






前言
Self-Attention 和 Transformer 自从问世就成为了自然语言处理领域的新星。得益于全局的注意力机制和并行化的训练,基于 Transformer 的自然语言模型能够方便的编码长距离依赖关系,同时在大规模自然语言数据集上并行训练成为可能。但由于自然语言任务种类繁多,且任务之间的差别不太大,所以为每个任务单独微调一份大模型很不划算。
关于Self-Attention 和 Transformer的详细介绍可以参考以下文章:
爱吃牛油果的璐璐:transformer的全面解析
爱吃牛油果的璐璐:一文带你学会 Attention
在 CV 中,不同的图像识别任务往往也需要微调整个大模型,也显得不够经济。Prompt Learning 的提出给这个问题提供了一个很好的方向。
本文主要根据综述文章《Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing》[1] 以及相关论文整理而来,在此基础之上,总结了一些现有的对 prompt learning 的相关讨论(如其缺陷,与其他学习方法的比较等)。望承前人之高屋建瓴,增添后之砖瓦。希望大家能批判性地阅读,如有误处,恳请斧正。
NLP 模型的发展
过去许多机器学习方法是基于全监督学习(fully supervised learning)的。
由于监督学习需要大量的数据学习性能优异的模型,而在 NLP 中大规模训练数据(指为特定任务而标注好的数据)是不足的,因此在深度学习出现之前研究者通常聚焦于特征工程(feature engineering),即利用领域知识从数据中提取好的特征;
在深度学习出现之后, 由于特征可以从数据中习得,因此研究者转向了结构工程(architecture engineering),即通过通过设计一个合适的网络结构来把归纳偏置(inductive bias)引入模型中,从而有利于学习好的特征。
在 2017-2019 年,NLP 模型开始转向一个新的模式(BERT),即预训练 + 微调(pre-train and fine-tune)。在这个模式中, 先用一个固定的结构预训练一个语言模型(language model, LM),预训练的方式就是让模型补全上下文(比如完形填空)。关于大模型的微调方法可以参加以下文章:爱吃牛油果的璐璐:大模型微调的常见方法
zhuanlan.zhihu.com/p/673789772?utm_psn=1722017964881178624
由于预训练不需要专家知识,因此可以在网络上搜集的大规模文本上直接进行训练。然后这个 LM 通过引入额外的参数或微调来适应到下游任务上。此时研究者转向了目标工程(objective engineering),即为预训练任务和微调任务设计更好的目标函数。
什么是 Prompt
此处借用刘鹏飞老师在北京智源大会 Big Model Meetup 第1期:大模型 Prompt Tuning 技术中给出的例子来进行阐述。
A. An Intuitive Definition
Prompt is a cue given to the pre-trained language model to allow it better understand human’s questions.
