






面试题
如何根据模型参数量估计大模型微调和推理所需显存?
标准答案
为什么需要根据需要模型参数量估计需要的显存?
估计模型参数量对于确定所需的显存是非常重要的,原因如下:
- 模型存储: 每个模型参数(权重和偏置项)都需要一定的存储空间。在训练过程中,这些参数会被更新,并且需要在显存中保存最新的值以便后续计算使用。
- 激活值存储: 在前向传播过程中,每一层的输出(激活值)也需要被暂时存储起来,以便在反向传播时用于计算梯度。这意味着除了模型参数外,还需要额外的空间来存储每一步的中间结果。
- 梯度存储: 在反向传播阶段,每个参数都会有一个对应的梯度,这些梯度也需要存储在显存中,直到它们被用来更新参数为止。
- 批处理大小: 训练时使用的批处理大小也会影响显存需求。较大的批处理可以提高训练效率,但会占用更多的显存,因为需要同时处理更多的样本数据。
- 优化器状态: 一些优化算法(如Adam或RMSprop)会在每个参数上维护额外的状态(如移动平均值等),这些状态同样需要存储空间。
- 其他开销: 除了上述主要因素之外,还有一些其他的开销,比如模型架构元数据、临时变量以及其他运行时需要的数据结构。
因此,准确估计模型参数量可以帮助我们合理配置硬件资源,确保训练过程顺利进行而不会因显存不足而导致训练失败或效率低下。特别是在使用高性能GPU进行大规模训练时,合理分配显存尤为重要。
如何计算大模型微调所需显存
要计算大型模型微调所需的显存,我们需要考虑训练过程中涉及的各种组成部分及其占用的显存。以下是根据给定内容总结的关键点:
显存组成部分
-
模型权重:
-
- 每个浮点数(float32)占用4字节的空间。
-
优化器:
-
- AdamW:对于每个参数,需要额外存储两种状态(动量和二阶矩),每个状态占用8字节,这说明优化器所占用的显存是全精度(float32)模型权重的2倍。
- bitsandbytes优化的AdamW:每个参数需要额外存储的状态占用2字节,即全精度模型权重的一半。
- SGD:优化器状态占用的显存与全精度模型权重相同。
-
梯度:
-
- 全精度(float32)模型权重所占用显存与梯度所占用显存相同。
-
计算图内部变量(通常称为前向激活或中间激活):
-
- 这些变量在PyTorch、TensorFlow等框架中用于执行前向和后向传播,需要存储图中的节点数据,这部分显存需求在运行时才能确定。
显存需求计算
-
模型权重:每个参数占用4字节。
-
优化器状态:
-
- 对于AdamW,每个参数需要额外存储两个状态(动量和二阶矩),每个状态占用8字节,总计额外占用16字节。
- 对于bitsandbytes优化的AdamW,每个参数需要额外存储的状态占用2字节。
- 对于SGD,优化器状态占用与模型权重相同的显存。
-
梯度:占用与模型权重相同的显存。
-
计算图内部变量:这部分显存需求取决于具体的前向传播过程,通常在运行时才能确定,可以通过比较不同批次的显存使用差异来大致估算。
示例计算
- 假设一个7B参数的全精度模型,每个参数占用4字节,则模型权重占用 (7 \times 10^9 \times 4) 字节 = 28GB。
- 使用AdamW优化器时,优化器状态占用 (7 \times 10^9 \times 16) 字节 = 112GB。
- 梯度占用与模型权重相同的显存,即28GB。
- 因此,总显存需求大约为 (28 + 112 + 28) GB = 168GB。
- 但是,考虑到实际情况中的显存需求通常是模型权重的3-4倍,那么对于7B参数的模型,显存需求大约为 (28 \times 3) GB 到 (28 \times 4) GB,即78GB到104GB。
优化思路
为了减少显存需求,可以采取以下几种策略:
- 量化:使用更少的位数表示权重和梯度,例如使用8位或更低精度的表示。
- 模型切分:将模型分割成多个部分,分别在不同的设备上进行计算。
- 混合精度计算:使用混合精度训练,例如FP16或BF16,以减少显存占用。
- Memory Offload:将部分数据卸载到主内存或其他存储设备,减少显存占用。
主流的计算加速框架如DeepSpeed、Megatron等已经实施了上述的一些技术来降低显存需求。
如何计算大模型推理显存
所仅考虑推理阶段,计算所需的显存是比较简单些:
一般情况下,大多数模型的参数类型为 float32,每个参数需要占用4字节的空间。
因此我们可以这样计算:每10亿个参数大约占用4GB的显存(实际计算结果应为 GB,但为了简便起见,可以近似为4GB)。
eg:以 LLaMA 模型为例,其参数量为 7,000,559,616,所以以全精度加载LLaMA 模型参数所需的显存容量为:
这个数值有些挑战性,因为专为游戏设计的 GeForce 系列显卡最高也只有 24GB 显存,这意味着这类显卡无法运行此模型。因此,至少需要使用 Tesla 系列或其他更高规格的显卡才能满足运行此类大模型的需求。
我们可以通过使用半精度(FP16 或 BF16)来加载模型,这样每个参数只需占用2字节的空间,所需显存容量就能减少一半,降至13.04GB。
使用半精度是一个很好的选择,虽然显存需求减少了一半,但由于精度降低,模型性能可能会略有下降,但通常仍在可接受的范围内。
- 提问:如何在一张8GB显存的3070显卡部署LLaMA 模型?
如果想在一张8GB显存的3070显卡部署LLaMA 模型,可以通过采用 int8 精度进一步减少显存需求,降至6.5GB,但模型效果会进一步下降。
- 提问:那如果我的电脑显卡特别 low!!! 只有一张 显存为4GB 的 GTX 960 显卡呢?
不怕,你只需要使用 int4 精度来运行,显存需求再次减半,降至3.26GB。当年我花费了上千元购买这块显卡,虽然现在只能勉强运行70亿参数级别的大模型进行推理,但也算是跟上了潮流。
目前 int4 是最低的精度级别,如果继续降低精度,模型的效果就难以保证了。
以下是百川给出的不同精度量化结果的对比:
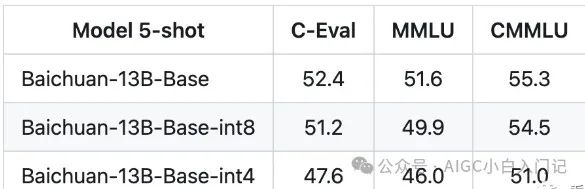
注:上述计算只考虑了将模型加载到显存中的情况,实际上在模型运算时还需要为一些临时变量分配空间,比如在进行 beam search 时。因此,在真正进行推理时,请记得预留一些缓冲空间,否则很容易导致显存溢出(OOM)。
- 提问:我的电脑内存很大,但是就是没有显存可以用怎么办?
如果显存仍然不足,可以采用 Memory Offload 技术,将部分显存内容转移到主内存中,但这会显著降低推理的速度。

如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。















 1725
1725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









