80+%),PiT-T 比 ViT-T 提高了 1.5% 的 Acc@1;当使用更大的模型 (S) 时,PiT Acc@1 比 Tiny 模型提高了 1.3%,而 ViT 似乎出现饱和。这些结果表明,与基于 Patch 的 ViT 相比,PiT 有可能直接从像素中学习新的、数据驱动的模式。
本文的观察也转移到 ImageNet,尽管分辨率显着降低,但结果明显低于最先进的[2][9] (80+%),PiT 在尝试的两种设置中仍然优于 ViT。

1) 固定序列长度: 作者在图 3(a) 中展示了具有固定 的 ImageNet 的精度趋势。模型大小为 ViT-B。在此图中,当改变 Patch Size 从 16×16 到 1×1 时,输入大小会有所不同,即从 224×224 到 14×14。最后一个数据点等价于 PiT-B。如果遵循这一趋势,那么 PiT 性能是最差的。这意味着即使对于分类,序列长度也不是 Acc@1 的唯一决定因素。Input size,或输入到模型中的信息量可以说是更重要的因素,尤其是当 Input size 较小时。只有当 Input size 足够大 (例如 112×112) 时,进一步扩大 Input size 的边际效应才开始递减。这也意味着当输入的信息量不够时,PiT 或遵循这种设计的任何架构 (例如,iGPT) 的效果不佳。
2) 固定输入大小: 当固定输入大小 (信息量) 时,并在图 3(b) 中改变 ImageNet 上的 Patch Size。模型大小为 ViT-S。有趣的是,作者在这里观察到相反的趋势:减少 Patch Size (或增加序列长度) 总是有帮助的,这与之前声称序列长度非常重要的研究一致注意即使趋势最终达到 PiT,即没有任何局部性的模型,趋势也成立。因此,与 ViT 相比,PiT 在精度方面表现更好。
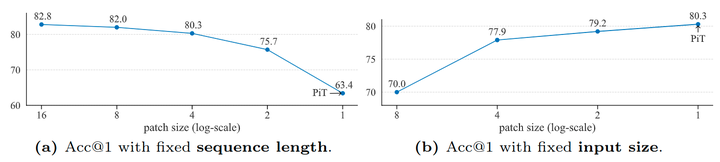 图3:ImageNet 上 PiT 与 ViT 的两个趋势
图3:ImageNet 上 PiT 与 ViT 的两个趋势
1.6 实验2:自监督学习
作者使用 MAE 自监督预训练研究 PiT,然后作有监督微调完成分类任务。选择 MAE 是因为它的效率只保留了 25% 的序列长度。
数据集使用 CIFAR-100,因为它大小为 32 × 32 的图像,使得能够充分探索使用像素作为原始分辨率的 token。首先在 CIFAR-100 训练集上执行预训练。然后它在微调阶段用作初始化 (也在 CIFAR-100 训练集上训练)。同样在 CIFAR-100 上使用图像分类作为下游任务。
作者遵循标准 MAE 并使用 75% 的 mask ratio 并随机选择 tokens。给定剩余的 25% 可见标记,模型需要使用像素回归重建掩码区域。由于 CIFAR-100 上 MAE[5]没有已知的默认训练设置,作者使用 PiT-T 和 PiT-S 搜索训练策略并报告结果。直接使用 MAE[5]的数据增强策略。所有模型都使用 AdamW 进行预训练。作者使用 MAE[5]的预训练策略执行 1600 个 Epoch 的预训练,除了初始学习率为 0.004,学习率衰减为 0.85。
如图4中所示。可以发现对于 PiT,与从头开始训练相比,MAE 自监督预训练提高了精度。对于 PiT-T 和 PiT-S 也是如此。值得注意的是,当从 Tiny 迁移到 Small 模型时,ViT 和 PiT 之间的差距变得更大。这表明 PiT 可能比 ViT 有更好的扩展性。
1.7 实验3:图像生成
作者使用 Diffusion Transformer (DiT) 做图像生成任务,它具有与普通 ViT 不同的架构,并对 VQGAN 的 latent token 进行操作,将输入大小缩小到 8×。数据集方面,使用 ImageNet 进行 class-conditional generation,每张图像的中心裁剪为 256×256,得到 32×32×4 的输入特征图大小 (4 是通道维度)。PiT-L 被馈送到此特征图中,与 Baseline DiT-L/2 相同。
作者遵循 DiT 训练的设置,Batch Size 为 (2048),使训练更快 (原始训练配方使用 256 的 Batch Size)。为了使训练稳定,执行线性学习率 100 个 Epoch,然后在总共 400 个 Epoch 中保持它不变。使用 8e-4 的最大学习率,不使用权重衰减。
PiT-L的采样代如图5所示。采样需要250个 time steps,latent diffusion 的输出使用 VQGAN 解码器映射回像素空间。使用了 4.0 的 Classifier-free guidance。
 图5:PiT 的图像生成结果采样。得到的 256×256 样本来自 ImageNet 上训练的 PiT-L,遵循与 DiT 相同的架构
图5:PiT 的图像生成结果采样。得到的 256×256 样本来自 ImageNet 上训练的 PiT-L,遵循与 DiT 相同的架构
作者在图6中报告了 DiT-L/2 和 PiT-L 之间的性能比较。尽管训练策略发生了变化,但本文基线很强:与训练 ~470 个 Epoch 的 DiT-XL 的10.67的 FID 相比,本文 DiT-L/2 在没有 classifier-free guidance 的情况下达到了 8.90。作者主要比较前两行使用具有 250 个采样步骤的 1.5 的 classifier-free guidance。使用 PiT 对 latent pixel 进行操作,它在3个指标 (FID、sFID 和 IS) 上的表现优于 Baseline,并且在精度/召回率上持平。
 图6:图像生成实验结果
图6:图像生成实验结果
PiT 开箱即用的事实表明本文观察具有很好的泛化能力:没有局部性的神经网络架构可被用于不同的任务和架构。
1.8 ViT 中的局部性设计
作者检查了2个 ViT 中与局部性相关的设计:(i) Position Embedding 和 (ii) Patchification。使用 ViT-B 进行ImageNet 监督分类。采用与 MAE 完全相同的超参数、增强和其他训练细节。值得注意的是,图像被裁剪和调整大小为 224×224,分为 16×16 不重叠的 Patches。
Position Embedding
作者从3个 Position Embedding 的候选中进行选择:sin-cos、learned 和 none。第1个选项将局部性引入模型中,而其他2个则没有。
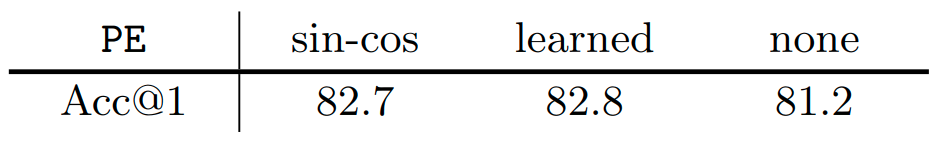 图7:Position Embedding 实验结果
图7:Position Embedding 实验结果
结果显示,可学习的位置编码与固定的 sin-cos 位置编码性能差不多。即使根本没有位置编码,性能仅略有下降。
Patchification
接下来,作者使用可学习的位置编码和研究 Patchification。为了系统地减少 Patchification 的局部性,作者认为相邻的像素不应该绑定在同一个 Patch 中。因此,作者进行了一个 pixel-wise 的排列,将结果序列再分成独立的 tokens。每个 token 包含 256 个 pixels,与 16×16 Patch 中的 pixel 数量相同。

