









Tensorflow2.0 YOLO篇之算法原理介绍
YOLO篇链接
YOLO篇是记录最近研究YOLO算法的一个过程,这一篇会从YOLO原理讲起,一直到自己搭建数据集,去搭建YOLO网络并最终完成的一个过程
什么是目标检测?
检测图片中目标所在的位置,以及图片所属的类别。在计算机视觉中我们处理的往往都是分类的任务,图片一般都是采集好的,图片中的信息都是比较单一的,但是在现实生活中人眼中说看的都是全景的图片,各种东西都是混在一起的,所以在进行识别之间需要先进行目标的检测,确定目标所在的位置

比如想要识别图中的狗,那么首先应该显示把狗从这个区域内分出来
目标检测算法的算法思路
先让我们回顾一下用卷积神经网络的使用
当我们使用卷积神经网络的时候,卷积神经网络会把我们的高宽给减少,通道数给增加。高和宽理解为每一个为位置点的信息,每一个channel上的信息理解为这个位置上的属性,通过网路的训练channel之间增加,h x w逐渐减少
到最后的每一个channel可以理解为某一个类别的代表属性,最后转化成每一个类别的概率输出
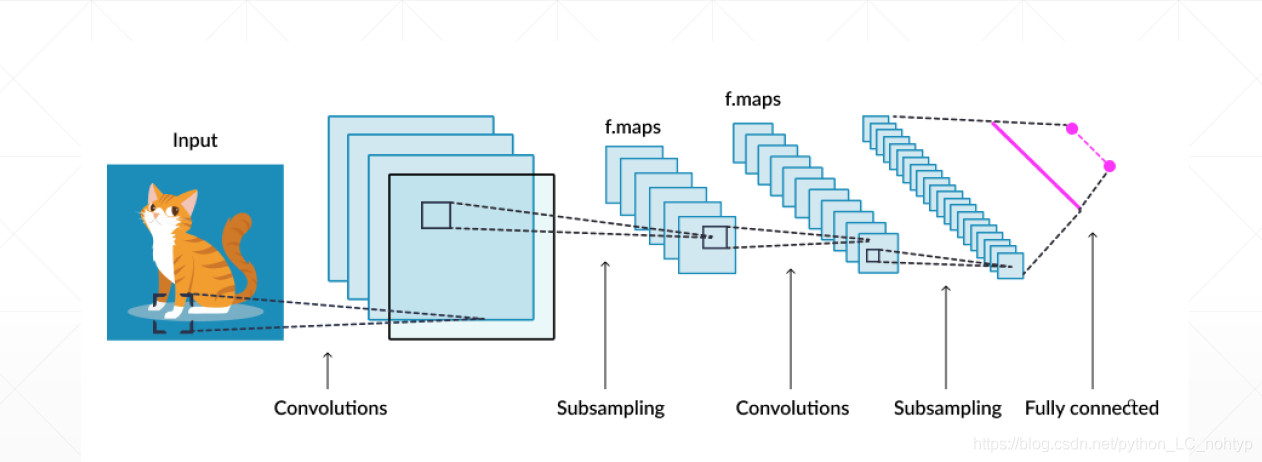
同时卷积网络还会保持一个空间上的位置关系

虽然在空间上的数量在减少,但是他保留了相对的位置关系。最后每一个点上的信息是可以映射回原图的,在Detection中最重要的是要检测出每一个位置对应的物体,所以对应的位置关系不能乱。基于这种保持相对位置关系的属性去设计一个卷积神经网络去预测哪个位置有没有相应的物体呢?

比如说这样一张图,我们通过我们设计的一个神经网络,最后图片对应7x7的网格。如何去检测一个位置有没有object呢?那上图举例,假如我们检测到一个像素点内有物体,我们就希望这个像素点有一个confidence这个confidence在0-1之间,你可以简单的理解这个就是概率,但其实这个并不是概率。这样我们就可以拿到一个output,那么我们要如何拿到target呢?output中保存了坐标信息(boxes),这样就可以在图片中构造出一个7 x 7的矩阵。在那对应的区域有没有object去写上0-1的confidence,这样我们就得到了一个target。
通过这样一种方法我们似乎就解决目标检测的问题,而且这种方法似乎并不是那么复杂。那么这种方法又有什么问题呢?
