






从Qwen基础模型看LLM的技术发展
Qwen一直是开源dense Model的领头羊(至少中文超越LLAMA),本文将梳理Qwen1-2.5四个版本的基础模型差异,管中窥豹看看LLM技术的发展趋势;后续会发表CODE,MATH,O1等细分方向的研究进展;
本文所有内容来源于Qwen团队的技术论文+huggingface开源的代码细节
Qwen虽然起步晚(ChatGPT22年底发布,LLAMA23年3月开源,Qwen很大程度起步于LLAMA,8月份发布第一个7B模型),但是现在已经站稳了脚跟
| 差异 | Qwen1 | Qwen1.5 | Qwen2 | Qwen2.5 |
|---|---|---|---|---|
| 发布时间 | 23年8-9月 | 24年2月 | 24年6月 | 24年9月 |
| 预训练技术 | 2K上下文,3T tokens | 4K->32K, 7T tokens | 18T tokens | |
| 后训练技术 | SFT+PPO,Rope+logn+window外推到32K | SFT, DPO+PPO | SFT, DPO,YARN+Chunk外推128K | |
| 模型结构 | LLAMA结构 | GQA | ||
| 额外细节 | PPO细节、ReAct+self insturct构造微调样本 | 离线DPO+在线DPO对齐,自动化SFT+DPO数据集构造 | ||
| 关键结论 | 超越LLAMA2一炮而红 | 生态发展,集成transformers | 12T<7T, 鼓励DPO,自动化数据生成 | 生成8K,结构化输出,系统提示增强 |
绪论
Qwen系列是一个基于Transformer的语言模型,通过预测下一个词的任务进行预训练;模型结构上采用Dense Decoder-only Transformer结构(Qwen-MOE效果一般不做讨论),采用了一种在编码不同语言信息方面具有高效率的Tokenizer(15wBBPE );
1. 从预训练预料的2到18TB;
2. 预训练上下文的2K-4K-32K的提升
3. 位置编码从Rope->NTK->YARN,并结合window attention或chuck attention机制提升长上下文能力
4. 对齐技术从PPO->DPO,数据生成依赖rejection sampling+Reward的数据飞轮
5. 模型结构基本不变化,都是causal attention+swiglu+pre rmsnorm, GQA也称为主流
6. 肉眼可见的技术报告减少,开源变成了开权重,没有研究人员可以为Qwen的下一代发展做出贡献
7. Coder\Math模型对contunue pretrain+post training, 反哺基座模型的能力
8. VL,Audio模型跟在base model后面喝汤,很快就发布了
Qwen1 系列
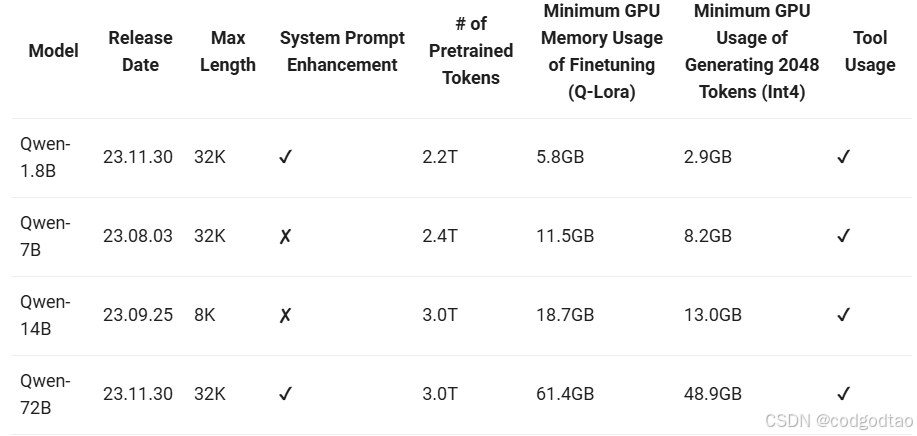
一句话总结:3T的预训练Tokens,基于SFT+PPO的后训练对齐方案;2K的训练上下文,32K的推理最大上下文长度(NTK ROPE+logn+window),以及15万大小的词表(对多语言非常友好,一般不需要拓展词表适配新语言);模型结构上采用RoPE相对位置编码、SwiGLU激活函数、RMSNorm;模型在MMLU和CMMLU上分别为77和83分,MATH得分35,落后于GPT3.5; 基于ReAct的prompt模版训练模型,得到tool-use的能力;
Tokenizer
采用UTF-8字节级别的BPE tokenization方式,并依赖tiktoken这一高效的软件包执行分词
Token包含两种类型:从BBPE算法在语料库中学到的普通字节Token;用于特殊信号控制的str类型token。理论上,输入文本中不包含特殊token,它们仅在tokenization后由开发者手动加入。Qwen-7B-Chat中有<|endoftext|>、<|im_start|>以及<|im_end|>和额外的留存token。Pad token的概念并不适用,不参与Loss计算。
有关词表合并扩充的code:
使用了超过15万token大小的词表。 该词表在GPT-4使用的BPE词表cl100k_base基础上,对中文、多语言进行了优化, 词表对数字按单个token位切分
预训练
Qwen-72B模型一方面利用了部分开源通用语料, 另一方面也积累了海量全网语料以及高质量文本内容,去重及过滤后的语料超过3T tokens。 囊括全网文本、百科、书籍、代码、数学及各个领域垂类。
数据生成流程: HTML文本识别->MiniHash LSH数据去重->数据评分于过滤->手动采样检查->高质量上采样->多任务指令数据预训练
2K的上下文长度,4M的batch size, 3e-4训练模型
无需训练的长度外推方案:
NTK-aware interpolation 增加上下文长度,压缩位置编码中 高维低频 部分的间隔,调制base即可简单实现,更高级的方法如YARN在qwen2中使用
LogN-scaling 将查询和值的点积重新缩放log_m^n,n为当前上下文长度,确保随着上下文长度的增长,注意力值的熵保持稳定
注意力分数的熵,在one-hot编码时为0,不确定性最低
在均匀分布时熵为logn, 熵达成最大值
当长度增加后,我们不希望新的token让注意力分布发生变化,即变得分散,所以log_m^n会让其分布更加紧凑,整体熵保持稳定
窗口注意力 较低层使用较短的窗口,为较高层分配更长的窗口加速训练
后训练
SFT: 损失掩码应用于系统和用户输入