“提示” 是一种提供给预训练语言模型的线索,让预训练语言模型能更好的理解人类的问题。
B. More Technical Definition
Prompt is the technique of making better use of the knowledge from the pre-trained model by adding additional texts to the input.
目的是更好地利用预训练模型中的知识
手段是在输入中增加额外的文本(clue/prompt)
如下图所示,根据提示,BERT 能回答/补全出 “JDK是由 Oracle 研发的”,BART 能对长文本进行总结,ERNIE 能说出鸟类的能力。
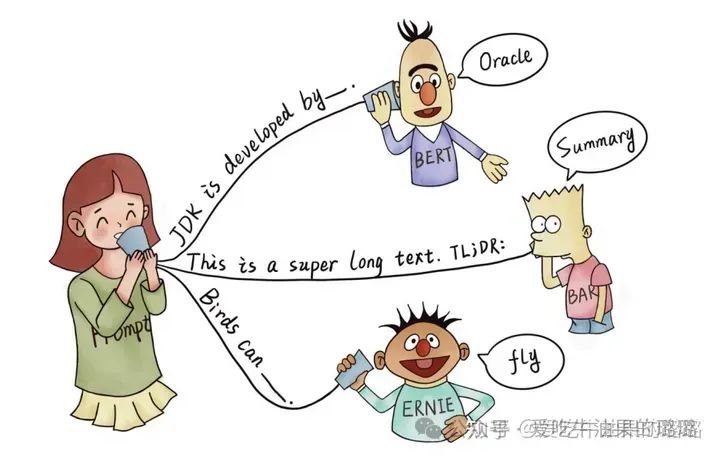
在做 objective engineering 的过程中,研究者发现让下游任务的目标与预训练的目标对齐是有好的。因此下游任务通过引入文本提示符(textual prompt),把原来的任务目标重构为与预训练模型一致的填空题。
比如一个输入 “I missed the bus today.” 的重构:
●情感预测任务。输入:“I missed the bus today.I felt so___.” 其中 “I felt so” 就是提示词(prompt),然后使用 LM 用一个表示情感的词填空。
●翻译任务。输入:“English:I missed the bus today. French:___.” 其中 “English:” 和 “French:” 就是提示词,然后使用 LM 应该再空位填入相应的法语句子。
我们发现用不同的 prompt 加到相同的输入上,就能实现不同的任务,从而使得下游任务可以很好的对齐到预训练任务上,实现更好的预测效果。
后来研究者发现,在同一个任务上使用不同的 prompt,预测效果也会有显著差异,因此现在有许多研究开始聚焦于 prompt engineering。
已有的预训练模型
● Left-to-Right LM: GPT, GPT-2, GPT-3
● Masked LM: BERT, RoBERTa
● Prefix LM: UniLM1, UniLM2
● Encoder-Decoder: T5, MASS, BART
提示学习的通用流程(General Workflow)
提示学习的基本流程主要包括以下四个步骤:提示构造(Prompt Construction),答案构造(Answer Construction),答案预测(Answer Prediction),以及答案-标签映射(Answer-Label Mapping)。接下来以NLP中很常见的 text classification 任务:情感分类(Sentiment Classification)作为例子来分别阐述这四个步骤。
情感分类的任务描述:
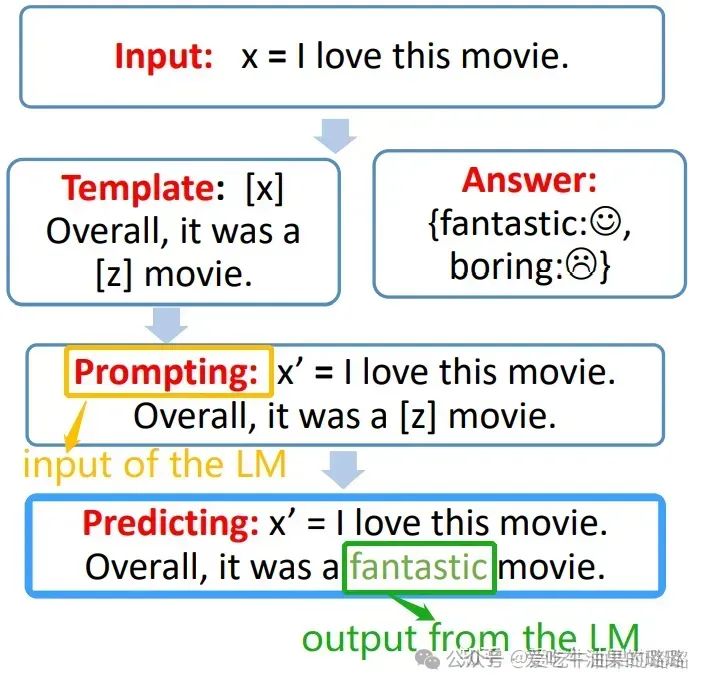
输入:句子 x*(e.g.* Input: x = I love this movie.)
