







一、大模型的特点
1)不确定性 与传统应用不同,模型的输出是不确定的,即使多次问它一样的问题,给出的结果也可能不一样。这种特性对于日常应用业务 OK,但是如果要在企业内用来处理具体业务问题,就必须提高这个稳定性,否则影响生产经营,例如产线操作人员通过模型获取操作步骤或者参数,如果步骤或者数据不对可能会导致产品出现质量问题等等。
2)静态性 模型一旦训练好,就无法再补充数据,因此模型不会了解你自己组织内部的年假规定,注意事项。如何让大模型掌握这些数据是另外一个需要解决的问题。
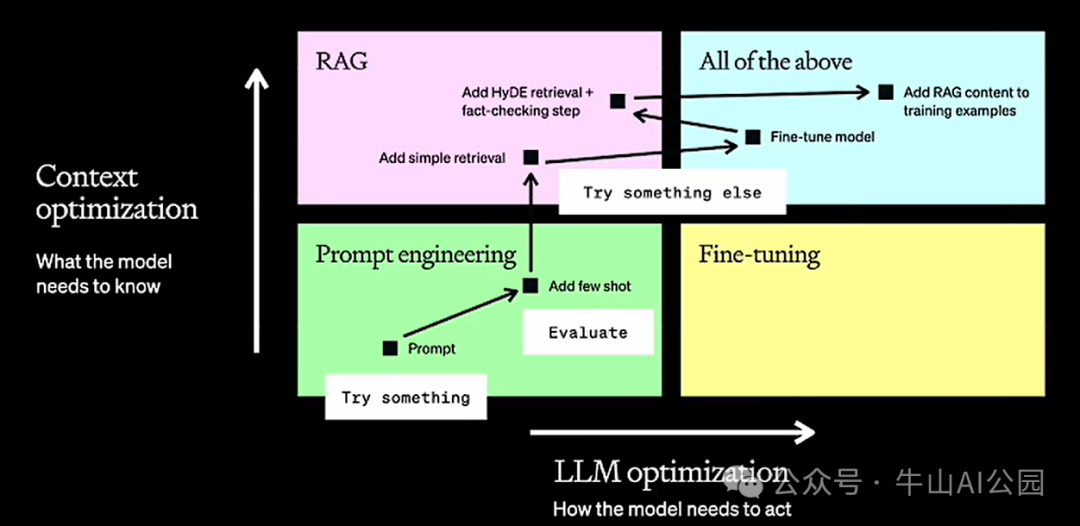
上述问题会影响大模型在企业内部的使用,因此针对模型的优化主要会有 两个方向:
行为优化: 对应上图横轴,横轴表示大模型的表现能力,让大模型做它原来不会做的事情,例如以一个医学专家的方式进行表达,或者其他新的方式进行表达,并且它能理解。这个维度主要解决模型输出形式上的稳定性。
上下文优化: 对应上图竖轴,竖轴表示大模型的知识能力,这个纬度主要关注私域数据,是让模型知道它所不知道的事情,包括:模型训练中从未见过的数据,比如内部代码、文档、规范、策略等。这个维度主要解决模型输出内容上的相关性。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 277
277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









