







这篇博文是持续更新博文,记录tensor各种操作的爱恨情仇。
每天学一点,十天学十点,亿天学亿点!
目录
1.torch.stack
stack命令表示输出的东西扩展成一个维度相加
K = torch.tensor([[[0.0, 1.0], [2.0, 3.0]], [[1.0, 2.0], [3.0, 4.0]]])
K.shape
'''
torch.Size([2, 2, 2])
'''将张量K与K+1(K中每个元素加1)和K+2连接起来,构成一个具有3个输出通道的卷积核,扩维。如果指定的维度维1,则尺寸维(2,3,2,2),所以这个指定的维度是进行叠加后扩展的维度数,使用stack叠加的东西总会扩维。
K = torch.stack((K, K + 1, K + 2), 0)
K.shape, K
'''
(torch.Size([3, 2, 2, 2]),
tensor([[[[0., 1.],
[2., 3.]],
[[1., 2.],
[3., 4.]]],
[[[1., 2.],
[3., 4.]],
[[2., 3.],
[4., 5.]]],
[[[2., 3.],
[4., 5.]],
[[3., 4.],
[5., 6.]]]]))
'''2.torch.cat
不会扩维,会在原有的维度上指定拼接
X = torch.arange(16, dtype=torch.float32).reshape((1, 1, 4, 4))
X, X.shape
'''
(tensor([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.]]]]),
torch.Size([1, 1, 4, 4]))
'''X = torch.cat((X, X + 1), 1)
X, X.shape
'''
(tensor([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.]],
[[ 1., 2., 3., 4.],
[ 5., 6., 7., 8.],
[ 9., 10., 11., 12.],
[13., 14., 15., 16.]]]]),
torch.Size([1, 2, 4, 4]))
'''注意:cat操作,注意只有除了指定的拼接维度之外,其他维度必须一致才能运行!
3.repeat_interleave
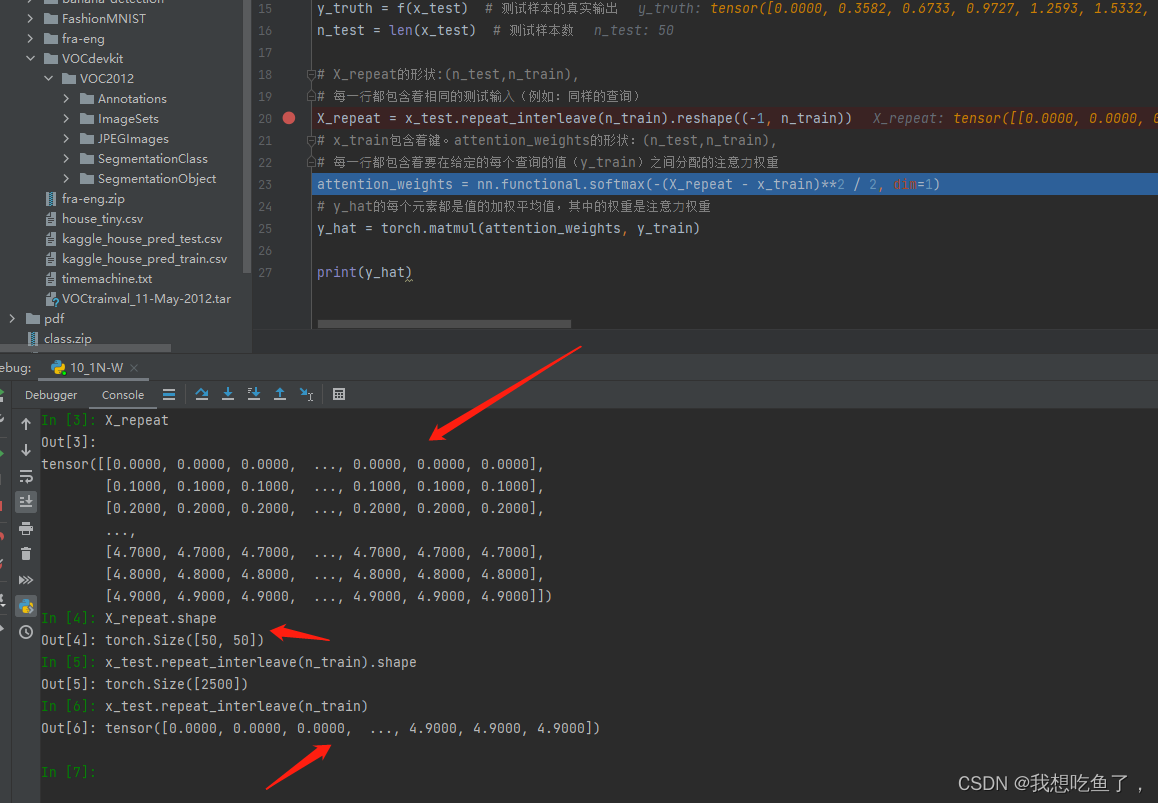
repeat_interleave就是将原来的x_test中的每一个元素赋值n_train次,得到一个一维tensor,再使用reshape操作使复制的相同元素都在同一行中。
X_repeat = x_test.repeat_interleave(n_train).reshape((-1, n_train))见下图:原x_text为:x_test = torch.arange(0, 5, 0.1)
4.softmax与sum中指定维度dim的问题
dim=1表示的是沿着列增的方向操作,本质是对每一行操作!!!