输出:对 x 的情感极性预测 (i.e., v.s )
step 0. Prompt Construction: 将input x 转为为带提示的 x’的过程。
首先,需要设计一个模板, 一个包含输入槽(input slot)[x] 和答案槽(answer slot)[z] 的文本串,输入槽留给 input x*,答案槽 [z] 用于生成答案(answer)z,*答案 z 之后会被映射到输出的标签或文本(output label or text)。
接下来,将 input x 代入到输入槽 [x] 中。具体过程如下图所示:

注:答案槽 [z] 可以位于 x’ 的中间位置或者末尾位置,通常称 [z] 在中间的 x’ 为 cloze prompt(完形填空提示),[z] 在末尾的 x’ 为 prefix prompt(前缀型提示)。
step 1. Answer Construction:设计 answer 和 class label 之间的映射函数
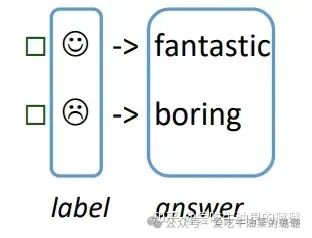
注:特殊情况1,answer 和 label 是相同的,比如机器翻译任务;特殊情况2,多个 answer 可以映射到同一个 label,比如情感分类任务中 “excellent, good, wonderful” 等词均可映射到正向的情感 。
step 2. Answer Predicting: 选择合适的LM, 并让其通过给定的x’ 预测 answer z
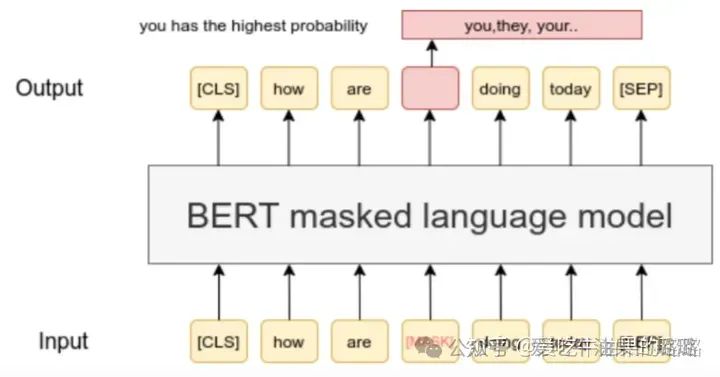
首先选择合适的 LM,此处以 Masked LM Bert 为例,关于 LM 的选择策略将会在后续介绍。可以看出,BERT 的输入和我们之前构造好的 x’ 形式相同,其中的 [mask] 与 x’ 中的 [z] 相同,都是为输出预留的槽位。
通过构造 promting x’,情感分类的任务被转化为了 LM 任务,可以直接使用 LM 来对 [z] 进行预测得到答案(answer)z。
step 3. Answer Mapping:将 LM 预测出来的 answer z 映射为 label。
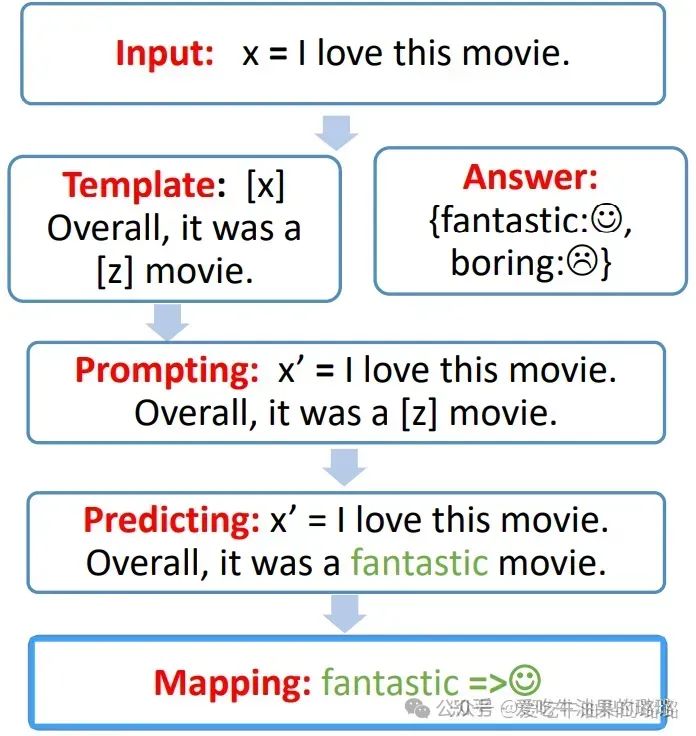
至此,就完成了一个使用 prompt learning 方法进行情感分类任务的过程,也大致介绍了 prompt learning 中的基本术语,总结于下表中:

Summary of terminology in prompt learning. Credit to Pengfei Liu.
