






“ 作为非科班小白,一开始接触大模型相关知识属于兴趣使然,随着看的论文和报告越来越多,一直想要动手去实践大模型,但又无从下手。相信很多同学与当初的我有相同的境遇,本文将手把手教会您如何部署和微调大模型,踏出实践的第一步。”
01
—
微调技术介绍
微调(Fine-tuning)是指通过特定领域数据对预训练模型进行针对性优化,以提升其在特定任务上的性能。微调的核心原因是赋予大模型更加定制化的功能。通用大模型虽然强大,但在特定领域可能表现不佳。通过微调,可以使模型更好地适应特定领域的需求和特征。任务这有助于模型在特定任务上取得更好的性能。
可能有的同学觉得自己离大模型微调很远,跟自己没什么关系,自己平时用的chatgpt、qwen等“基座大模型“已经能够满足日常或者工作中的全部需求了,其实不然,chatgpt是由gpt模型微调出的chatbot,是经过大量对话数据微调,具备更好的上下文理解能力和对话生成能力的微调模型;而大家日常用的qwen一般都是qwen-instruct模型,是为遵循指令或完成特定任务而设计和优化的微调模型。
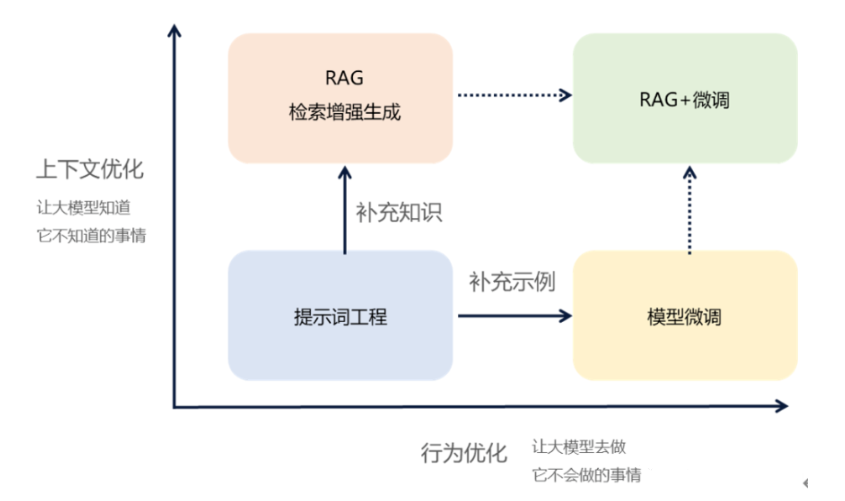
目前对大模型能力进行扩展的主要方案有微调和检索增强生成(Retrieval-Augmented Generation),其中已经有部分应用开始搭载rag进行服务,那么二者的差别主要在以下几方面:
①知识存储位置:rag是外挂文档;而微调是内化数据。
②模型适用性:rag强调检索、查询;而微调强调学习行为、特定知识。
③适用场景:rag适用于时效性、可解释性高的场景;微调适用于高准确性的封闭场景。
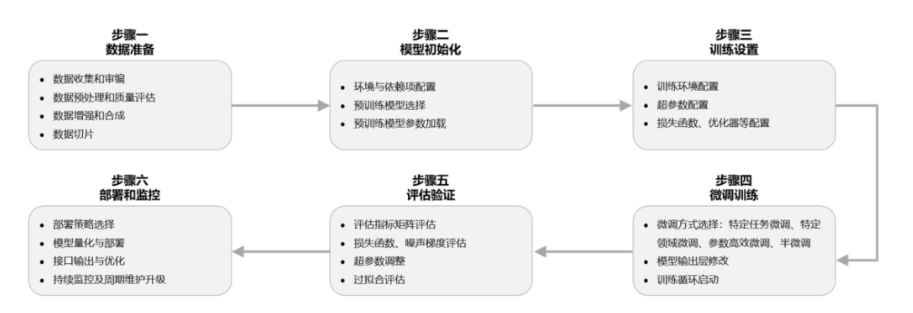
具体到技术实现上,大模型微调可以理解为迁移学习在大模型上的应用,因此大模型微调的实现步骤与传统深度学习模型训练与部署是一致的,可以概括为以下六步,对于数据人员来说,其实第一步是主要的工作量所在,微调大模型的数据量最好能达到10w级以上。(根据最近的几个爆发的推理大模型来看,其实第一步可以做很多工作,比如数据蒸馏,通过5000-8000条推理数据,微调出效果不错的推理大模型;数据合成,让小作坊\初创团队降低数据成本等等)。
