






本期摘要
嵌入(Embeddings)是机器学习领域中的一个概念,主要用于将高维的数据转化为低维空间,以便于算法更好地处理和理解数据。嵌入通常用于将离散的、高维的特征转换为连续的、低维的向量表示。
本文将以经典的嵌入模型 word2vec 为例介绍其训练过程,embedding 过程,通过阅读,您将理解一段文本是如何转化为 n 维向量的。
01
word2vec
Word2Vec 是一种用于生成词嵌入的算法,它基于分布式假设,即假设上下文相似的单词在语义上也是相似的。Word2Vec 有两种主要的训练模型:连续词袋模型(Continuous Bag of Words,CBOW)和跳字模型(Skip-gram)
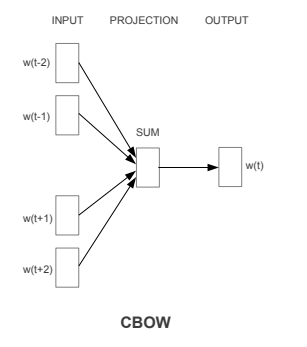
**CBOW:**通过给定一个词的上下文单词,来预测中心词,模型的输入是上下文词的词向量,输出是中心词的词向量。CBOW 的训练目标是最大化预测中心词的概率,从而得到能够很好地表示上下文语境的词向量。
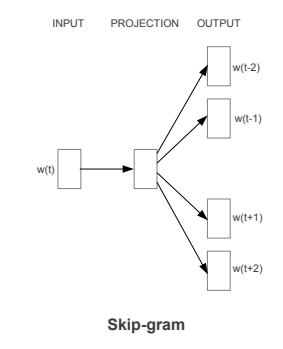
Skip-gram:Skip-gram 的思想与 CBOW 相反,它通过给定一个中心词,来预测其周围的上下文词。模型的输入是中心词的词向量,输出是上下文词的词向量。Skip-gram 的训练目标是最大化预测上下文词的概率,从而得到能够很好地捕捉词语语义的词向量。
02
Embedding过程
训练好的word2vec模型有一张词表,词表中包含训练数据中所有单词所对应的词向量,当使用word2vec将句子转化为向量时,一种常见的方法是将句子中所有单词的词向量取平均或加权平均。这可以帮助将整个句子的语义信息编码到一个向量中。大致步骤如下
-
获取每个单词的词向量,将句子中的每个单词都映射到Word2Vec模型中的词向量空间,得到对应的词向量。
-
计算平均向量:将所有单词的词向量取平均,得到句子的平均向量。
假设目前有一个已经训练好的word2vec模型,模型的输入为“我喜欢苹果”,分词向量表如下。请注意这里的词向量维度为3,实际词表中的维度远远大于这个值。
| 单词 | 词向量 |
|---|---|
| 我 | [0.2, 0.3, 0.5] |
| 喜欢 | [0.4, 0.1, 0.8] |
| 苹果 | [0.6, 0.7, 0.9] |
接下来我们使用词向量平均的方法,将这个句子转化为向量。设我的词向量为α1 ,喜欢的词向量为α2 ,苹果的词向量为α3

这样,“我喜欢苹果” 这个句子就被转化为了一个向量 [0.4, 0.367, 0.733],其中每个维度代表了句子在对应语义维度上的平均值。这个向量可以用于表示句子的语义特征。
03
计算向量之间相似性
在计算向量之间的相似性时,常用的方法包括余弦相似度(Cosine Similarity)以及欧几里得距离(Euclidean Distance)
-
余弦相似度衡量了两个向量之间的夹角,取值范围在-1到1之间。相似的向量夹角接近0度,余弦相似度接近1,表示相似性高;夹角接近180度,余弦相似度接近-1,表示相似性低;夹角为90度,余弦相似度接近0,表示两向量正交,无明显相似特征。
-
欧几里得距离是计算两个向量之间的距离,值越小表示越相似,值越大表示越不相似。
以余弦相似度为例,假设我想要得到在向量数据库中与我的问题最接近的文本,首先我需要对我的问题做向量化,假设用word2vec向量化后的问题向量为β1 = [0.3, 0.7, 0.5],最接近的文本向量为β2 = [0.4, 0.6, 0.9]
1、首先对β1 以及 β2 做内积,以及分别取模
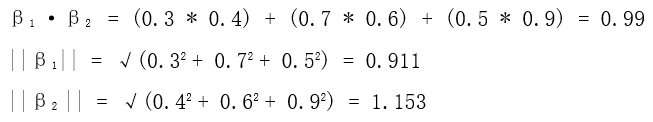
2、 然后使用余弦相似度公式计算β1 以及 β2 做相似度