Reward Model:
Preference model pretraining and fine-tuning on high-quality dataset
一般是在PLM基础上构造偏好数据集进行训练,需要考虑prompt多样和复杂程度,response采用PLM的不同采样策略生成,人类反馈标注偏好程度;
prompt-positive-negetive
Reward Model将PLM的end token polling输出reward即可
PPO:
policy model, value model, reference model, and reward model.
参考以下博文RLHF

关于Value Model: Reward Model只能给出当前状态下RLHF系统的即时性奖励,而Value Model会根据当前轨迹和reward给出长期期望总收益,通常从Reward Model初始化
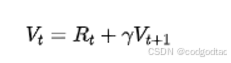
Actor/Value Model在RLHF阶段是需要训练的
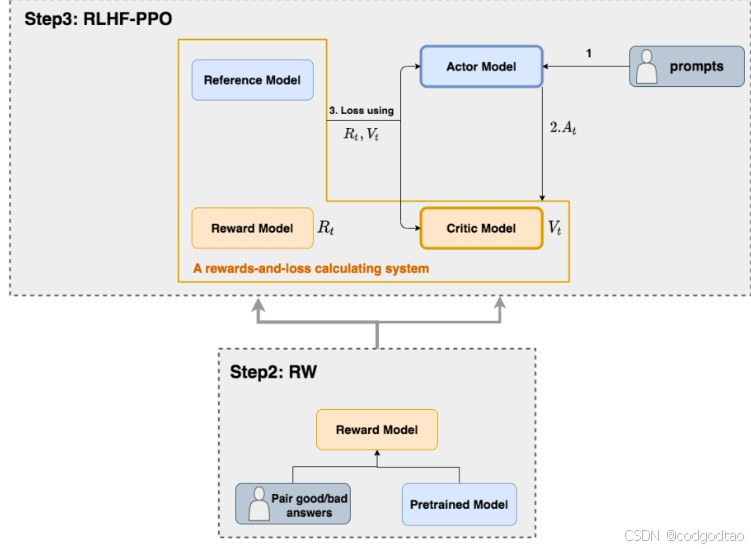
Actor loss:用于评估Actor是否产生了符合人类喜好的结果,将作用于Actor的BWD上。
Critic loss:用于评估Critic是否正确预测了人类的喜好,将作用于Critic的BWD上。