- 从原本的小像素点信息映射回图片的坐标信息并不是很精准
- 不知道框框对应的是什么类别
但是我们可以延续这个思路去完善我们的卷积神经网络,比如我们不知道框框内的内容是什么类别的,我可以在添加上分类的功能,这就是最初始的YOLO
YOLO发展史
YOLO全名You only look once 在 YOLO v1提出后YOLO的算法已经经过了几代的革新目前已经发展到了YOLO v4但是从YOLO v2以后的革新大多都是在工程方面的优化,如果想了解YOLO的本质建议先实现YOLO v2,完全理解YOLO v2之后,再看YOLO v3,v4会更加容易理解。
YOLO: You only look once
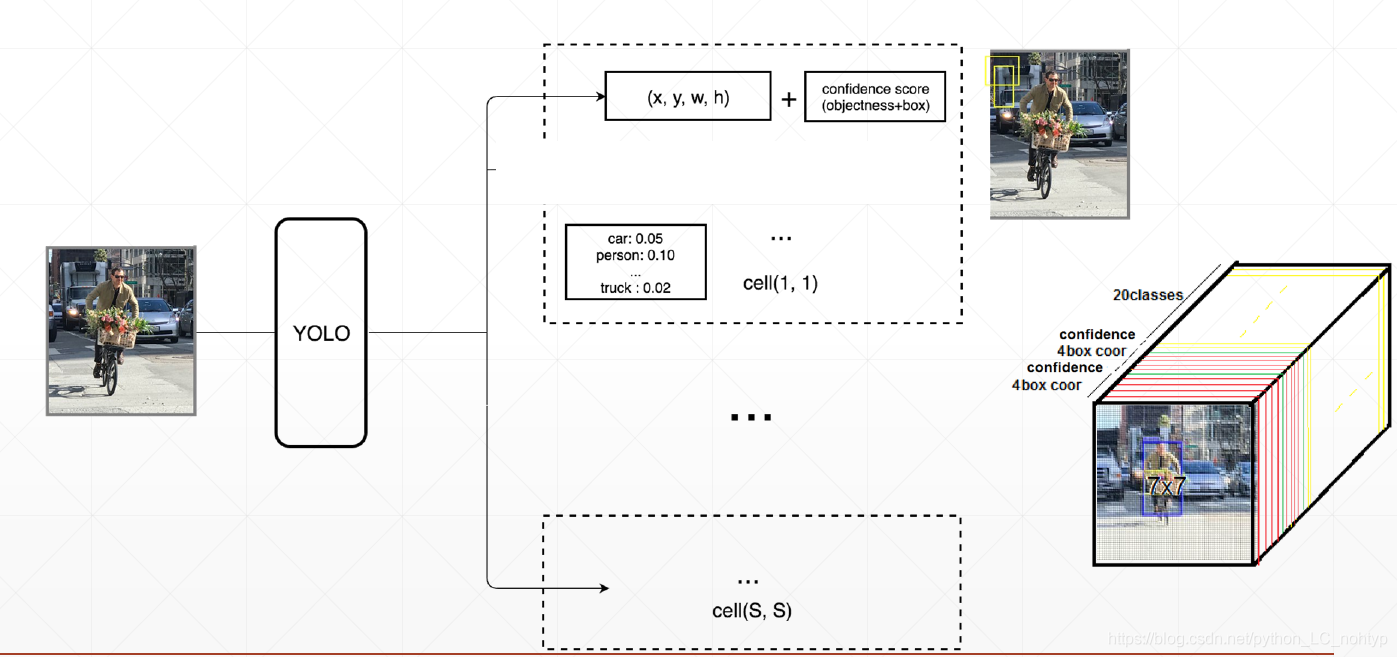
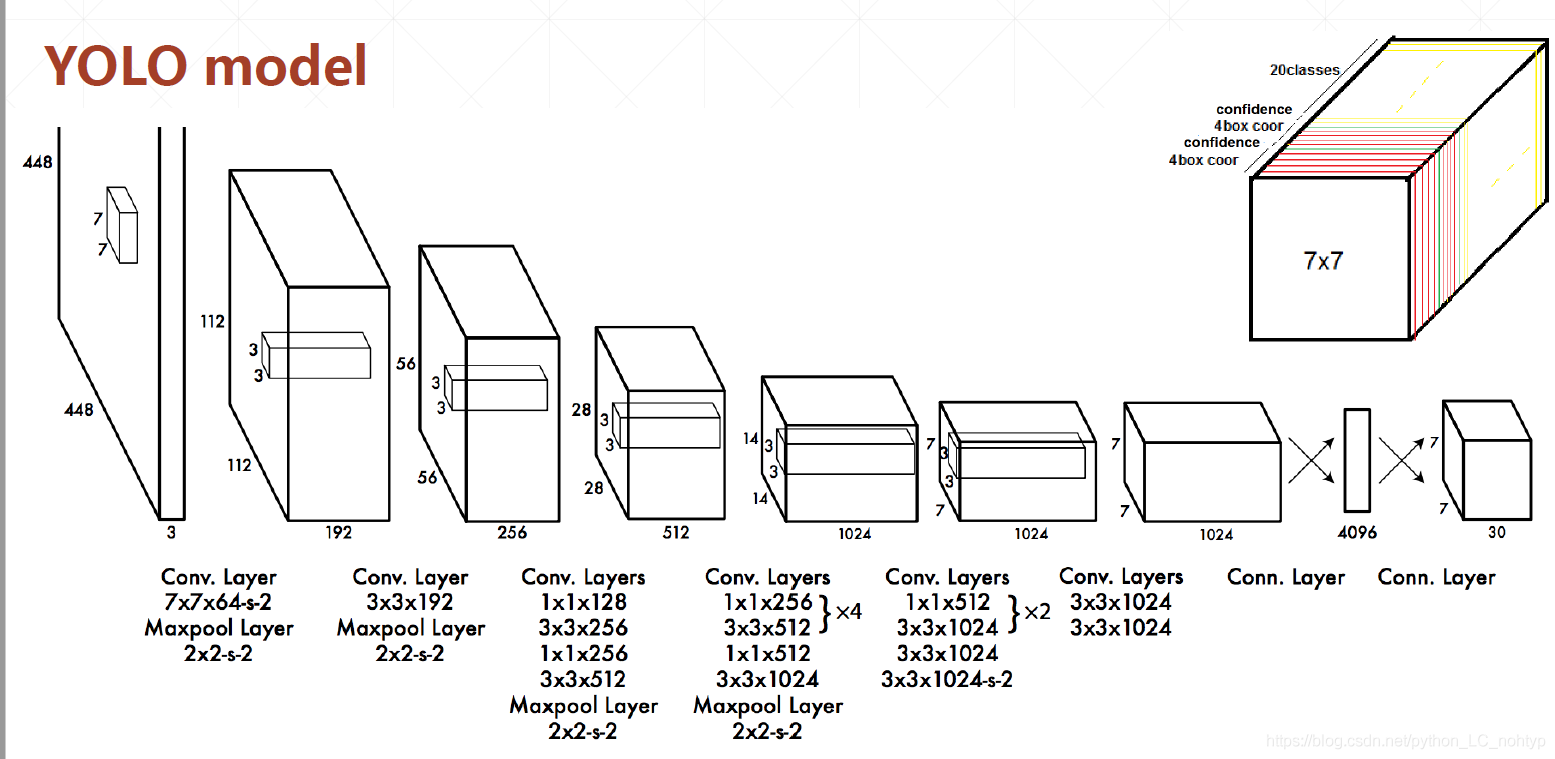
