







完整代码:https://download.csdn.net/download/pythonyanyan/87390631
由于现实世界中并不能获取全部的state以及全部的action,因此值迭代方法在很多问题上还是会有局限性。这时用到的就是Q Learning方法了,对于上述两个问题他会这样解决:
计算的时候不会遍历所有的格子,只管当前状态,当前格子的reward 值
不会计算所有action的reward,每次行动时,只选取一个action,只计算这一个action的reward
这样的规则也说明了需要大量的尝试,才能学习出比较好的结果。Q Learning的公式如下:

整理后得到

从左到右拆解开来分析

表示的是在s时执行a的reward值之和,包括了经验reward值和表示的是经验reward,即学习率*之前学习到的执行该action的reward。可以看到学习速率α越大,保留之前训练的效果就
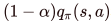
就是新的reward值了,下面逐步拆解。是计算下一个state'中最大的reward值,这个称之为 “记忆奖励”。因为在之前某次到达state'的时候,保存了四个方向(a') 的reward值,通过“回忆”,想起来自己之前在state'上能收获的最大好处,就可以直接影响在当前state时reward的计算。

是用来增加or减少state'的影响的,越大,智能体就会越重视以往经验,越小,就只重视眼前利益(R)。
R是执行了action后的reward,比如在终点处执行exit,获得+1/-1的 reward。
编写代码的时候,需要在update函数中体现上述思想。接下来分别实现函数
getQValue(state,action)函数
返回Q Value的值,直接return就可以,代码如下
defgetQValue(self,state,action):returnself.Q[(state,action)]computeValueFromQValues(state)函数
该函数是通过QValue返回最大的reward,因此需要遍历四个reward,最终得到最大值
defcomputeValueFromQValues(self,state):actions=self.getLegalActions(state)iflen(actions)==0:return0# 保存成列表values=[self.getQValue(state,action)foractioninactions]returnmax(values)computeActionFromQValues(state)函数 和上一个函数一样,只不过这里返回的是最大Action
defcomputeActionFromQValues(self,state):actions=self.getLegalActions(state)iflen(actions)==0:return0max_action=float('-inf')best_action=actions[0]# 记录最大actionforactioninactions:ifmax_action<self.getQValue(state,action):max_action=self.getQValue(state,action)best_action=actionreturnbest_actiongetAction(state)函数
此时要返回的action应该是最大的action
defgetAction(self,state):legalActions=self.getLegalActions(state)action=Noneiflen(legalActions)==0:returnactionreturnself.computeActionFromQValues(state)update(state, action, nextState, reward)`函数
这里就是要通过公式计算,更新Q Value值
defupdate(self,state,action,nextState,reward):sample=reward+self.discount*/self.getValue(nextState)mid=self.Q[(state,action)]# 公式self.Q[(state,action)]=(1-self.alpha)*/self.getQValue(state,action)+self.alpha*sample搭建完毕后,就可以计算每一个action的reward了:

按照相同路径走4次后的学习结果
Question7EpsilonGreedy 上述的算法看上去可以在每次动作都选择到最佳的动作,但在使用上述算法让智能体去学习Grid World的时候,会遇到下图的问题

















 730
730











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