Prompt Learning方法总结
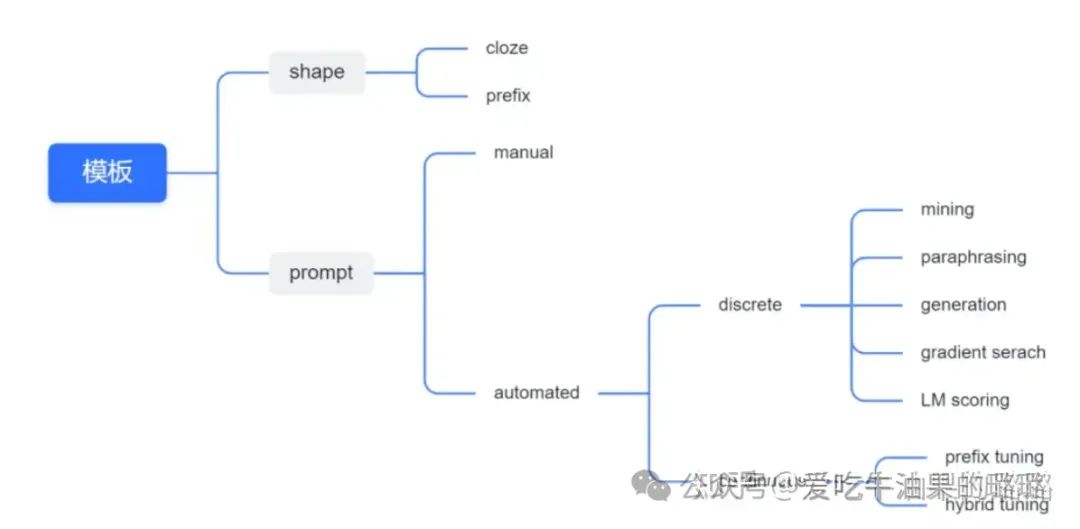
● 按照 prompt 的形状划分:完形填空式,前缀式。
● 按照人的参与与否:人工设计的,自动的(离散的,连续的)
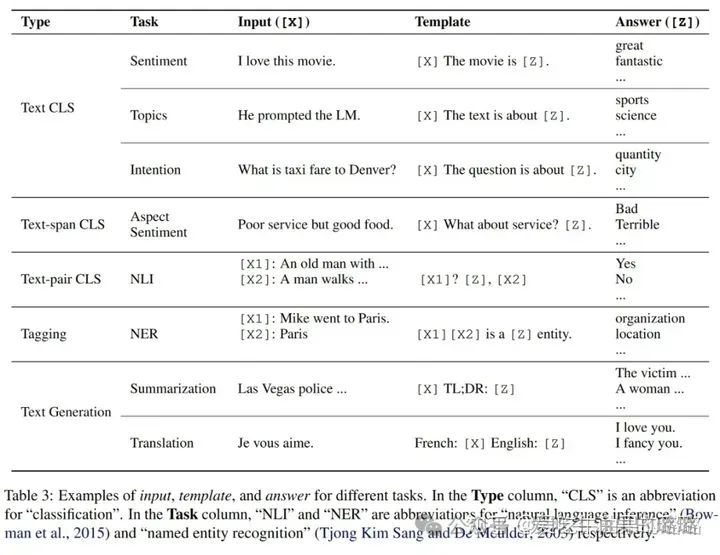
人工设计的 Prompt
Prompt Tuning
Fine-tune的策略
在下游任务上微调大规模预训练模型已经成为大量 NLP 和 CV 任务常用的训练模式。然而,随着模型尺寸和任务数量越来越多,微调整个模型的方法会储存每个微调任务的模型副本, 消耗大量的储存空间。尤其是在边缘设备上存储空间和网络速度有限的情况下,共享参数就变得尤为重要。
一个比较直接的共享参数的方法是只微调部分参数,或者向预训练模型中加入少量额外的参数。比如,对于分类任务:
●Linear:只微调分类器 (一个线性层), 冻结整个骨干网络。
● Partial-k:只微调骨干网络最后的 k 层, 冻结其他层[2][3]。
● MLP-k:增加一个 k 层的 MLP 作为分类器。
● Side-tuning[4]:训练一个 “side” 网络,然后融合预训练特征和 “side” 网络的特征后输入分类器。
● Bias:只微调预训练网络的 bias 参数[5][6]。
● Adapter[7]:通过残差结构,把额外的 MLP 模块插入 Transformer。
基于 Transformer 的模型在大量 CV 任务上已经比肩甚至超过基于卷积的模型。
Transformer 与 ConvNet 比较:
Transformer 相比于 ConvNet 的一个显著的特点是:它们在对于空间(时间)维度的操作是不同的。
● ConvNet:卷积核在空间维度上执行卷积操作,因此空间内不同位置的特征通过卷积(可学习的)操作融合信息, 且只在局部区域融合。
● Transformer:空间(时间)维度内不同位置的特征通过 Attention(非学习的)操作融合信息,且在全局上融合。
Transformer 在特征融合时非学习的策略使得其很容易的通过增加额外的 feature 来扩展模型。
爱吃牛油果的璐璐:万字长文全面解析transformer(二更,附代码实现)9 赞同 · 0 评论文章