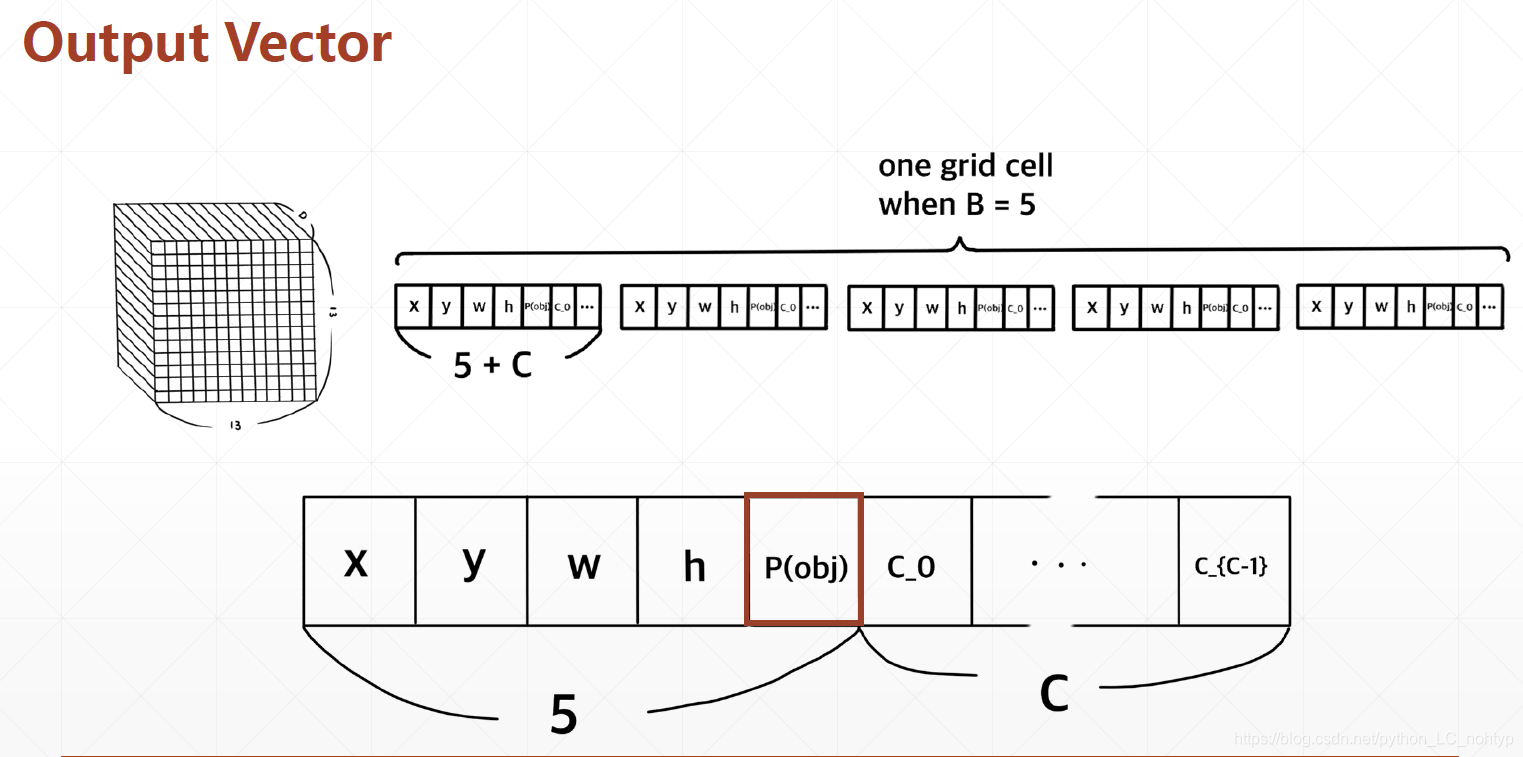
继续上面的思路,我们希望可以把(x,y,w,h,class)的信息全都预测出来。也就是网络输出出来位置信息外还要有每个类别的概率,这样的话我们其实就只要修改一点点,假设我们有20个未变那么我们的class的设计就是20(类别)+4(x,y,w,h)+1(confidence) = 25 建设输出的图片宽度和高度的下采样都是7那么输出张量的接口就是[7,7,25] 之前25里面只有confidence一个数值。
这里需要提一下在正式发表的论文中我们可以发现输出clsss的格式并不是20+5(假设有20个分类),而是20+5+5 这是出于工程上的一些优化这个5是另外一个box,这个box拥有相似的confidence,也就是说网络会同时发现有两个boxes,最后选择confidence较高的box。这个只是工程上的优化,如果一开始不理解,在自己实现的过程中也可以去掉
论文下载:
https://link.zhihu.com/?target=http%3A//arxiv.org/abs/1506.02640
代码下载:
https://github.com/pjreddie/darknet
Train YOLO
Compose GT boxes
构造x 和 y ,对应分类算法y的形状一般是0~9的或者0 ~ x的一个类别数的数值,而对于YOLO y是形状是一个[N,5] N 代表的boxes的一个数量。5是4+1 代表object的具体位置还有类别信息。这样是目标检测算法的一个比较复杂之处,相对来说这个y的值比较复杂也比较多样。
Forward
同时在训练的时候我们需要把[N,5] 变为 网络输出的target (x,y,w,h,confidence,one-hot)那么我们的target到底是怎么构造的呢?