且sun(1)也表示沿着列增的方向操作,本质是对每一行的元素进行相加!!!
attention_weights = nn.functional.softmax(-(X_repeat - x_train)**2 / 2, dim=1)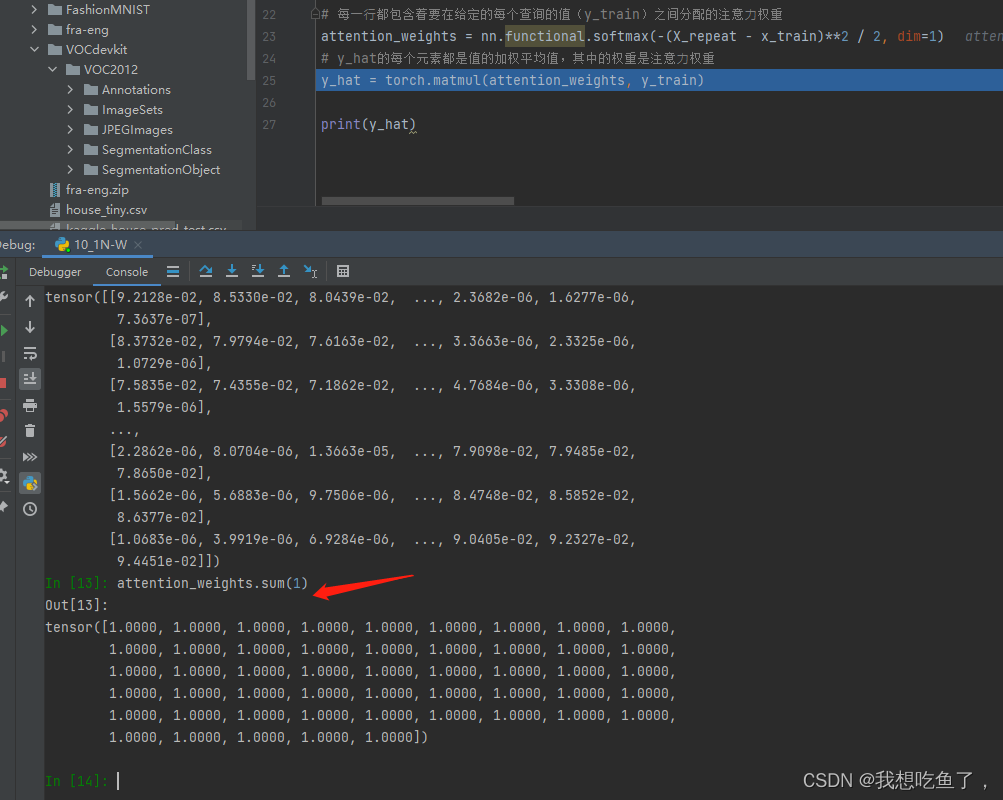
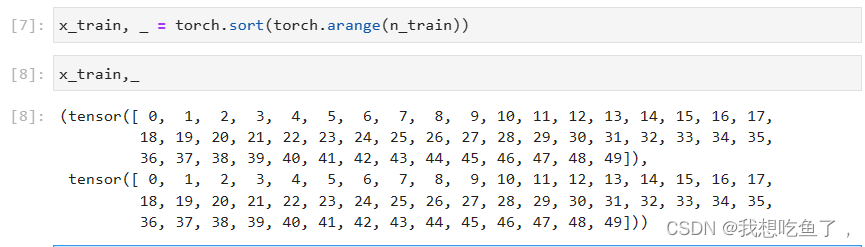
5.sort
sort返回两个值,第一个是拍好了从小到大的顺序后的values,另一个是对应原数据的indices
6.repeat
state的尺寸为(bs,h),X为(T,bs,emb)
context = state[-1].repeat(X.shape[0], 1, 1)改成(T,1),结果返回的是(T×bs,h);改成(T,1,1,1),返回的是(T,1,bs,h);改成(1,T,1),返回的(1,bs×T,h)。也就是说,原tensor为二维的(bs,h),repeat的最后两个数表示对这两个维度的操作,如果最后两个是(1,1),则原tensor保持不变,如果最后两个维度数字发生了变化,则表示原对应维度的数字×变化数字。如上述的(bs×T,h)或(bs, T×h)
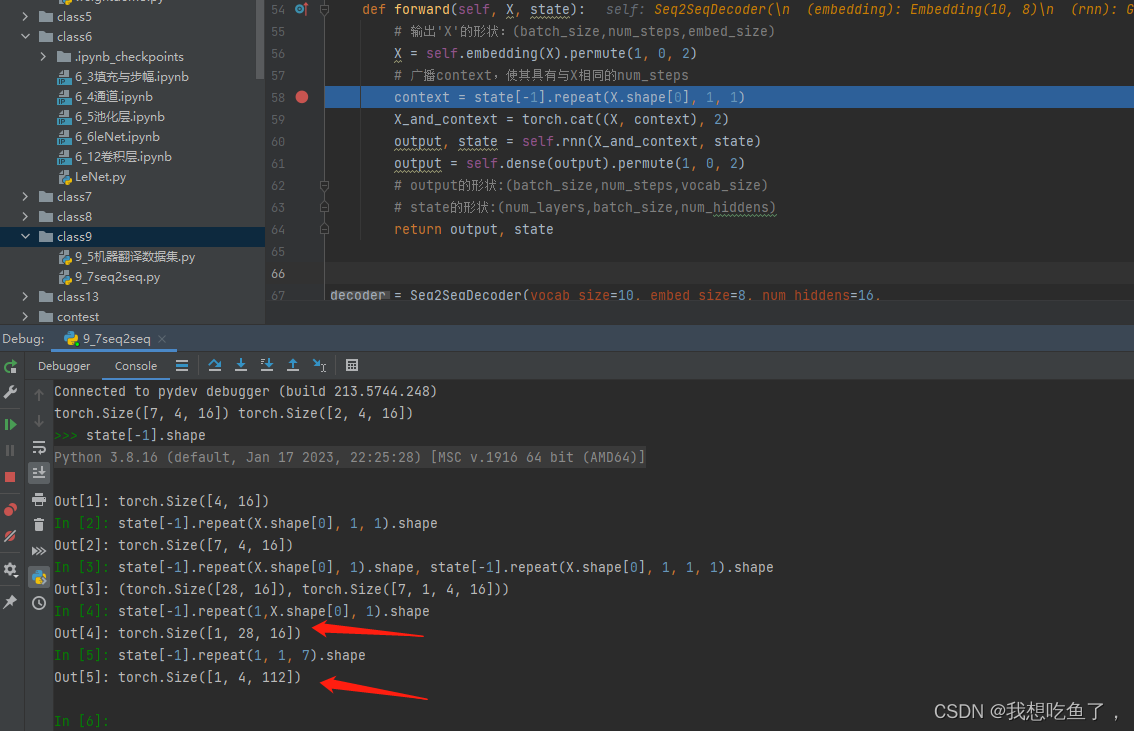
在这里,X表示tgt的input,形状为(T,bs,emb),广播后的state为(T,bs,h),拼接后为(T,bs,emb+h),对应decoder里面的GRU输入维度为dmb+h。
cat操作只有除了指定的拼接维度之外,其他维度必须一致才能运行!
7.transpose
Numpy用于交换数组的维度。可指定维度。
scores = torch.bmm(queries, keys.transpose(1,2))queries与keys两个tensor进行bmm矩阵乘法,对keys进行维度交换,从(bs,k-v,d)--(bs,d.k-v),这样bmm后得到的是(bs,q,k-v)。方便与后面的values的(bs,k-v,values)做bmm。
