







大模型的多轮,我们一般想到的方案都是比较大胆地把历史记录都交给大模型让大模型来做生成,这个在比较自由、开放的聊天中,肯定是有效的,但是在实际场景中,我们往往希望模型能够在一定程度控制对话的流程,我是在找类似的文章的。
这篇文章应该是我最近找的比较贴切的一篇了,所以做了精读,任务型对话是各种多轮对话里最要求主动控制对话流程的一类,因此这篇文章里面的研究应该对我想研究的部分应该也有不少用的。
论文:
- Are Large Language Models All You Need for Task-Oriented Dialogue?
- https://arxiv.org/abs/2304.06556
懒人目录:
- 关键贡献。
- 流程任务架构。
- 方案细节。
- 实验解析和分析
- 文章结论。
- 个人思考。
关键贡献
文章验证了大模型在任务型对话中多个模块中起到的作用,主要有如下结果:
- 建立了一套基于大模型的任务型对话pipline。
- 大模型在状态跟踪(DST,dialogue state tracking)上的效果并不好。
- 但给定对话状态,大模型的生成却具有更好的效果。
- 在few-shot、zero-shot等场景,大模型具有很高的利用价值。
流程任务架构
首先先来看看作者设计的整个流程架构:
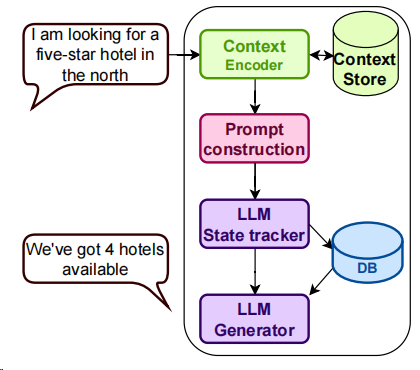
在这个架构中,模块分成了4个,分别是上下文表征、prompt构造、大模型对话状态跟踪、大模型生成这4个模块,而对于任务型对话,比较关键的应该是对话状态跟踪和生成这两个模块,即解决“目前聊到什么程度”和“应该说什么”的问题,相比单轮的对话,多轮更多就是考虑这两个问题了。
另外值得注意的是,作者重点强调了,此处是不做模型微调的,因为要考验的是模型的开箱即用能力。事实也确实需要如此,在很多场景下,我们没有条件去微调模型,无论是数据、机器还是别的问题,因此我自己也挺认可作者在这块的尝试,需要分析清楚,大模型在什么方面的能力较强,适合做什么任务,了解其边界。
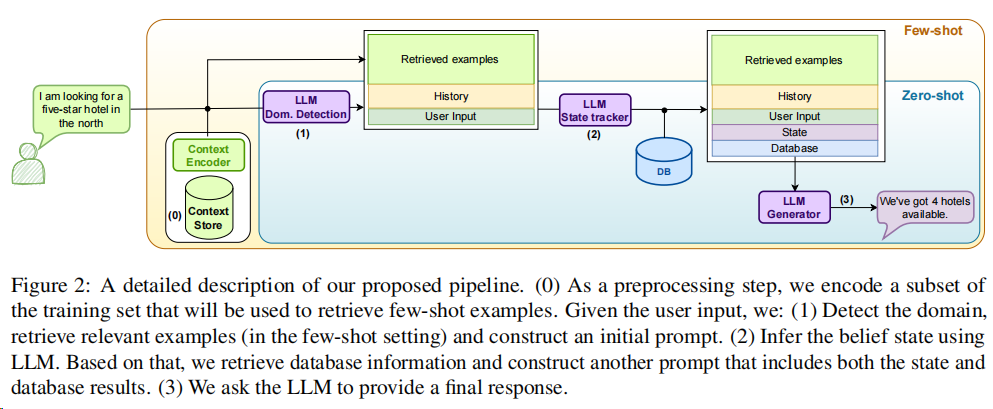
此后,作者又给出了更为详细的流程:
- 首先,会编码一批训练数据,这些数据是用于进行few-shot的样本。
- 意图/领域识别,并根据识别结果构造原始的prompt。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1000
1000

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