原图上面有物体的地方,在映射的时候我们就把物体信息写进来信息的结构就是[x,y,w,h,confidence(1),one-hot],其他的没有物体的向量就写上一个0向量,这样我们的target就构造完成了
把图片输入我们设计的网络可以拿到网络的输出值

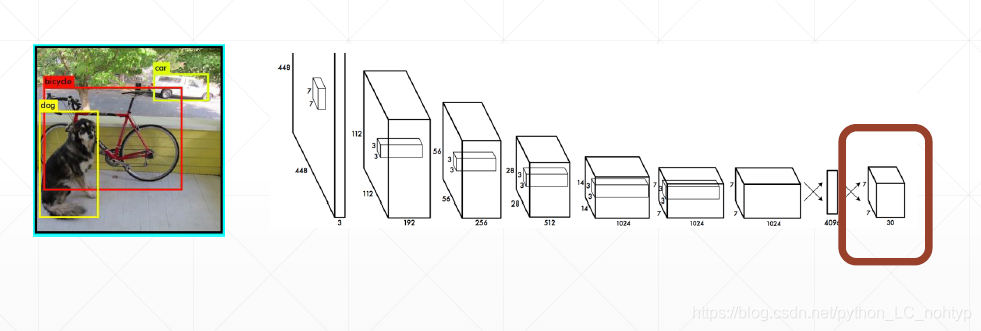
Loss
在拿到网络的输出后我们的误差有是怎么计算的呢?
我们拿到的target其实并不是30,而是25,因为输出的是20+5+5 ,网络只会选择最好的那个,我们就可以用target和pred来进行交叉熵计算也可以使用均方差,只需要计算预测值和真实值之间的距离,然后更加loss去更新我们的网络即可
最后我们还需要对我们得到的boxes进行一个筛选,给boxes设置一个阈值,还可以通过NMS进行筛选,最后就可以得到一个比较好的效果
这种算法,我们把它叫做Old YOLO或者叫做YOLO1.0的版本,后面我们还会说YOLO2.0

YOLO v2的对YOLO v1的优化
Improvements - 1
- BN的添加
- 全连接层的去除(全连接层会破坏位置的相对关系)
Improvements - 2
在YOLO v1中我们的位置信息x y w h 这些数据从理论上来说他们的范围在0到正无穷,输出的范围很大,就造成网络的多样性。这样在训练的初期target和pred的差别可能会非常大,loss就会非常的不稳定。那么我们如何给神经网络减负呢?
我们这样这样,我们不让你直接去预测这个框,我们给你几个标准框让网络计算和这个标准框之间的偏移。这就像猜物品的游戏,如果一个人随机的想一个物品让另一个人去猜,那么难度就会很大,但是如果告诉猜的人我想的物品就是几样物品中的一个,那么就会好猜很多
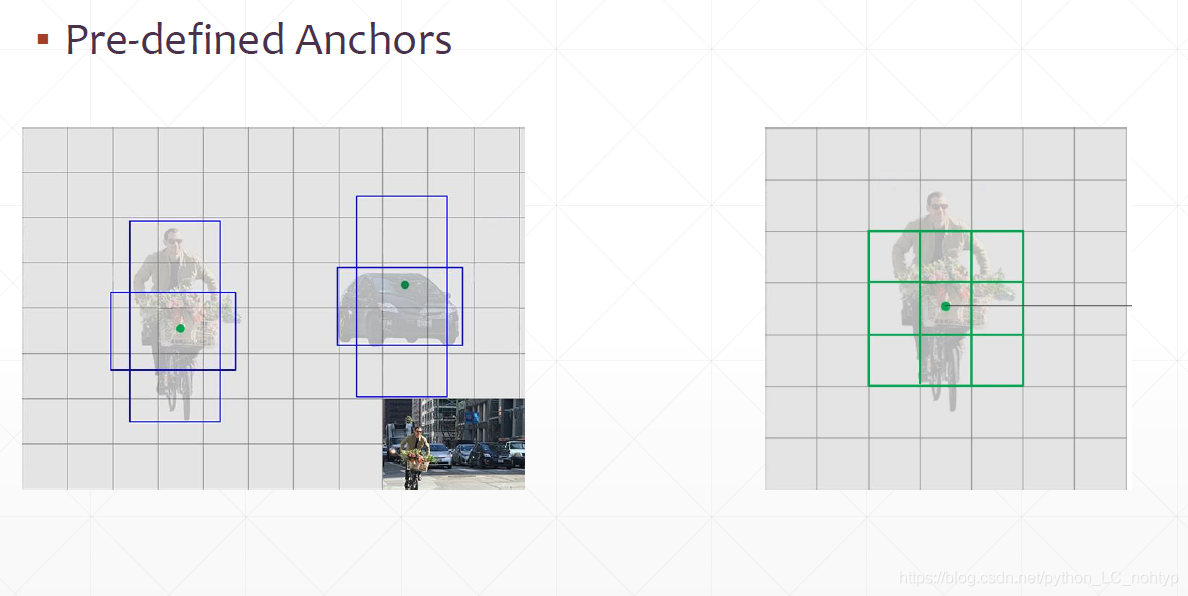
我们给的这个标杆就叫做锚点(Anchors)
那我们如何选择Anchors呢?