8.unsqueeze与squeeze
unsequeeze(i)再指定第i个维度上添加1维度;squeeze(i)减去原tensor中的第i维度,且第i维度必须是1才行,否则没用。
欣赏沐神加性注意力源码:forward部分
def forward(self, queries, keys, values, valid_lens):
queries, keys = self.W_q(queries), self.W_k(keys)
# 在维度扩展后,
# queries的形状:(batch_size,查询的个数,1,num_hidden)
# key的形状:(batch_size,1,“键-值”对的个数,num_hiddens)
# 使⽤⼴播⽅式进⾏求和
features = queries.unsqueeze(2) + keys.unsqueeze(1)
features = torch.tanh(features)
# self.w_v仅有⼀个输出,因此从形状中移除最后那个维度。
# scores的形状:(batch_size,查询的个数,“键-值”对的个数)
scores = self.w_v(features).squeeze(-1)
self.attention_weights = masked_softmax(scores, valid_lens)
# values的形状:(batch_size,“键-值”对的个数,值的维度)
return torch.bmm(self.dropout(self.attention_weights), values)对于query(bs,q,h)与key(bs,k-v,h),将两个扩充为(bs,q,1,h)与(bs,1,k-v,h),再通过广播相加,最后再激活,通过最后Linear变成(bs,q,k-v,1)。注意,最后维度为1,所以可以压缩掉最后的维度。















 2622
2622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