Agent能力:
基于self-instruct prompt Qwen,follow ReAct的格式生成SFT样本,在SFT阶段加入训练数据构造了2K条sample;Qwen Team 在tool use,code generation 上做了两个benchmark,效果显示远落后于GPT4
模型结构
QWenLMHeadModel
"hidden_size": 8192,
"no_bias": true, #QKV layer有bias
"num_attention_heads": 64,
"num_hidden_layers": 80,
"rope_theta": 1000000,
Pre-Norm & RMSNorm
Embedding and output projection分离权重以保证效果
模型效果
MMLU,C-Eval,GSM8K, MATH, HumanEval, MBPP, BBH, CMMLU等目前较流行的benchmark,对模型的中英知识能力、翻译、数学推理、代码等能力进行综合评测
OpenCompass 上有各个模型的指标实时对比
Qwen1.5 系列
一句话总结:支持了例如vLLM、SGLang、AutoGPTQ等框架,各种参数规模和量化版本提出
按照Qwen自己的话 “我们相信这次发布虽然在模型质量上是一小步,但在开发者体验上却是一大步”
Qwen2 系列
一句话总结差异:
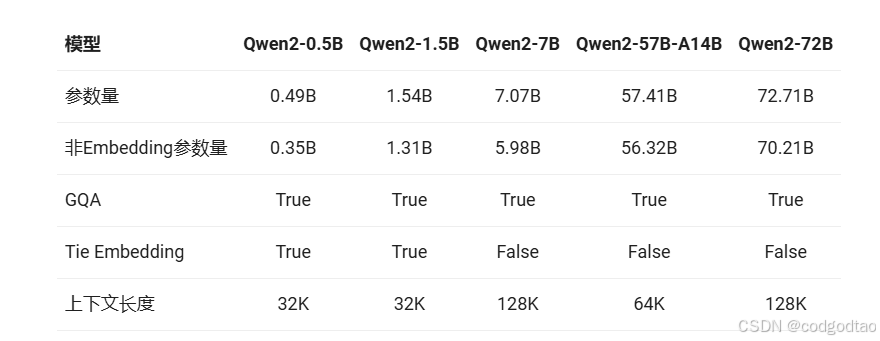
全系适配了Group Query Attention降低推理阶段的显存占用;小模型使用了tie embedding上输入的Embeding martix参数共享output head;
预训练模型均在32K tokens的数据,在使用YARN或Dual Chunk Attention后,能在128K的PPL和大海捞针中表现出色;针对多语言27种进行了预训练和SFT的增强,并优化语言转换问题;理解、知识、代码、数学及多语言等多项能力上均显著超越LLAMA3和Qwen110B模型。
预训练
7T的预训练数据集,增加到12TB效果没有改进,证明质量》》》数量
Qwen1的预训练窗口2K,现在预训练是4K,最后阶段增加到32K提升上线,ROPE base需要提高100倍来适配更新后的频率。训练后可以用Dual Chunck和YARN进一步提升,不确定Qwen团队是直接在这些机制上训练还是training-free,我个人偏向于后者。
后训练
500K条sample for SFT, 2epoch, very small lr, 32K max_length
离线DPO偏好优化,最大化postive negtive response的似然差
在线DPO:多次采样,Reward评分构造DPO数据,Online Merging Optimizer
探索了如何采用多种自动方法以获取高质量、可靠、有创造力的指令和偏好数据,其中包括针对数学的拒绝采样、针对代码和指令遵循的代码执行反馈(生成测试用例执行)、针对创意写作的回译、针对角色扮演的scalable oversight、等等。在训练方面,结合了有监督微调、反馈模型训练以及在线DPO等方法。我们还采用了在线模型合并的方法减少对齐税
接下来逐个介绍上述技术的细节:
-
协作数据注释:
第一步:构造大规模指令数据集,使用InsTag细粒度标注
第二步:根据标签的多样性、语义丰富度、复杂性和意图完整提取指令
第三步:基于Tree-Instruct丰富指令复杂性
第四步:产出response并排序,构造Reward和DPO的偏好数据 -
自动数据合成:
Rejection Sampling:拒绝采样,得出正确答案的路径保留,错误答案路径构造偏好response的negetive sample。拒绝采样技术的核心思想是通过设定一个合适的接受-拒绝准则,实现对目标概率分布的近似采样。这种方法适用于那些难以直接采样的复杂分布,在LLM的应用中,目标分布(理想response)很难获取,多次采样人工选择(接受阈值)实现近似采样。
针对创意写作的回译: 先有高质量文本response,再生成多样性的instruction
针对角色扮演的scalable oversight: 改为阅读理解任务,LLM阅读角色定义并生成instruction and reponse -
DPO对比学习
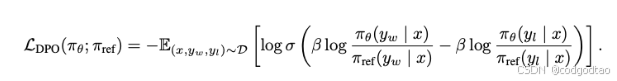
只有一个Actor和reference model,成对数据即可训练,最大化不同response的似然;后续SimPo缓解了长度依赖问题。 -
Online Merging Optimizer DPO使用的优化器
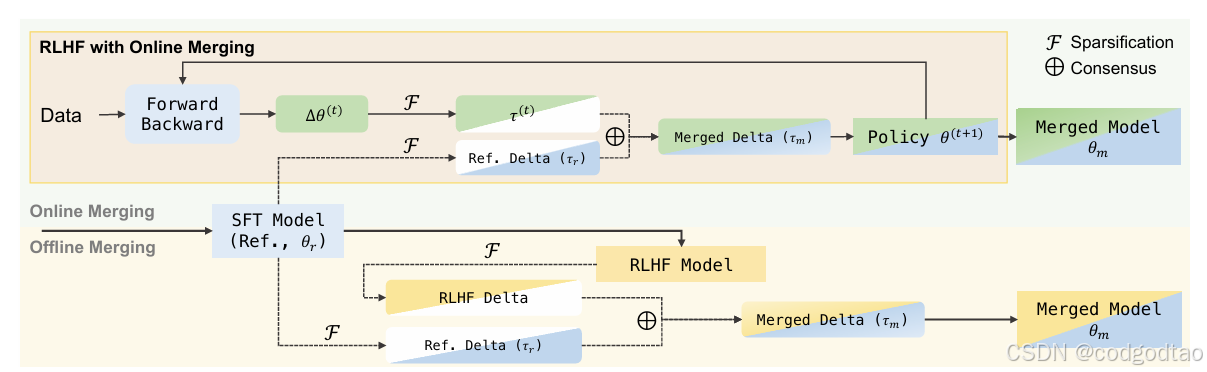
SFT-PRE的梯度更新方向是正确的优化方向,因此RL-SFT的梯度方向也应该是这样,约束参数更新收到SFT方向的控制,减少对齐税
模型结构
Tokenizer不更新
模型结构上全面使用Group Query Attention,多个query共享一个KV对;
增加Dual Chunk Attention和YARN进行长度外推,但是从transformers的代码仓库只能看到YARN
Dual chunk attention类似于分块滑动注意力机制,和LongLora的目标类似但是不需要训练模型,其[code base]应该要手动添加
模型效果
结果无需多言,SOTA,SOTA,还是SOTA