- 选择的Anchors要可以代表大部分盒子的维度关系
- 给几个呢?大概就选择这样的几种
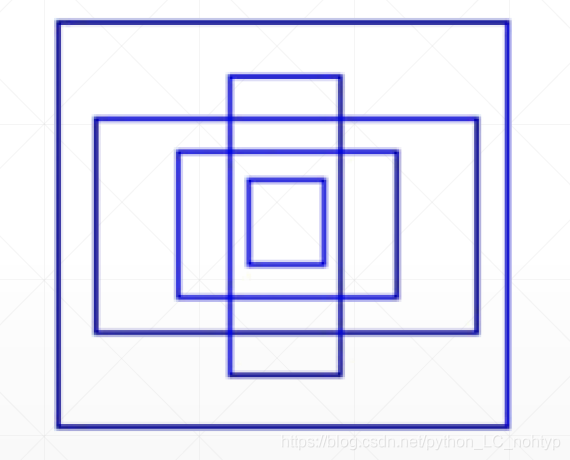
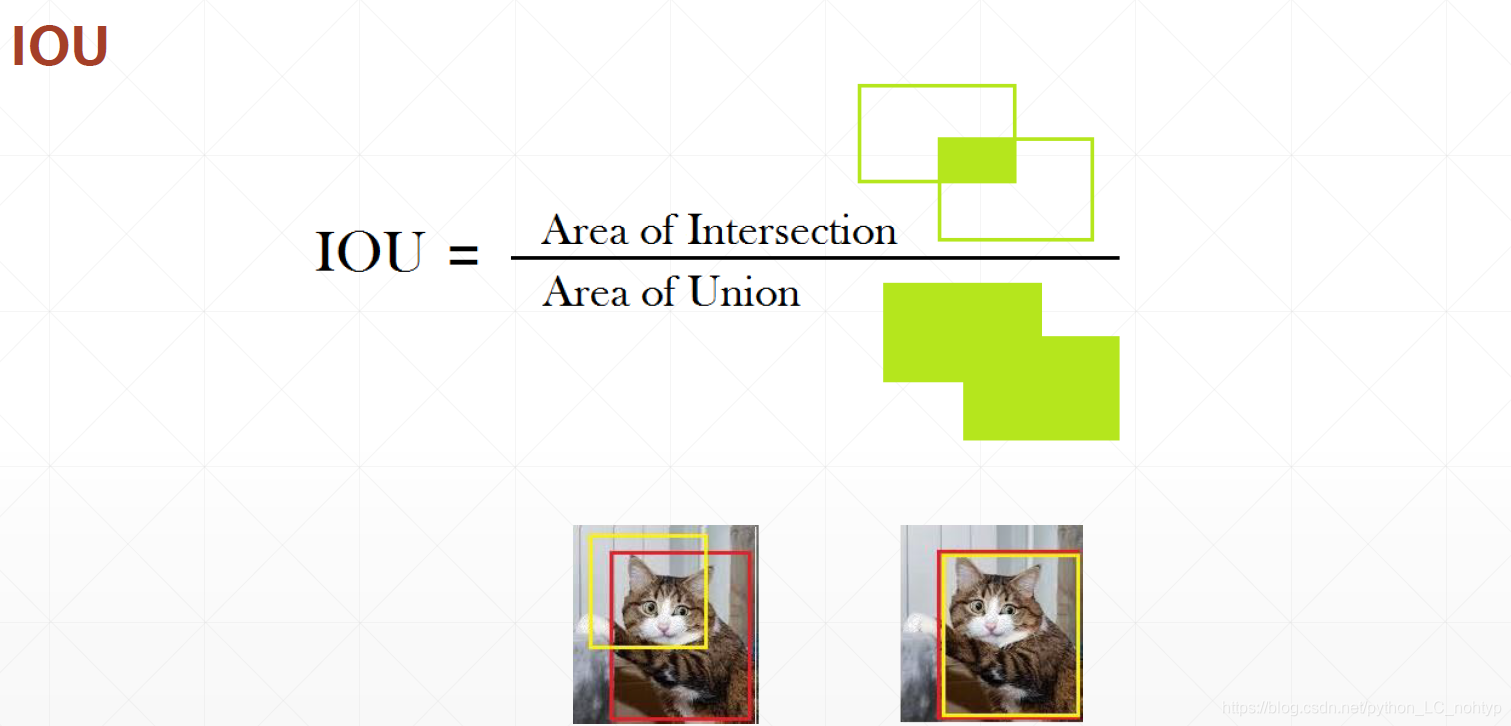
具体是哪个盒子有一个叫做IOU的指标,选择相似度最高的盒子
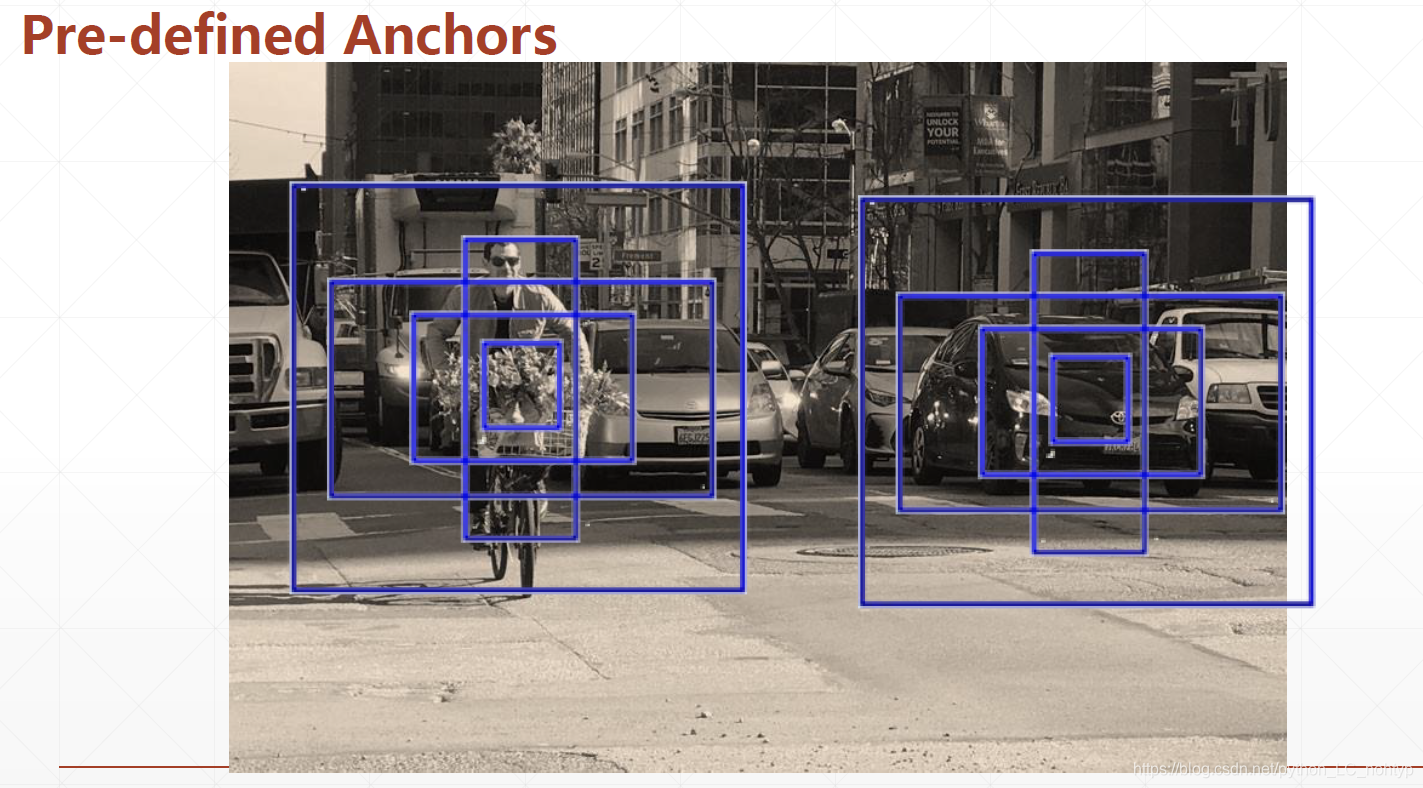
还有需要注意的事在YOLO2中x,y,w,h,confidence的意义都发生了一些变化,x ,y,w,h都不在是真实的坐标而且对于anchor的偏置,这样设计的好处就是可以给神经网络减压减负。confidence的含义则是真实物体框和anchor是重复率,我们可以通过IoU的方法选择出最优的anchor
Which is the best anchor?