NLP中基于Prompt的fine-tune
● Prefix-Tuning
● Prompt-Tuning
● P-Tuning
● P-Tuning-v2
更多详解请看:
爱吃牛油果的璐璐:大模型炼丹术:大模型微调的常见方法14 赞同 · 2 评论文章
CV中基于Prompt的fine-tuning
分类
Visual Prompt Tuning[8]
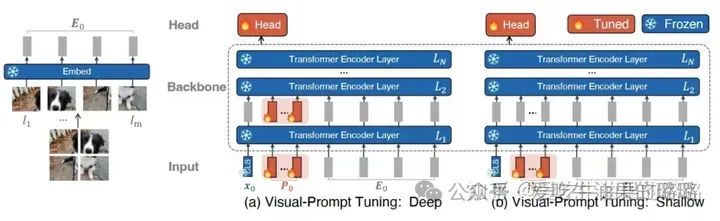
Visual Prompt Tuning
● VPT-Shallow
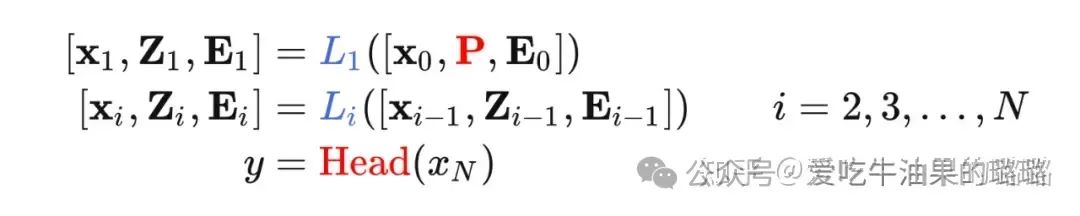
● VPT-Deep
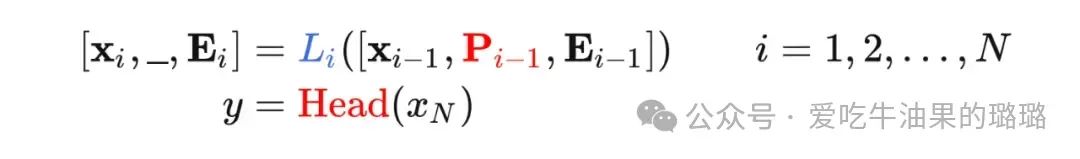
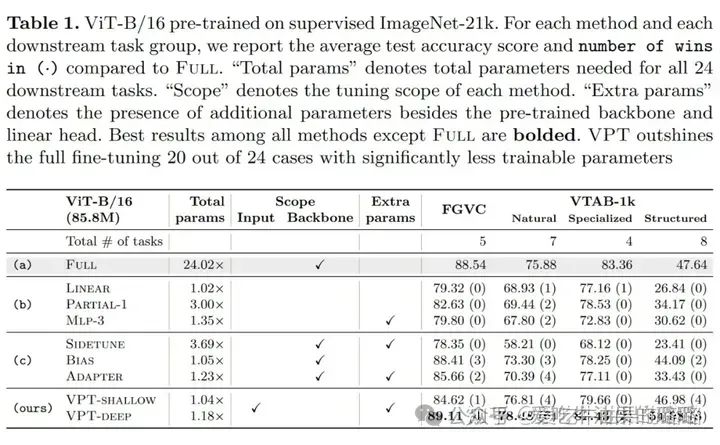
VPT Results
持续学习
Learning to Prompt for Continue Learning[9]
引入一个 prompt pool,对每个 input,从 pool 中取出与其最近的 N 个 prompts 加入 image tokens。input 和 prompts 距离的度量通过计算 input feature 和每个 prompt 的 key 的距离来得到,这些 key 通过梯度随分类目标一起优化。
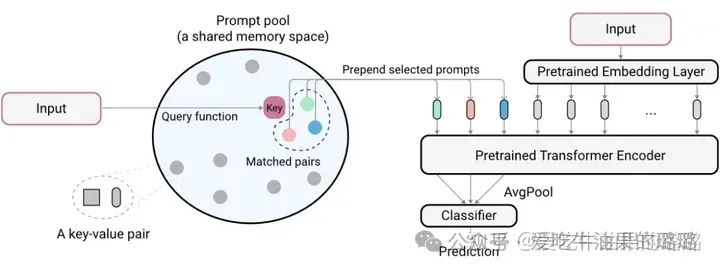
L2P
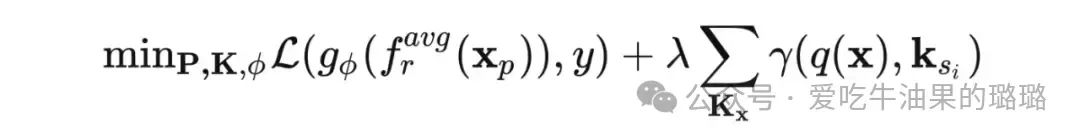
注意,最后使用 prompt 来分类。
多模态模型
Vision-Language Model: Context Optimization (CoOp)[10]
多模态学习的预训练模型。比如 CLIP,通过对比学习对齐文本和图像的特征空间。
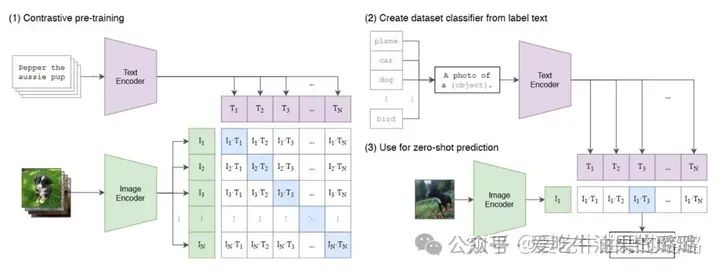
CLIP
选择不同的文本 prompt 对于精度影响较大。

Prompt engineering vs Context Optimization (CoOp)
把人工设定的 prompt 替换为 learnable 的 prompt:
●[CLASS] 放在后面:

● [CLASS] 放在中间:
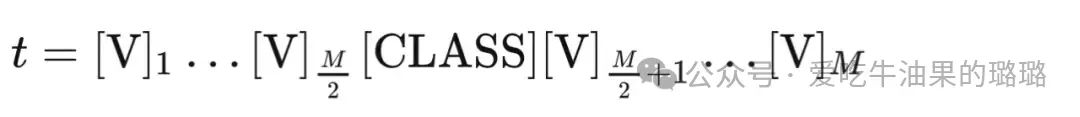
Prompt 可以在不同类之间公用,也可以为每个类使用不同的 prompts(对于细粒度分类任务更有效)。

Learning to Prompt for Vision-Language Model
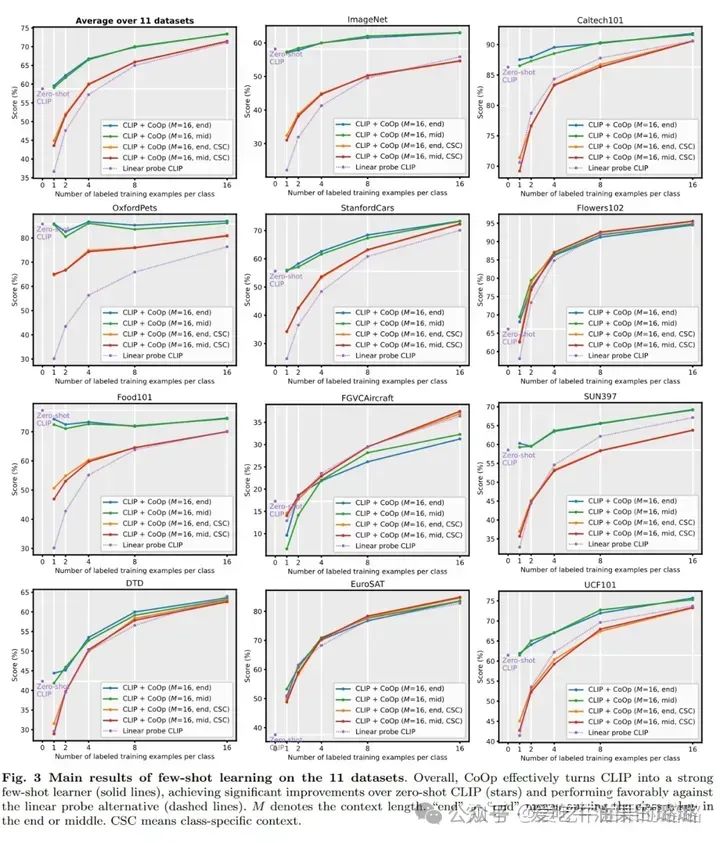
Learning to Prompt for Vision-Language Model
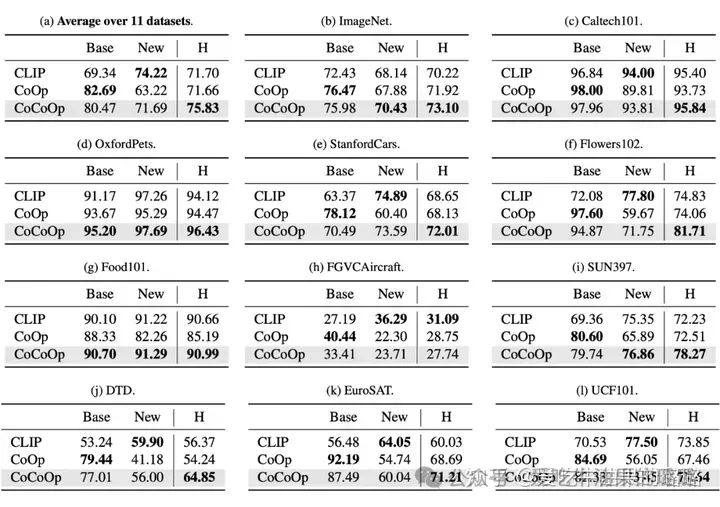
Conditional Prompt Learning for Vision-Language Models[11]
CoOp 在泛化到新的类别上时性能不好。

To learn generalizable prompts
所以把 prompt 设计为 instance-conditional 的。
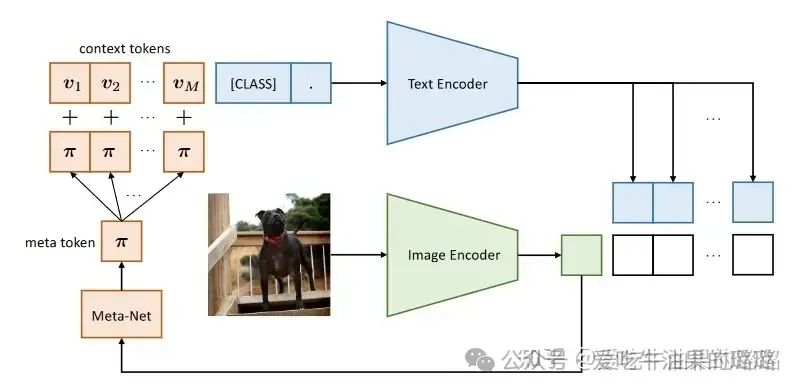
Example prompt structure
为 prompt 加上一个跟当前图像相关的特征以提高泛化性能。具体来说,先用 Image Encoder 计算当前图像的 feature,然后通过一个 Meta-Net 把 feature 映射到 prompt 的特征空间,加到 prompt 上面。
域适应
Domain Adaptation via Prompt Learning[12]用 prompt 来标识 domain 的信息。

Example prompt structure
通过对比学习解耦 representation 中的 class 和 domain 的表示。
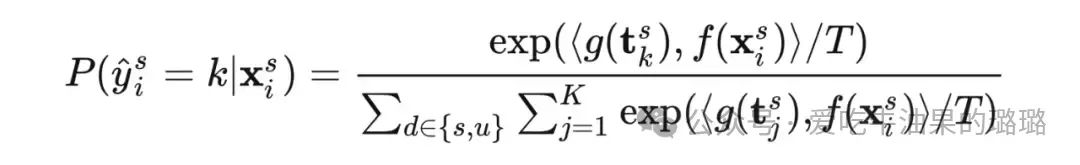
Domain Adaptation with Prompt Learning
Prompt-tuning 和Prompt Engineering 区别和联系
Prompt Engineering
提示工程,也叫提示模板工程(prompt template engineering),该过程使用人工或算法的方式为每个任务寻找最适合的模板。