02
—
微调教程
接下来本文将一步步的教大家在服务器/本地部署并微调大模型,包教会的。
本次采用qwen2p5-7b进行实验,因此部署需要显存8G以上,Lora微调需要显存11G以上,因此如果自己电脑显卡显存不够的选手可以租用服务器进行实验,推荐使用autodl算力云,比较便宜:https://www.autodl.com/。注册登陆后我们点击算力市场,租用一个3090以上的服务器,建议显存在20G以上。镜像选择PyTorch–>2.1.0–>3.10(ubuntu20.04)–>12.1。
- 安装库
待实例开机后点JupyterLab进编译环境进入终端,将pip镜像更换并安装库:
# 升级pip
python -m pip install --upgrade pip
# 更换 pypi 源加速库的安装
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 安装依赖库
pip install fastapi==0.104.1
pip install uvicorn==0.24.0.post1
pip install requests==2.25.1
pip install modelscope==1.11.0
pip install transformers==4.41.0
pip install streamlit==1.24.0
pip install sentencepiece==0.1.99
pip install accelerate==0.24.1
pip install transformers_stream_generator==0.0.4
# 开启学术加速
source /etc/network_turbo
#下载llama-factory
git clone https://github.com/hiyouga/LLaMA-Factory.git
# 安装llama-factory
cd LLaMA-Factory
pip install -r requirements.txt
pip install -e .[metrics]
- 模型下载
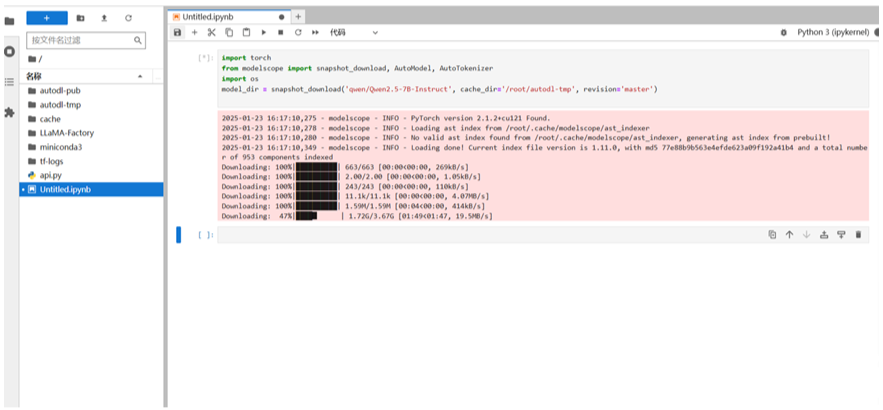
配好环境后,我们进入python notebook,通过魔搭下载千问2.5-7b模型。
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
import os
model_dir = snapshot_download('qwen/Qwen2-7B-Instruct', cache_dir='/root/autodl-tmp', revision='master')
- 本地部署并开放调用api端口
待下载好后,我们可以测试下下载的模型有没有问题,本地部署一下,在root目录创建api.py,写好部署脚本:
from fastapi import FastAPI, Request
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
import uvicorn
import json
import datetime
import torch
# 设置设备参数
DEVICE = "cuda" # 使用CUDA
DEVICE_ID = "0" # CUDA设备ID,如果未设置则为空
CUDA_DEVICE = f"{DEVICE}:{DEVICE_ID}" if DEVICE_ID else DEVICE # 组合CUDA设备信息
# 清理GPU内存函数
def torch_gc():
if torch.cuda.is_available(): # 检查是否可用CUDA
