






LLM Prompt通用技巧
本文主要参考https://www.promptingguide.ai/zh并结合自身的一些思考
常用结构:
指令:想要模型执行的特定任务或指令。
上下文:包含外部信息或额外的上下文信息,引导语言模型更好地响应。
输入数据:用户输入的内容或问题。
输出指示:指定输出的类型或格式。
### 将以下文本翻译成西班牙语:###
examples
文本:“hello!”
- 从简单开始,逐步添加上下文和要求,或者分解复杂任务为多个子任务避免初期的困难
- 要非常具体地说明你希望模型执行的指令和任务
- 避免在Prompt上过于聪明,切中要点,避免模糊的要求
- 它应该做什么,而非不能做什么(它应该避免),聚焦于良好的回复上。
Advanced Prompt 技巧
-
COT and Few-shot COT

针对特定任务的Few-shot COT example比较难写,可以在LLM自动生成的COT链路上不断优化微调 -
定义任务分解流程Prompt Chain
对于复杂任务难以一次性解决的或者输入输出太长的,可以多轮调用LLM,进行step-by-step的微调控制
需要对任务步骤有先验知识,且调用次数比较多,通用能力差 -
自动控制COT的阶段(ToT)
自动分解问题阶段(深度),每阶段提出多条路径(广度),以阶段语句为节点单位
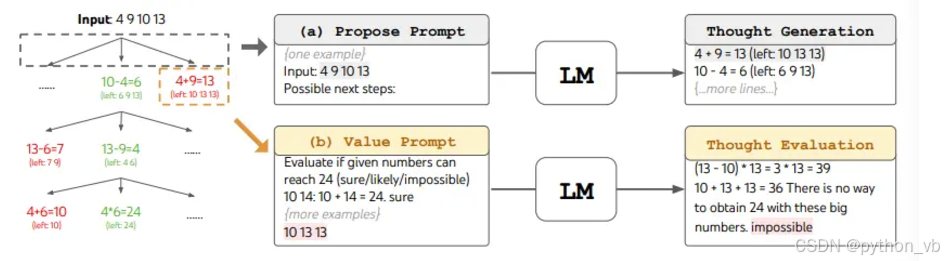
广度K=3,深度由问题确定;生成candidate和判断candidate分别调用了一次LLM,对于失效的candidate进行剪枝;对于candidate的生成和判断应该要专门写Prompt适配任务,通用的Prompt如下:
假设三位不同的专家来回答这个问题。
所有专家都写下他们思考这个问题的第一个步骤,然后与大家分享。
所有专家完成第一步骤后,所有专家都写下他们思考的第二步骤并分享。
所有专家完成第二步骤后,所有专家都写下他们思考的第三步骤并分享。
以此类推,直到所有专家写完他们思考的所有步骤。
只要大家发现有专家的步骤出错了,就让这位专家离开,不在进行下一步骤的推理和分享。
请问...
- Tool Use based (ReAct and Reflection)
Agent类型的雏形出现了(Tool use+memory+LLM+reflection),LLM具备自动思考解决问题的能力
LLMs 以交错的方式生成 推理轨迹 和 任务特定操作 。
生成推理轨迹使模型能够诱导、跟踪和更新操作计划,甚至处理异常情况。操作步骤允许与外部源(如知识库或环境)进行交互并且收集信息。
一个例子:
问题 科罗拉多造山带东部区域延伸到的区域的海拔范围是多少?
思考 1 我需要搜索科罗拉多造山带,找到科罗拉多造山带东段延伸的区域,然后找到该区域的海拔范围。
操作 1 搜索 [科罗拉多造山带]
观察 1 科罗拉多造山带是科罗拉多及其周边地区造山运动的一段。