Qwen2.5 系列
一句话总结:太强了Qwen,旗舰模型登顶Compass;18Ttokens的预训练语料库,后训练阶段包含1M条SFT样本,多阶段的强化学习:离线DPO和在线GRPO(来源于deepseek-math,在qwen2.5-math也使用了此技术),后训练对于提升人类偏好,长文本生成,结构内容分析和Agent能力至关重要。
关键技术:
QKV bias+ROPE 通过bias: ab|m-n|增强了局部注意力的能力,注意力局部化是语言模型外推性的关键。
预训练阶段:
-
数据过滤:基于Qwen2-instruct进行comprehensive,multi-dimensional的评估打分,分类
-
数据集成了coder和math专有模型的专家数据
-
基于上一代模型和私有Reward model过滤得到的code\math\knowledge合成数据
-
数据混合上:娱乐内容downsample, underrepresented的内容过采样确保信息的rich
-
batch_size和learning_rate的scaling law
正常的scaling law流程(个人理解):
同一组数据下,训练多个不同尺寸的model(设计最优参数的选择),得到最优尺寸; 不同数据规模,重复上述过程
绘制best_model_size-----data size曲线,从而预测已有数据的最优模型尺寸,以及最优模型的performance,从数据和模型可以推导资源要求
qwen团队增加batch_size和learning_rate的scaling law探索,应该是最优模型的batch,lr作为数据点拟合曲线,得到任意数据大小下最优模型的batch,lr的规律,难点还是在数据约束下超参的消融实验,是个庞大的消融工程
long context:高base长文本pretrain+YARN+DCA实现4倍无损外推,和qwen2一致
后训练:
1M sample,包含长序列(o1的启发),数学问题解决、编码、指令遵循、结构化数据理解、逻辑推理、跨语言迁移和稳健的系统指令。
- 开发了长响应数据集(Quan et al., 2024)。我们使用反翻译技术从预训练语料库中生成长文本数据查询,施加输出长度约束,并使用Qwen2过滤掉低质量的配对数据
- Qwen2.5 Math的COT数据,利用了LLM合成-》Reward+参考答案过滤的生成方式
- Code基于代码执行验证和language-specific AGent的数据生成方案
- LLM同时生成指令遵循结果和验证代码
- 基于COT的结构化数据理解
- 70K条逻辑推理sample
- 专用评论模型、多AGent协作打分系统
- reward模型难以区分的推理、事实和指令遵循能力等存在标准答案的问题,采用DPO离线构造数据训练
150Ksample,SFT model rejection sampling。执行反馈和答案匹配
- 有益有害、真理、连贯、相关性、无偏性采用GRPO在线训练
reward model: 偏好数据集构建,响应是从Qwen模型的检查点生成的,这些模型在不同的训练阶段使用不同的方法(sft、DPO和rl)进行了微调。前面DPO的训练数据也集成到该数据集中。
用于训练奖励模型的查询集与RL训练阶段使用的查询集相同。我们为每个查询采样8个响应,reward打分评估。
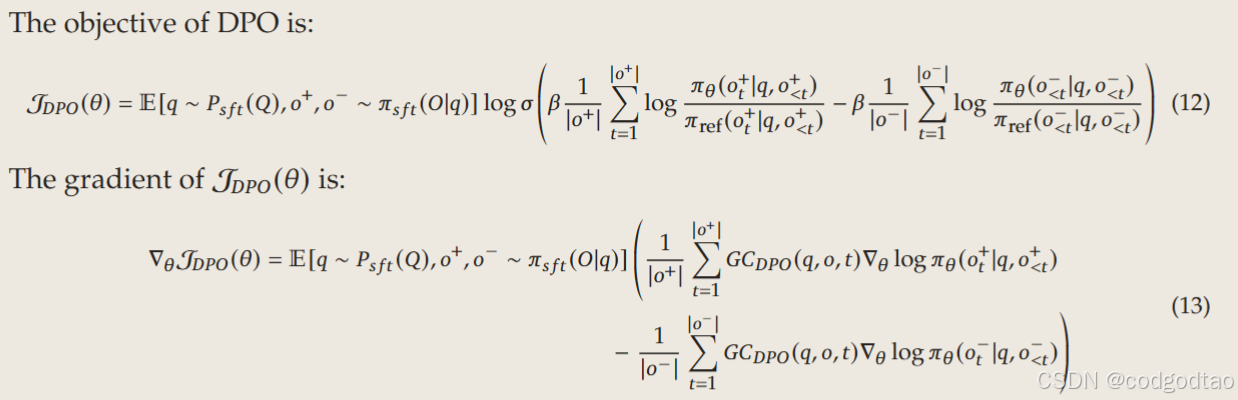