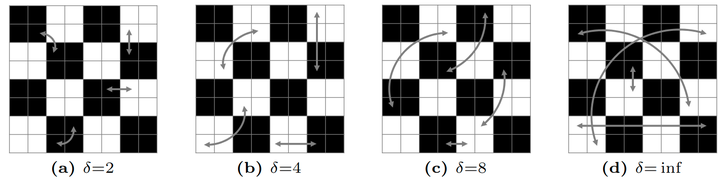 图8:像素排列:研究 ViT 中 Patchification 的影响
图8:像素排列:研究 ViT 中 Patchification 的影响

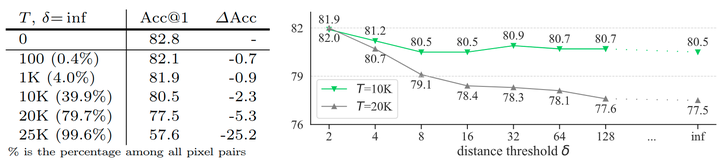 图9:ImageNet 上 ViT-B 的像素排列结果。作者改变像素交换的数量 T (左) 和像素交换的最大距离 δ (右)。这些结果表明,与交换位置编码相比,像素排列对性能的影响要大得多
图9:ImageNet 上 ViT-B 的像素排列结果。作者改变像素交换的数量 T (左) 和像素交换的最大距离 δ (右)。这些结果表明,与交换位置编码相比,像素排列对性能的影响要大得多
总体来讲,与改变 Position Embedding 相比,像素排列对精度产生了更显着的影响,这表明 Patchification 对 ViT 的整体设计更为关键,强调了本文完全删除 Patchification 工作的价值。
1.9 PiT 的局限性
因为将每个 Pixel 视为一个 token 会导致序列长度比之前要长得多,所以 PiT 不像 ViT 那样实用。Transformers 中的 Self-Attention 操作需要二次复杂度的计算。因此在实践中,把图片视为 16×16 的 Patch 仍然可以说是最有效的想法,以质量换取效率,局部性仍然有用。尽管如此,作者相信本文的结果提供了一个干净、令人信服的证明,即 “局部性不是模型设计的必要归纳偏置”。
而且,随着处理 LLM 的超长序列 (高达百万) 技术[10]的发展,完全有可能直接在所有像素上训练 PiT (例如,ImageNet 上的标准 224×224 图片包含 50,176 像素)。因此,本文的目的是以较小的规模经验验证 PiT 的有效性和潜力。作者并将实际部署的工程努力留到未来,也相信这一发现将是探索下一代处理图像时社区知识不可或缺的一部分。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。















 128
128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









