






文章目录
总结
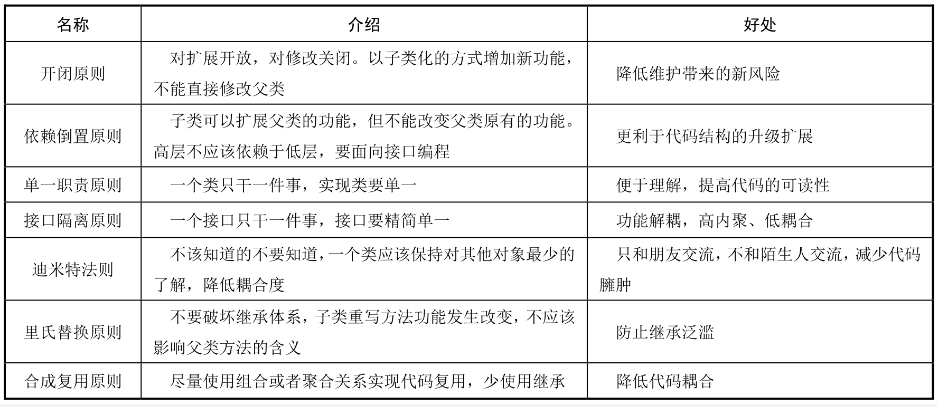
面向对象设计的7大原则
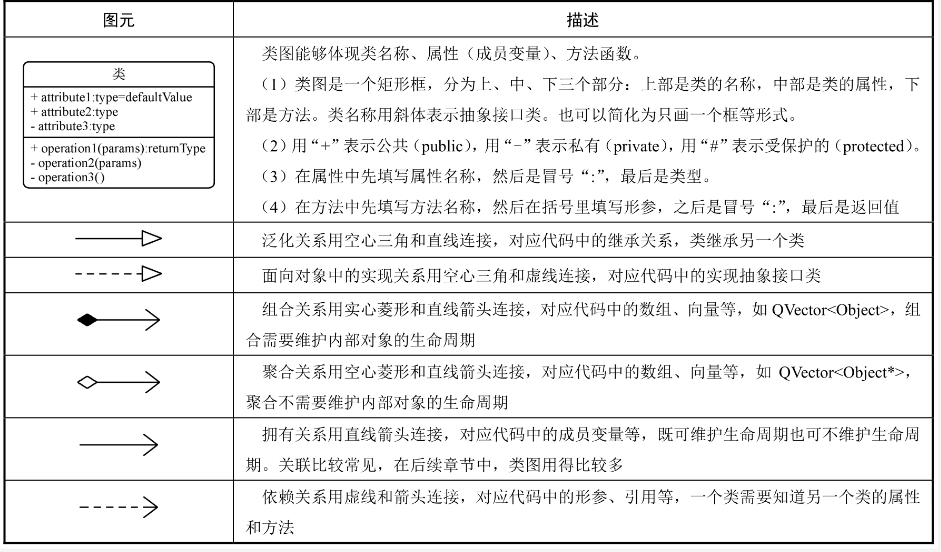
类图图元组成
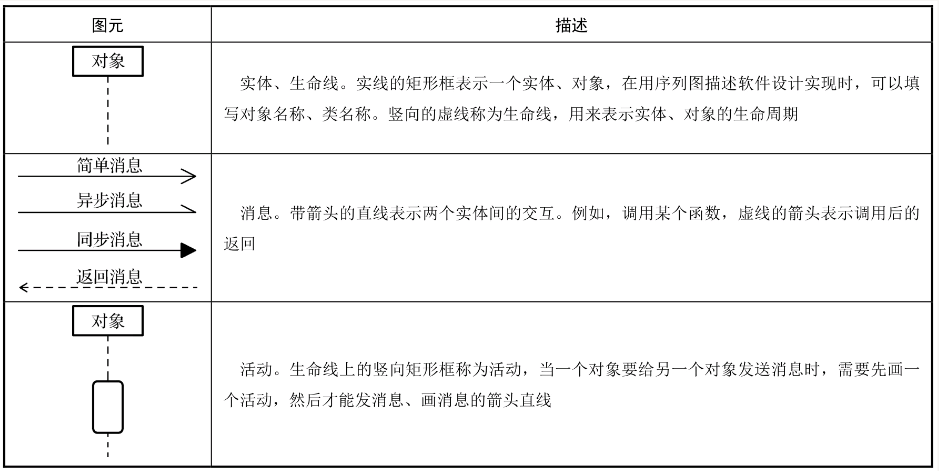
序列图图元组成
行为型设计模式
行为型设计模式是一类关注对象之间的通信和交互的设计模式。常见的行为型设计模式有以下几种:
-
观察者模式(Observer Pattern):定义了一种一对多的依赖关系,让多个观察者对象同时监听一个主题对象的状态变化。
-
策略模式(Strategy Pattern):定义了一族算法,并将其封装成独立的策略类,使得可以在运行时动态选择不同的算法。
-
模板方法模式(Template Method Pattern):定义了一种算法的骨架,将某些步骤的具体实现延迟到子类中。
-
迭代器模式(Iterator Pattern):提供一种一致的方式来访问集合对象中的元素,而无需暴露它们的内部表示。
-
命令模式(Command Pattern):将一个请求封装成一个对象,从而使得可以使用不同的请求来参数化其他对象,也可以支持请求的排队和记录。
-
责任链模式(Chain of Responsibility Pattern):将请求的发送者和接收者解耦,通过一条链传递请求,直到有对象处理它为止。
-
状态模式(State Pattern):允许对象在内部状态改变时改变其行为,将行为封装到不同的状态类中,并通过环境类管理状态的切换。
-
中介者模式(Mediator Pattern):通过一个中介对象来封装一系列的对象交互,使对象之间不需要显式地相互引用。
-
访问者模式(Visitor Pattern):在不改变对象结构的前提下,定义了对对象结构中的元素进行操作的新方法。
-
备忘录模式(Memento Pattern):在不破坏封装的情况下,捕获一个对象的内部状态,并在之后可以恢复到该状态。
-
解释器模式(Interpreter Pattern):定义了一个语言的文法,并定义了一个解释器来解释该语言中的表达式。
结构型模式
结构型模式关注对象和类之间的组合和组织方式,以实现更加灵活和可维护的结构。常见的结构型模式包括以下几种:
-
适配器模式(Adapter Pattern):将一个类的接口转换成客户端所期望的接口,以解决不兼容的接口问题。
-
桥接模式(Bridge Pattern):将抽象部分和实现部分分离,使它们可以独立地变化,以提供更好的灵活性。
-
组合模式(Composite Pattern):将对象组合成树形结构,以表示部分-整体的层次结构,使客户端可以一致地处理单个对象和组合对象。
-
装饰者模式(Decorator Pattern):动态地给一个对象添加额外的职责,即增加对象的功能。
-
外观模式(Facade Pattern):为复杂子系统提供一个统一的接口,以简化客户端对子系统的使用。
-
享元模式(Flyweight Pattern):通过共享对象来有效地支持大量细粒度的对象,以节省内存和提高性能。
-
代理模式(Proxy Pattern):为其他对象提供一种代理以控制对这个对象的访问。
创建型模式
创建型模式关注对象的创建过程,通过如何实例化和组合对象来提供更加灵活和可维护的方式来创建对象。常见的创建型模式包括以下几种:
-
单例模式(Singleton Pattern):确保一个类只有一个实例,并提供全局访问点。
-
工厂模式(Factory Pattern):定义一个创建对象的接口,但由子类决定实例化哪个类。
-
抽象工厂模式(Abstract Factory Pattern):提供一个接口,用于创建相关或依赖对象的家族,而不需要指定具体类。
-
建造者模式(Builder Pattern):将一个复杂对象的构建过程与其表示分离,以便同样的构建过程可以创建不同的表示。
-
原型模式(Prototype Pattern):通过复制已有的对象来创建新的对象,避免了使用构造函数创建对象的开销。
行为型
观察者
#include <iostream>
#include <vector>
// 抽象观察者类
class Observer {
public:
virtual void update(int data) = 0;
};
// 具体观察者类
class ConcreteObserver : public Observer {
private:
std::string name;
public:
ConcreteObserver(const std::string& observerName) : name(observerName) {}
void update(int data) override {
std::cout << "Observer " << name << " received data: " << data << std::endl;
}
};
// 主题类
class Subject {
private:
std::vector<Observer*> observers;
int data;
public:
void attach(Observer* observer) {
observers.push_back(observer);
}
void detach(Observer* observer) {
// 在实际应用中可能需要根据特定需求进行元素的查找和删除操作
observers.erase(std::remove(observers.begin(), observers.end(), observer), observers.end());
}
void notify() {
for (Observer* observer : observers) {
observer->update(data);
}
}
void setData(int newData) {
data = newData;
notify();
}
};
int main() {
Subject subject;
// 创建观察者对象
Observer* observer1 = new ConcreteObserver("Observer 1");
Observer* observer2 = new ConcreteObserver("Observer 2");
// 将观察者对象添加到主题对象中
subject.attach(observer1);
subject.attach(observer2);
// 更新主题数据,触发通知
subject.setData(10);
// 清理资源
delete observer1;
delete observer2;
return 0;
}
观察者模式是一种行为型设计模式,它定义了一种一对多的依赖关系,让多个观察者对象同时监听一个主题对象的状态变化。当主题对象的状态发生变化时,它会通知所有的观察者对象,使得它们能够自动更新自己的状态。
在观察者模式中,有两个关键角色:
-
主题(Subject):主题是被观察的对象,它包含了一组观察者对象,并提供了添加、删除和通知观察者的方法。
-
观察者(Observer):观察者是依赖于主题的对象,它定义了一个更新方法,当收到主题的通知时,观察者会调用更新方法来更新自己的状态。
观察者模式的优点包括:
-
解耦:观察者模式可以将观察者和主题对象解耦,使它们可以独立地变化和扩展。
-
可扩展性:可以在运行时动态地添加和删除观察者,实现灵活的观察者组合。
-
增强了对象间的交互:观察者模式使得主题和观察者之间可以通过触发和通知来实现交互,而不是直接调用彼此的方法。
观察者模式的缺点包括:
-
主题对象在通知观察者时,可能会有性能上的开销,特别是当观察者非常多时。
-
观察者和主题之间有可能出现循环依赖的问题。
总之,观察者模式是一种常用的设计模式,它能够建立起一种松耦合的关系,让主题和观察者之间能够进行有效的通信和交互。它适用于当一个对象的状态变化需要通知其他多个对象时使用,例如事件驱动的系统和GUI界面中的事件监听。
中介者
#include <iostream>
#include <string>
#include <vector>
// 抽象中介者类
class Mediator {
public:
virtual void sendMessage(const std::string& message, class Colleague* colleague) = 0;
};
// 具体中介者类
class ConcreteMediator : public Mediator {
public:
void sendMessage(const std::string& message, class Colleague* colleague) override {
for (auto c : colleagues) {
if (c != colleague) {
c->receiveMessage(message);
}
}
}
void addColleague(class Colleague* colleague) {