GRPO是PPO的一个简化版本
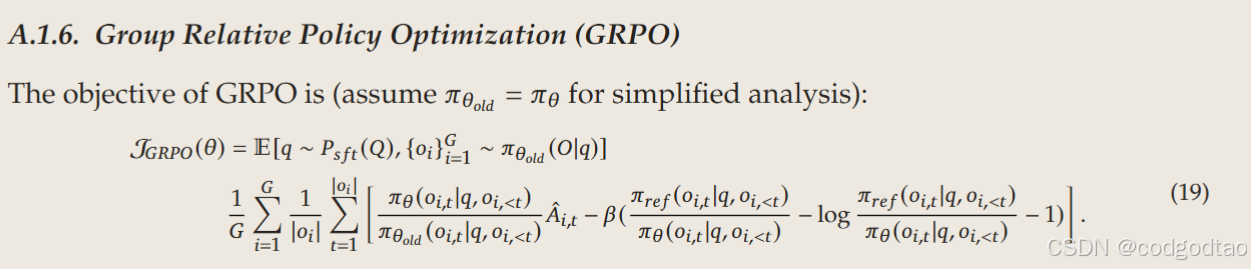

后续会聊聊专有任务的模型Qwen-coder和Qwen-Math系列,以及最新的O1路线的QWQ模型
MOE的代表deepseek(专家并行技术可以在推理阶段让超大参数规模的模型像小模型一样省钱,qwen-turbo和qwen-plus就是MOE架构,对标4o-turbo和4o模型; 但是虽然MOE模型的预训练与部署成本较低,但是对于小团队而言,700B的整体参数模型微调是非常昂贵的,特定领域的应用不如72B的dense Model划算,毕竟两张80G的卡就能量化部署了)
最后探讨多模态的Qwen-Audio和Qwen-VL系列,均发展至第二代
在多模态Qwen-VL探讨过程中,会发现学术圈竞争非常激烈LLAVA,InterVL, BLIP2等,但是效果距离商业模型GPT4O存在的差距更大更明显,这个赛道似乎更卷,技术结构也是五花八门的,但是真正做到one more thing级别的产品还是没有,多模态的scalling law没有被开源社区验证,甚至用户的需求也不如语音、文本端迫切,视觉多模态的火热越来越像一个吃力不讨好的伪需求(技术难度高成本大还不赚钱)
有任何问题欢迎留言讨论,分享技术!

















 1088
1088

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









