







Python微信订餐小程序课程视频
https://edu.csdn.net/course/detail/36074
Python实战量化交易理财系统
https://edu.csdn.net/course/detail/35475
上一篇文章推导了贝尔曼方程,这一篇文章来继续分享对应的马尔可夫决策的案例,然后引入策略评估并证明其收敛性。
主要的学习资源是四个:
- B站许志钦老师的视频(主要入门理论)https://www.bilibili.com/video/BV15a4y1j7vg?spm_id_from=333.999.0.0
- 书籍《强化学习入门:从原理到实践》(叶强等著,机械工业出版社)
- github中的配套资源 https://github.com/qqiang00/Reinforce
- 书籍《强化学习精要:核心算法与TensorFlow实现》(冯超著,中国工信出版集团)
1. 贝尔曼方程的矩阵表示
对于上篇文章推导的贝尔曼方程
Vπ(s)=∑aπ(a|s)[Ras+γ∑s′Vπ(s′)Pass′]V_π(s) = \sum_aπ(a|s)[R_{s}^a + γ\sum_{s’}V_π(s’)P_{ss’}^a]
为了便于运用矩阵,写成如下:
Vπ(s)=∑aπ(a|s)·∑s′Pass′·[Rt+1+γVπ(s′)]V_π(s) =\sum_{a}π(a|s)·\sum_{s’}P_{ss’}^a·[R_{t+1}+γV_π(s’)]
那么判断好维数就可以得出如下形式:
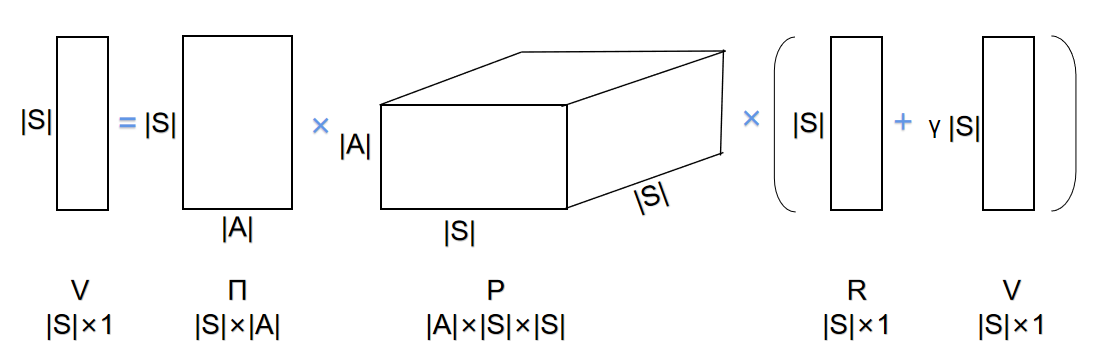
可以抽象出公式:
V=ΠP(R+γV)V=Π P (R+γV)
其中V用于表示状态值函数的向量,Π表示策略矩阵,P表示状态转移矩阵,R表示回报向量。通过求解可以得到:
V=(1−γΠP)−1ΠPRV = (1-γΠP)^{-1}ΠPR
但矩阵表示起来比较困难,尤其状态转移矩阵P是三维的,我还没有厘清这边的关系,而且大部分资料都不选择去详细解释这个部分,因为这种运算方法计算起来也比较困难,反而大家都采用迭代的方法。关于迭代的方法,我们下面的案例就会涉及到。该案例用python实现,由于其特殊的字典结构,形式上就可以不用数组来构建矩阵,也没有用上面推导的矩阵公式来求解状态。
2. 学生马尔科夫决策奖励过程实例
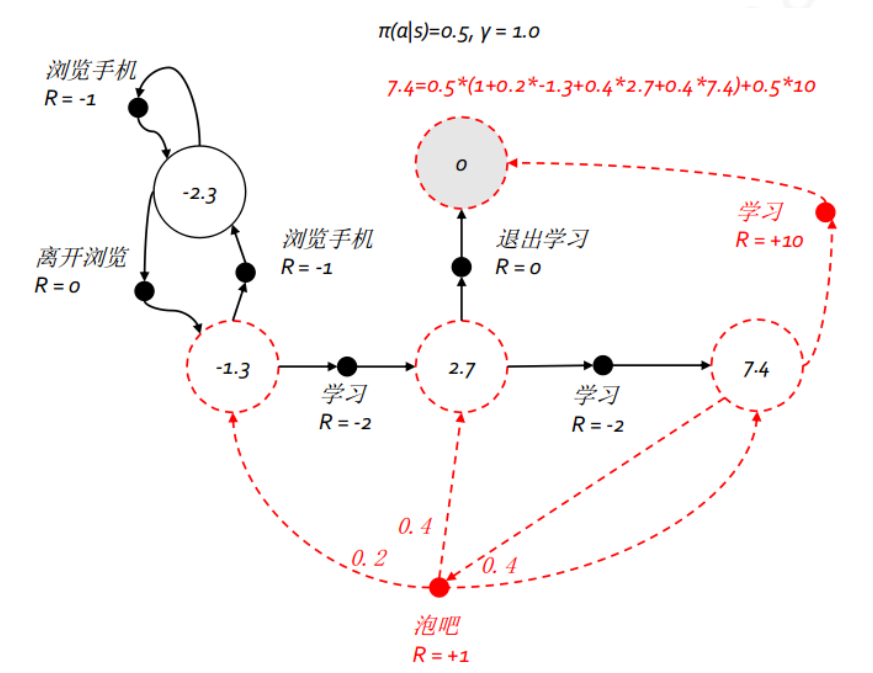
继续上一篇文章的例子,图中的状态数变成了 5 个,为了方便理解,我们把这五个状态分别命名为:浏览手机中、第一节课、第二节课、第三节课、休息中;行为总数也是 5 个,但具体到某一状态则只有 2 个可能的行为,这 5 个行为分别命名为:浏览手机、学习、离开浏览、泡吧、退出学习。与马尔科夫奖励过程不同,马尔科夫决策过程的状态转移概率与奖励函数均与行为相关。本例中多数状态下某行为将以 100% 的概率到达一个后续状态,但在状态 第三节课 选择 泡吧 行为除外。在对该马尔科夫决策过程进行建模时,我们将使用字典这个数据结构来存放这些概率和奖励。
2.1 构建辅助函数
叶强老师先写了utils.py作为辅助程序,如果只关注函数的用法,可以直接略过这部分的代码。
# 辅助函数
def str\_key(*args):
'''将参数用"\_"连接起来作为字典的键,需注意参数本身可能会是tuple或者list型,
比如类似((a,b,c),d)的形式。
'''
new_arg = []
for arg in args:
if type(arg) in [tuple, list]:
new_arg += [str(i) for i in arg]
else:
new_arg.append(str(arg))
return "\_".join(n 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 67
67











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