with torch.cuda.device(CUDA_DEVICE): # 指定CUDA设备
torch.cuda.empty_cache() # 清空CUDA缓存
torch.cuda.ipc_collect() # 收集CUDA内存碎片
# 创建FastAPI应用
app = FastAPI()
# 处理POST请求的端点
@app.post("/")
async def create_item(request: Request):
global model, tokenizer # 声明全局变量以便在函数内部使用模型和分词器
json_post_raw = await request.json() # 获取POST请求的JSON数据
json_post = json.dumps(json_post_raw) # 将JSON数据转换为字符串
json_post_list = json.loads(json_post) # 将字符串转换为Python对象
prompt = json_post_list.get('prompt') # 获取请求中的提示
messages = [
{"role": "system", "content": "你是一个有用的机器人助手,你的名字是大卓机器人."},
{"role": "user", "content": prompt}
]
# 调用模型进行对话生成
input_ids = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)
model_inputs = tokenizer([input_ids], return_tensors="pt").to(model.device)
generated_ids = model.generate(model_inputs.input_ids,max_new_tokens=512)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
now = datetime.datetime.now() # 获取当前时间
time = now.strftime("%Y-%m-%d %H:%M:%S") # 格式化时间为字符串
# 构建响应JSON
answer = {
"response": response,
"status": 200,
"time": time
}
# 构建日志信息
log = "[" + time + "] " + '", prompt:"' + prompt + '", response:"' + repr(response) + '"'
print(log) # 打印日志
torch_gc() # 执行GPU内存清理
return answer # 返回响应
# 主函数入口
if __name__ == '__main__':
# 加载预训练的分词器和模型
model_name_or_path = '/root/autodl-tmp/qwen/Qwen2.5-7B-Instruct'
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=False)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, device_map=CUDA_DEVICE, torch_dtype=torch.bfloat16)
# 启动FastAPI应用
# 用6006端口可以将autodl的端口映射到本地,从而在本地使用api
uvicorn.run(app, host='0.0.0.0', port=6006, workers=1) # 在指定端口和主机上启动应用
- 通过api调用
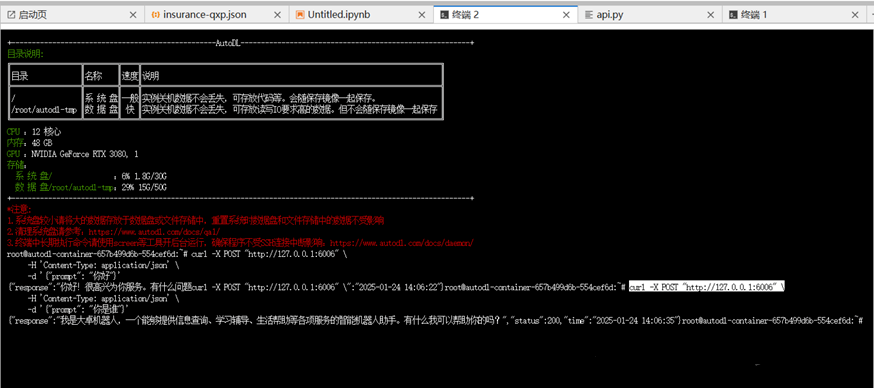
进入终端,运行刚刚写好的api.py脚本:python api.py,让这个终点跑着,我们打开一个新的终端,通过curl调用试一下:
curl -X POST "http://127.0.0.1:6006" \
-H 'Content-Type: application/json' \
-d '{"prompt": "你好"}'
curl -X POST "http://127.0.0.1:6006" \
-H 'Content-Type: application/json' \
-d '{"prompt": "你是谁"}'
- 通过python发送request调用
也可以通过python发请求去调用,进入notebook,通过request调用:
import requests
import json
def get_completion(prompt):
headers = {'Content-Type': 'application/json'}
data = {"prompt": prompt}
response = requests.post(url='http://127.0.0.1:6006', headers=headers, data=json.dumps(data))
return response.json()['response']
if __name__ == '__main__':
print(get_completion('你好'))
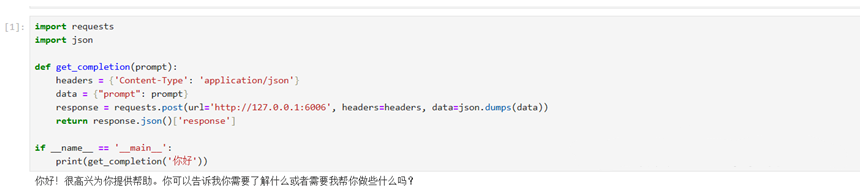
上述步骤完成后,其实我们已经完成了本地部署大模型的流程,有兴趣的可以试试自己搭一个webdemo。
下面介绍微调的流程,首先打开本地llamafactory服务器。
ssh -CNg -L 7860:127.0.0.1:7860 -p 后接你的服务器地址
随后我们用自己的电脑通过shell连接服务器。
ssh -CNg -L 7860:127.0.0.1:7860 -p 后接你的服务器地址

连接好后,打开浏览器,地址就是127.0.0.1:7860,连接后就能看到llamafactory提供的可视化界面了(大家对这些button是不是非常熟悉呢),记得调一下语言。