colleagues.push_back(colleague);
}
private:
std::vector<Colleague*> colleagues;
};
// 抽象同事类
class Colleague {
public:
virtual void receiveMessage(const std::string& message) = 0;
virtual void sendMessage(const std::string& message) = 0;
void setMediator(Mediator* mediator) {
this->mediator = mediator;
}
protected:
Mediator* mediator;
};
// 具体同事类
class ConcreteColleagueA : public Colleague {
public:
void receiveMessage(const std::string& message) override {
std::cout << "Colleague A received: " << message << std::endl;
}
void sendMessage(const std::string& message) override {
std::cout << "Colleague A sends: " << message << std::endl;
mediator->sendMessage(message, this);
}
};
class ConcreteColleagueB : public Colleague {
public:
void receiveMessage(const std::string& message) override {
std::cout << "Colleague B received: " << message << std::endl;
}
void sendMessage(const std::string& message) override {
std::cout << "Colleague B sends: " << message << std::endl;
mediator->sendMessage(message, this);
}
};
int main() {
ConcreteMediator mediator;
ConcreteColleagueA colleagueA;
colleagueA.setMediator(&mediator);
mediator.addColleague(&colleagueA);
ConcreteColleagueB colleagueB;
colleagueB.setMediator(&mediator);
mediator.addColleague(&colleagueB);
colleagueA.sendMessage("Hello, colleague B!");
colleagueB.sendMessage("Hi, colleague A!");
return 0;
}
中介者模式是一种行为型设计模式,用于将多个对象之间的通信和交互行为集中在一个中介者对象中,而不是让各个对象直接相互引用和交互。
中介者模式的核心思想是将各个对象之间的通信和协调逻辑抽象到一个中介者对象中,使得对象之间的关系更加松耦合。对象之间不再直接交互,而是通过中介者对象进行通信,从而减少了对象之间的依赖关系和耦合度。
中介者模式的角色如下:
- 中介者(Mediator):中介者是一个接口或抽象类,定义了各个对象之间的通信和协调方法。具体的中介者类负责实现这些方法,并维护对象之间的关系。
- 具体中介者(Concrete Mediator):具体中介者类实现了中介者接口,负责协调各个对象之间的通信和交互。它需要了解各个对象的接口和需求,并根据需求进行相应的处理。
- 同事(Colleague):同事是指参与通信和交互的各个对象。同事对象之间不直接交互,而是通过中介者进行通信。同事对象需要提供接口,让中介者对象能够进行通信和调用。
- 具体同事(Concrete Colleague):具体同事类实现了同事接口,负责实现自己的业务逻辑,并将自己的状态和行为告知中介者。
中介者模式的优点包括:减少对象之间的直接依赖和耦合,简化了对象之间的通信和交互,提高了代码的可维护性和可扩展性。
然而,中介者模式也有一些缺点,例如中介者对象需要处理大量的通信和协调逻辑,可能会变得复杂和庞大,而且新增或修改同事类时,可能需要修改中介者类。
