







 本文介绍了如何利用Spark-Streaming构建实时推荐系统,系统边界依赖于实时日志采集系统,数据通过Kafka流转,使用UpdateStateByKey进行业务处理。文章强调实时推荐仍需结合历史数据的离线推荐系统以确保准确性。
本文介绍了如何利用Spark-Streaming构建实时推荐系统,系统边界依赖于实时日志采集系统,数据通过Kafka流转,使用UpdateStateByKey进行业务处理。文章强调实时推荐仍需结合历史数据的离线推荐系统以确保准确性。
前言
随着互联网的飞速发展,如何能够让用户在广袤的互联网中获取到他所想要的,这时候人们有了搜索引擎。搜索引擎好比一个仓库,它需要事先储藏大量的资源,你需要什么都可以从中获取得到。这种被动索取的方式无形之中也注定了搜索引擎在某个范围内只能一家独大。科技改变着人们的生活,随着大数据时代的到来,传统被动等候来获取的方式由于其需要的前期投入较大,准确性往往也不能满足用户的真正需求,在此背景之下,推荐引擎遍广泛的被大家所接收,它的出现改变了系统被动的一面,它就好似跟踪导弹,只要你出现在互联网之中,就可以时刻为你推荐。
前期已经写了推荐系统离线计算的博文,主要是根据CF寻找相似,这种离线的推荐在计算周期内推荐结果不发生改变。个性化推荐则需要用户发生行为而实时为其推送推荐结果。
下面简单介绍下spark-streaming实时推荐系统搭建
系统边界
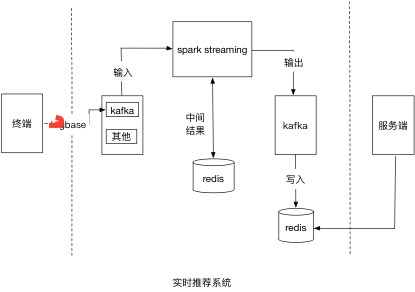
依托于一套可以实时采集到用户行为的日志采集系统,详情可以参见用户实时行为数据采集 将数据实时推送至kafka中,spark-streaming实时读取kafka中数据,进行特定的业务规则处理。这里会用到UpdateStateByKey方法,有兴趣的朋友可以去查阅相关资料了解此方法的原理及实现。
数据流
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