这个计算出的余弦相似度值接近于1,说明向量 β1 和向量 β2 在方向上非常相似,夹角很小。这表示向量 β1 和向量 β2 在某种意义上是相似的,具有一定的语义相关性。
04
word2vec模型的训练过程
之前提到模型词表中已经存储了词向量,因此我们句子可以被分词之后到词表中找到对应词的词向量做加权平均得到句子的向量表示,那么词表中的词向量是从哪来的?接下来我将介绍word2vec模型的训练过程,从而解释这个问题
1、准备数据
将文本分解为词语序列,构建词汇表,并为词汇表中的每个词分配初始的词向量。这些初始的词向量通常是随机的,这些随机初始化的词向量没有任何具体语义含义,它们只是作为模型训练的起点。随机初始化词向量的原因是,在开始训练之前,模型并不知道每个词汇的语义信息。通过随机初始化,模型有了一个初始状态,然后通过训练过程逐步调整这些词向量,使它们能够捕捉到词汇之间的语义关系。随机初始化的词向量可以是服从某种分布的随机数,比如均匀分布或正态分布。这些初始向量会在训练过程中逐渐调整,以使模型在预测上下文词汇时更准确。一个好的embedding模型拥有海量(GB,TB,PB)的文本作为训练数据,打个比方,同一个词出现的句子越多,在之后做embedding时越接近真实语义。
2、上下文,中心词对
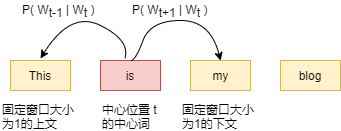
对于一段文本,从第一个词开始以固定的窗口大小对文本进行切分,计算每个词出现的概率,每个词会拥有两个概率表示,一个为作为中心词出现的概率,另一个为作为上下文时出现的概率对应的,我们用两个词向量表示词表中的每个词,一个表示该词作为中心词时,另一个表示该词作为上下文时。
3、计算概率分布
计算预测概率分布时使用了softmax函数。这个函数将模型的输出转化为概率分布,以便用于计算损失并进行优化。模型会根据输入的中心词或上下文词的词向量,计算每个词汇成为目标的概率。然后,使用softmax函数对这些概率进行归一化处理,确保它们形成一个合理的概率分布。这个概率分布表示给定上下文条件下,每个词汇成为中心词或上下文词的概率。这个分布会被用于计算损失函数(通常使用交叉熵损失),进而用于优化模型的参数,使得模型能够更好地预测实际的上下文或中心词。

假设词向量为:
- Apple: [0.2, 0.4]
- Banana: [0.5, 0.7]
- Orange: [0.3, 0.6]
在Skip-gram模型中,我们要计算给定上下文词 “apple” 的情况下,每个词汇成为中心词的概率分布。我们可以使用 softmax 函数来计算这些概率。
首先计算内积
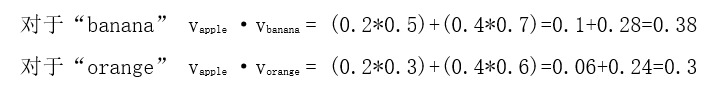
使用softmax函数计算概率

在以apple为上下文的情况下,“banana”和“orange”成为中心词的概率分布,从结果可以得知,“banana”成为中心词的概率比较高。
4、损失函数梯度更新
使用模型的输出概率分布和实际上下文或中心词汇,计算损失,通常使用交叉熵损失函数。使用损失函数计算模型的梯度,然后使用优化算法(如梯度下降)来更新词向量,使预测更接近实际。
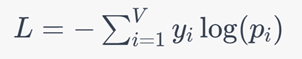
其中V是词汇表大小,yi 是实际目标概率分布中词汇wi的概率(如果词汇是目标,则为1,否则为0),pi 是模型预测的概率分布中词汇wi的概率。使用损失函数的梯度来更新模型的参数,通常采用梯度下降等优化算法。目标是通过反向传播算法调整模型的参数,使得损失函数最小化。
5、迭代训练
重复上述步骤多次,迭代训练模型。随着训练的进行,词向量会逐渐调整以更好地捕捉词汇之间的语义关系。
训练自己的word2vec模型
详情请参阅Confluence word2vec模型训练
(https://confluence.digitalchina.com/x/XUHJAg)
05
总结
2013年Google员工Tomas Mikolov等人提出了word2vec。用于在计算机中处理和分析文本数据。这个过程涉及将文本中的单词、短语或句子转化为向量表示,使得计算机能够处理和比较文本信息。Word2Vec利用深度学习模型,通过预测上下文词汇来生成词向量,从而捕捉单词之间的语义关系。这种向量表示使得文本信息能够在计算机中进行数学计算和分析,为自然语言处理任务提供了基础。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。















 3001
3001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