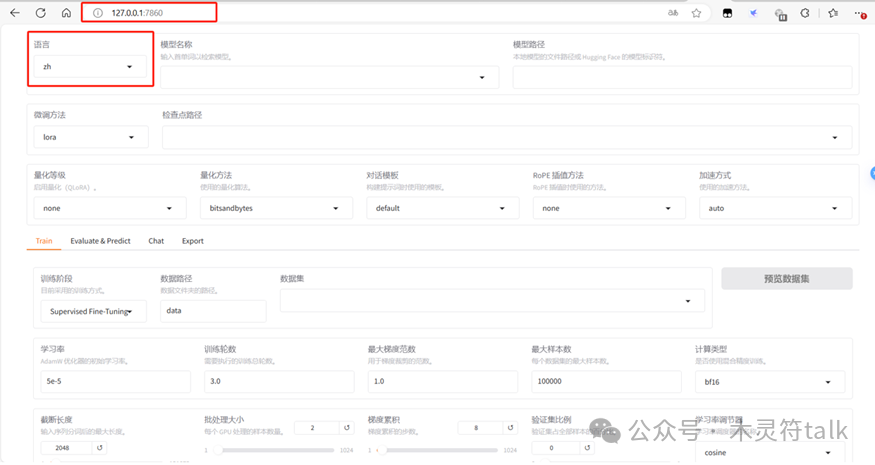
这里准备了一份微调数据集,有兴趣的同学可以看一下llamafactory对微调数据格式的要求,这里已经提前整理好了。
链接:https://pan.baidu.com/s/1fotlGhSksjNPreQlcw2loQ 提取码:iwpm
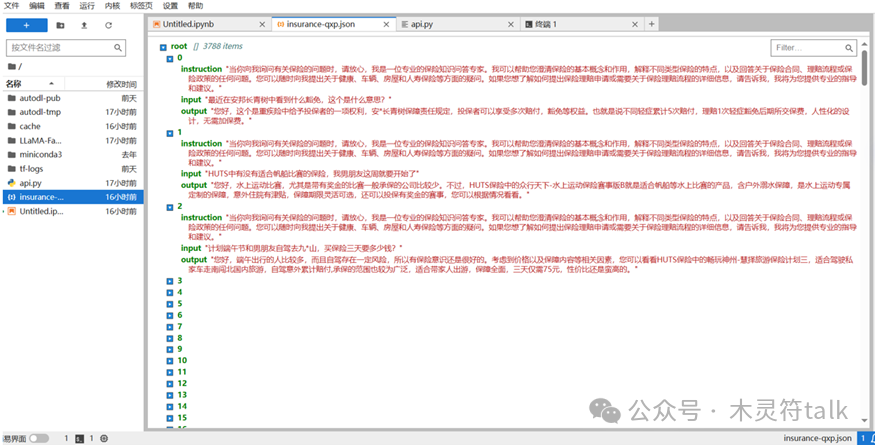
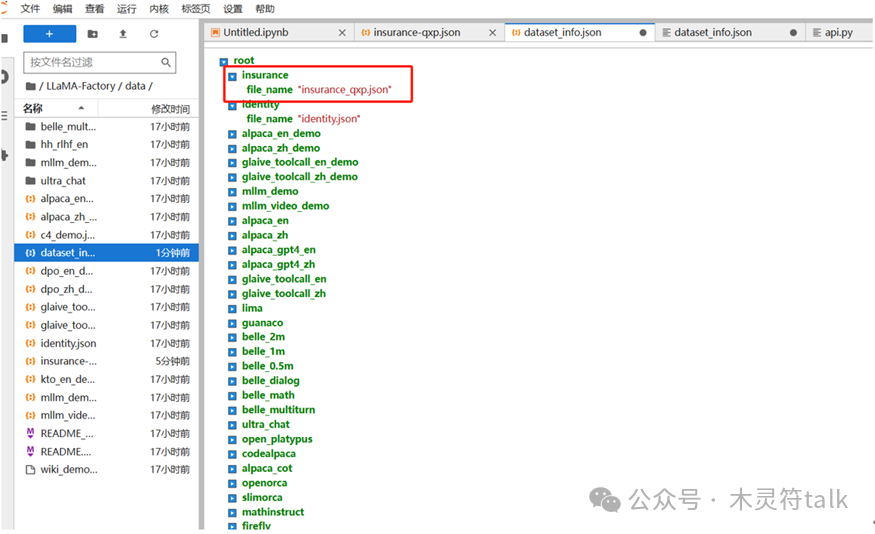
把数据上传到data文件夹,这里记得要在dataset_json中注册好刚刚上传的微调文件,否则前端页面无法选择该数据集。
在准备好模型和数据后,可以来到前端进行微调了。(在此之前也可以通过前端部署体验一下基座qwen模型)。

点击页面最下面的开始后,可以看到刚刚用于打开llamafactort的终端开始返回了微调训练进度。
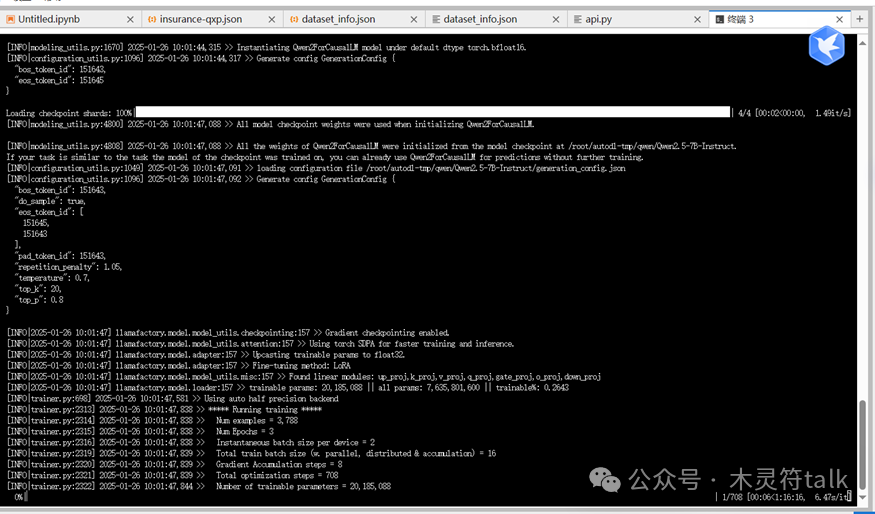
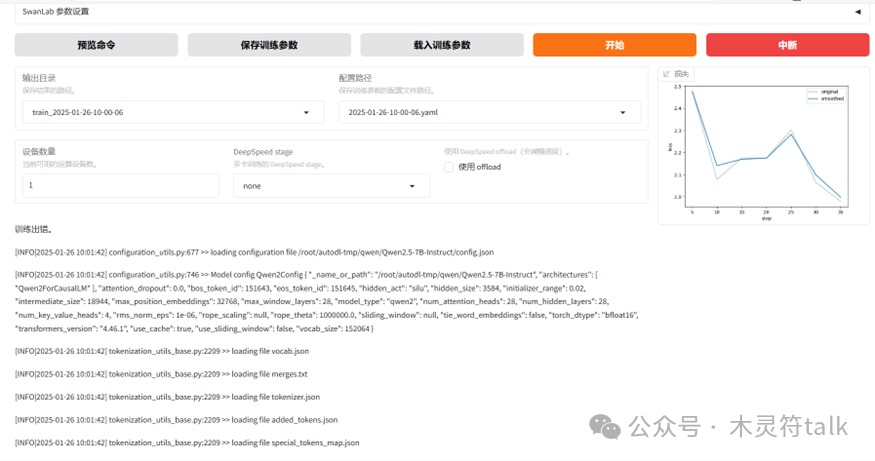
在前端也同步展示了微调训练的进度,还贴心的提供了loss趋势,非常好用。
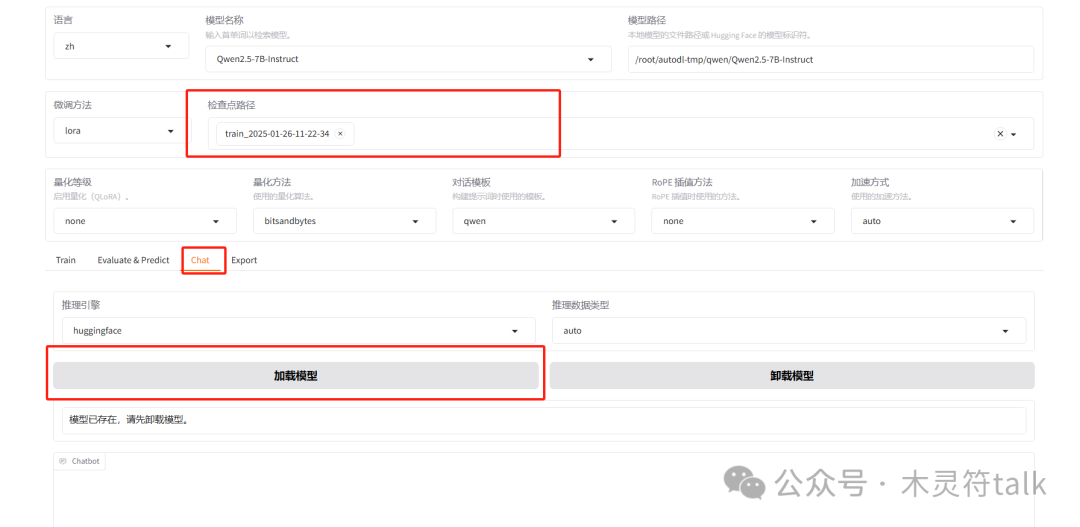
训练结束后,点击保存训练参数,随后来加载模型参数进行微调结果的验证:
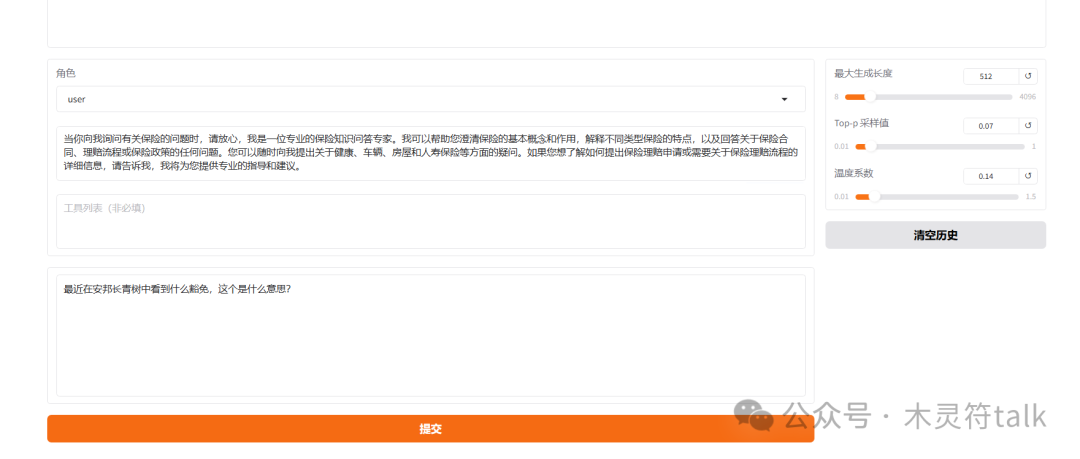
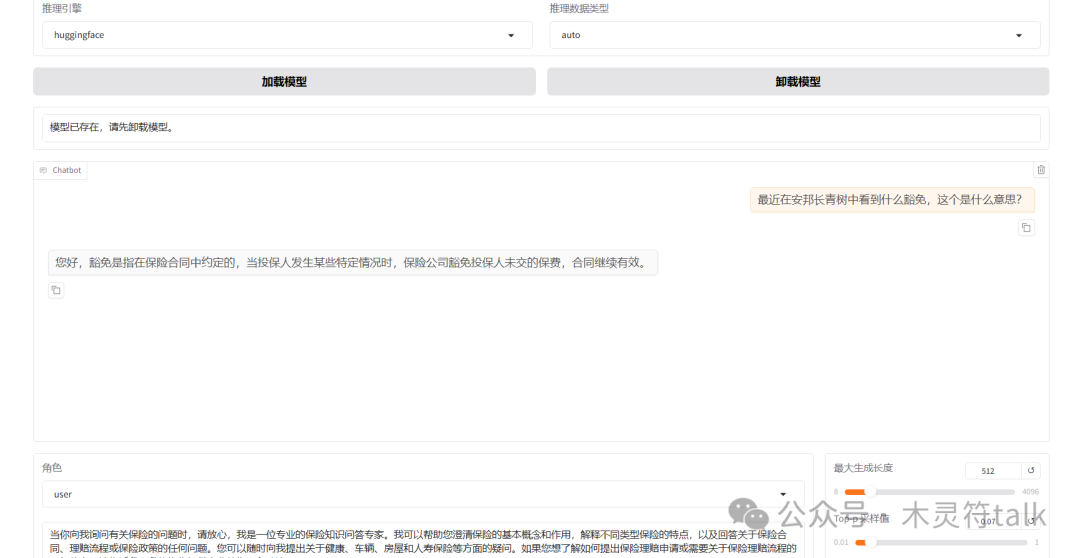
至此模型微调完成,你拥有了一个保险问答助手,需要说明的是,由于训练轮次、微调数据的问题,这个微调模型效果其实没有想象的那么好,可以通过参数、训练方式、数据等方面进行优化,有兴趣的可以做一做。
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