思考 2 它没有提到东部地区。所以我需要查一下东部地区。
操作 2 查找 [东部地区]
观察 2 (结果 1 / 1) 东部区域延伸至高平原,称为中原造山带。
思考 3 科罗拉多造山运动的东部区域延伸到高平原。所以我需要搜索高平原,找到它的海拔范围。
操作 3 搜索 [高平原]
观察 3 高平原指的是两个截然不同的陆地区域之一。
思考 4 我需要搜索高平原(美国)
操作 4 搜索 [高平原(美国)]
观察 4 高平原是大平原的一个分区。从东到西,高平原的海拔从 1800 到 7000 英尺 (550 到 2130 米) 不等。[3]
思考 5 高平原海拔高度从 1800 到 7000 英尺,所以答案是 1800 到 7000 英尺。
操作 5 结束 [1800 到 7000 英尺]
...
上述few-shot prompt中,包含推理轨迹-任务操作-操作结果三个基本步骤,其中任务操作允许与外部环境交互来提升LLM的能力;
#基于langchain实现React, tools包含数学和搜索能力
#在这个Agent下,会进行思考-动作-观察的推理链路
llm = OpenAI(model_name="text-davinci-003" ,temperature=0)
tools = load_tools(["google-serper", "llm-math"], llm=llm)
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
4.1 Code-First Agent(TaskWeaver)
专注于LLM生成Code解决问题,适合精确度要求高或者图表绘制相关的问题
不是使用自由形式文本来获得解决方案,而是将解决步骤卸载到类似 Python 解释器的编程运行时中
个人时间:对于表格数据,text2sql,text2pd等数据分析工作,表头的字段名称和类型对于sql的质量有关键的影响;尽量只输入表头信息和一行demo数据防止超过LLM的context limits; 在code执行结束后进行Reflection判断是否需要重新生成
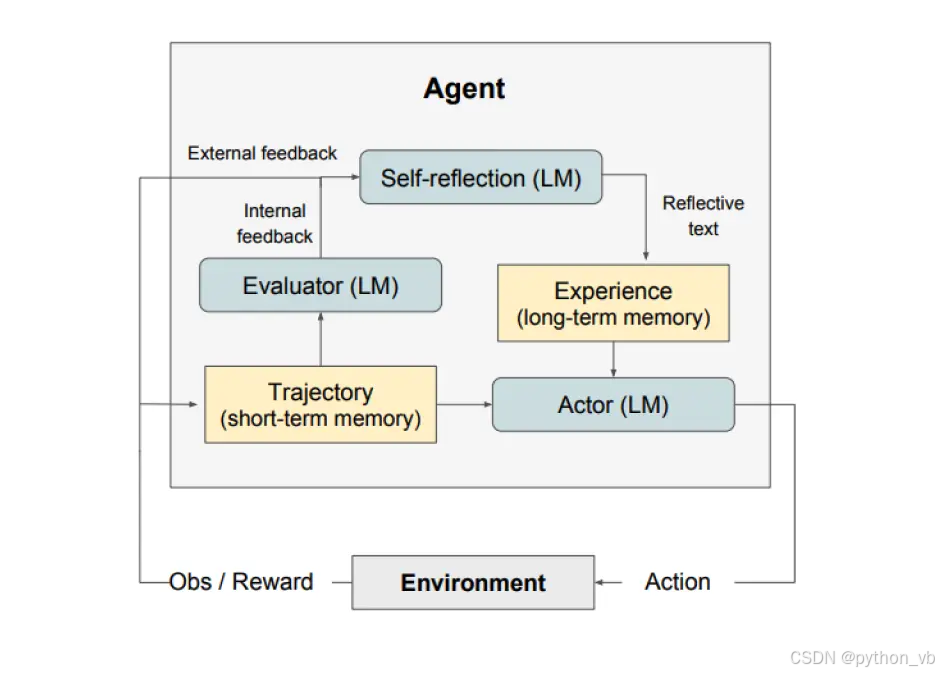
自我反思模块:对于ReAct+COT方案无法记录错误案例的方式进行自动化处理
使用额外LLM对Actor生成的output进行分析判断,出现报错、不符合常理等问题应该避免重复出现,符合问题要求的作为下一步的基础输入;
另有记录在外部文件(Long-term memory)的必要,为未来的试验提供宝贵的反馈。自我反思模型利用奖励信号、当前轨迹和其持久记忆生成具体且相关的反馈;
- RAG知识检索(适合知识密集型任务)

















 1767
1767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