首先要考虑的是提示的形状(prompt shape),也就是 [z] 在模板中的位置,若在中间,则为 cloze prompt,即完形填空式提示,若在末尾,则为 prefix prompt,即前缀型提示,选择何种形状取决于要解决的任务以及使用的模型。如果是生成型的任务,或者使用的是自回归的语言模型(auto-regressive LM),则通常使用前缀提示,因为由前缀预测 answer 的过程符合生成的本质,即从左到右的语言生成。
接下来需要考虑提示的设计,分为人工模板设计和自动模板设计。人工设计存在两个主要问题:1)过度依赖于人的专业知识及经验,2)经验丰富的设计者也有可能错过最优提示。为了弥补人工设计的不足,许多研究者提出自动设计模板的方法,又可以分为离散提示和连续提示,离散提示仍然是文本串,即在离散空间内(LM 的字典空间内)搜索模板,但有时搜索到的文本连人类也无法解读, 而连续提示可以直接被表示为LM的编码空间(embedding space)的向量,即搜索空间是连续的,不限定取值空间是为了更好的为任务服务。
Prompt-tuning
Fine-tune 范式是通过设计不同的目标函数,使得 LM 去迁就下游任务,但是与之相反,PL 是通过重塑下游任务使之迁就 LM,但本质上两种范式的目的都是为了拉近 LM 和下游任务之间的距离,此外,如下图所示,论文[8]中也对二者进行了比较,pre-train and fine-tune 范式下每一个任务都需要维护一个模型,难以进行领域迁移,小样本场景下效果不佳,对预训练的 LM 利用效率低下。另一方面,随着 LM 模型 size 的增大,fine-tune 的成本也越来越高,相较之下,Prompt的提出有可能让这些问题得以解决。以一个 “T5 XXL” LM 来说,每一个使用fine-tune的任务都需要撬动11,000,000的参数,但是使用P-tuning的方法,每个任务仅需要20,480个参数,减少了5个数量级的参数量[12]。
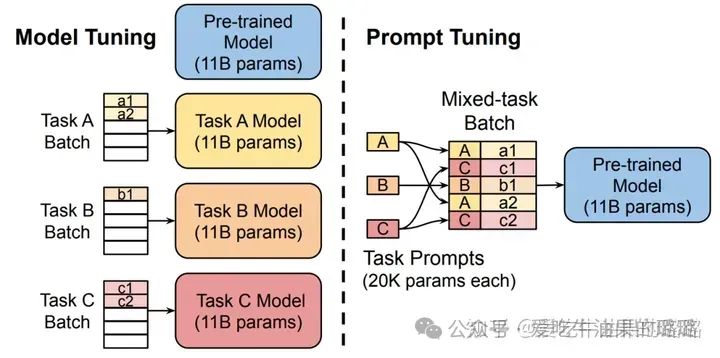
Pre-train and fine-tune 与 Prompt tuning 的对比(Lester B, et al. 2021)
提示学习的本质以及与其他学习方法的对比