Improvements - 3
之前提到 x,y,w,h的意义都发生了一些变化,x ,y,w,h都不在是真实的坐标而且对于anchor的偏置,那么这个偏置都是怎么变化的呢?
如下图所示,便是相应的过程

Inference
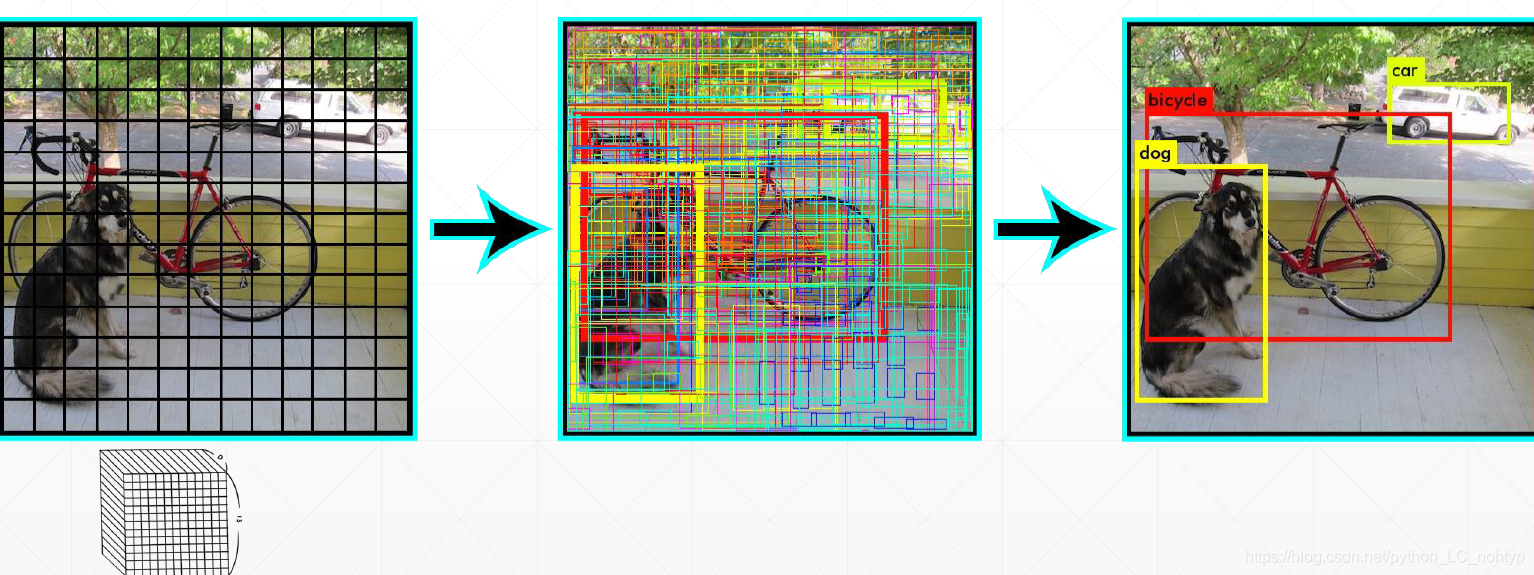
我们可以发现这里在设置阈值筛选掉一部分盒子之后盒子还是太多了,这个时候就要用到 Non - Max - Supperesion的方法
这个方法的思想也很简单:选择重叠的box中confidence最高的一个数
之后争取在这周内更新完YOLO篇的所有内容吧
参考书籍: TensorFlow 深度学习 — 龙龙老师















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