A. 数据增强(Data Augmentation),是指通过在现有数据上进行修改或操作,从而增加训练数据的数据量的一种技术,论文Le Scao T, Rush A M. How many data points is a prompt worth?[C]//Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021: 2627-2636.发现通过在分类任务上添加提示,可以达到平均增加100个数据点的效果,因此可以认为在下游任务下使用提示隐式地进行了数据增强。
B. 有监督的注意力机制(Supervised Attention),注意力机制的初衷是认为从长文本,图像,或知识库中抽取信息时,将注意力放在重要的信息上十分关键,而 supervised attention 旨在对注意力提供监督,因为完全由数据驱动的注意力可能会过度拟合到某些组件。从这个角度来看,提示学习和有监督的注意力机制的核心思想都是通过一些线索或提示去抽取显著特征。有监督的注意力机制通过使用额外的损失函数去学习人工标注出来的 golden attention,提示学习可能借鉴了相关文献。
C. 受控生成(Controlled Generation),受控生成旨在通过引入输入文本以外的指导(例如, 风格,长度设定,和领域标签等)来控制文本的生成。这些用于内容控制的指导可以是关键词,三元组,或者短语或句子,某种程度上,一些提示学习方法也是一种可控生成,其中提示通常用于指定任务本身。两种方法的共同点是:1)在输入添加额外信息以引导更好的生成,且这些额外信息都是可以学的参数;2)可以把使用基于 seq2seq 的 LM(例如 BART)的受控生成视为一种输入依赖的提示学习。
D. 小样本学习 (Few-shot Learning ),少样本学习方法旨在学习一个能适应少样本场景的机器学习系统,许多方法,例如 model agnostic meta learning,embedding learning,和 memory-based learning,都在为实现这一目标而努力。提示方法可以被认为是另一种实现 few-shot learning 的方法,与其他方法相比,提示学习直接将几个有标注的样本预置到当前处理的样本中,即使没有参数调整也能从 LM 中抽取知识。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