中介者模式适用于对象之间的通信和交互比较复杂的场景,可以帮助简化对象之间的关系和逻辑。
职责链
#include <iostream>
#include <string>
// 抽象处理者类
class Handler {
public:
virtual void setNext(Handler* handler) = 0;
virtual void handleRequest(const std::string& request) = 0;
};
// 具体处理者类
class ConcreteHandlerA : public Handler {
public:
void setNext(Handler* handler) override {
nextHandler = handler;
}
void handleRequest(const std::string& request) override {
if (request == "A") {
std::cout << "ConcreteHandlerA handles the request." << std::endl;
} else if (nextHandler != nullptr) {
nextHandler->handleRequest(request);
} else {
std::cout << "No handler can handle the request." << std::endl;
}
}
private:
Handler* nextHandler = nullptr;
};
class ConcreteHandlerB : public Handler {
public:
void setNext(Handler* handler) override {
nextHandler = handler;
}
void handleRequest(const std::string& request) override {
if (request == "B") {
std::cout << "ConcreteHandlerB handles the request." << std::endl;
} else if (nextHandler != nullptr) {
nextHandler->handleRequest(request);
} else {
std::cout << "No handler can handle the request." << std::endl;
}
}
private:
Handler* nextHandler = nullptr;
};
class ConcreteHandlerC : public Handler {
public:
void setNext(Handler* handler) override {
nextHandler = handler;
}
void handleRequest(const std::string& request) override {
if (request == "C") {
std::cout << "ConcreteHandlerC handles the request." << std::endl;
} else if (nextHandler != nullptr) {
nextHandler->handleRequest(request);
} else {
std::cout << "No handler can handle the request." << std::endl;
}
}
private:
Handler* nextHandler = nullptr;
};
int main() {
ConcreteHandlerA handlerA;
ConcreteHandlerB handlerB;
ConcreteHandlerC handlerC;
handlerA.setNext(&handlerB);
handlerB.setNext(&handlerC);
handlerA.handleRequest("A");
handlerA.handleRequest("B");
handlerA.handleRequest("C");
handlerA.handleRequest("D");
return 0;
}
职责链模式是一种行为型设计模式,它将请求的发送者和接收者解耦,使多个对象都有机会处理请求。该模式建立了一个对象链,每个对象都可以选择执行请求、转发请求或者忽略请求。
在职责链模式中,有以下几个角色:
- 抽象处理者(Handler):定义处理请求的接口,通常包含一个指向下一个处理者的引用。
- 具体处理者(ConcreteHandler):实现抽象处理者的接口,具体处理请求的逻辑。如果自己无法处理该请求,则将其传递给下一个处理者。
- 客户端(Client):创建和组装职责链,并向职责链的头部发送请求。
职责链模式的工作原理如下:
- 客户端创建职责链,并将请求发送给职责链的头部。
- 职责链的每个处理者都有机会处理请求。如果处理者能够处理请求,就处理请求并终止职责链。如果处理者无法处理请求,就转发请求给下一个处理者。
- 请求会在职责链中依次传递,直到有一个处理者处理请求或者请求到达职责链的末尾。
职责链模式的优点包括:将请求的发送者和接收者解耦,增强了系统的灵活性和可扩展性;可以动态地修改和调整处理者的顺序和组合方式。
然而,职责链模式也有一些缺点,例如请求未必会被处理,可能会导致系统性能下降;在调试时可能会比较困难,因为请求的处理路径是动态生成的。
职责链模式适用于有多个对象可以处理同一个请求,且处理者的顺序和组合方式可能需要动态调整的场景。它可以帮助降低对象之间的耦合度,灵活组合对象处理请求。常见的应用场景包括请求的处理和拦截、日志记录和审批流程等。
命令模式
#include <iostream>
#include <string>
#include <vector>
// 命令接口
class Command {
public:
virtual void execute() = 0;
};
// 具体命令类
class ConcreteCommand : public Command {
private:
std::string message;
public:
ConcreteCommand(const std::string& msg) : message(msg) {}
void execute() override {
std::cout << "Command executed: " << message << std::endl;
}
};
// 命令调用者(Invoker)类
class Invoker {
private:
std::vector<Command*> commands;
public:
void addCommand(Command* command) {
commands.push_back(command);
}
void executeCommands() {
for (Command* command : commands) {
command->execute();
}
commands.clear();
}
};
int main() {
Invoker invoker;
// 创建命令对象
Command* cmd1 = new ConcreteCommand("Command 1");
Command* cmd2 = new ConcreteCommand("Command 2");
// 添加命令到调用者中
invoker.addCommand(cmd1);
invoker.addCommand(cmd2);
// 执行命令
invoker.executeCommands();
delete cmd1;
delete cmd2;
return 0;
}
命令模式是一种行为型设计模式,它将请求封装成一个对象,从而可以将请求的发送者和接收者解耦。该模式将请求的操作封装成一个独立的对象,这个对象包含了执行该请求所需的所有信息,包括请求的接收者、执行的方法和参数等。
在命令模式中,有以下几个角色:
-
命令(Command):定义了执行请求的接口,通常包含一个execute()方法。
-
具体命令(Concrete Command):实现了命令接口,具体实现了execute()方法,负责执行具体的请求操作。
-
请求者/调用者(Invoker):负责调用命令对象来执行请求。它并不直接知道请求的细节,只需知道命令对象的接口。
-
接收者(Receiver):负责执行命令所指定的操作。
命令模式的工作流程如下:
-
创建具体的命令对象,将命令的接收者传入其中。
-
创建请求者/调用者对象,并将命令对象设置给它。
-
请求者/调用者对象调用命令对象的execute()方法,执行操作。
-
命令对象执行请求操作,实际上是调用接收者的相应操作方法。
命令模式的优点包括:将请求的发送者和接收者解耦,可以方便地扩展和修改命令,增加新的命令不需要修改现有的代码;支持撤销操作。
然而,命令模式也有一些缺点,例如可能会导致类爆炸,因为需要为每个具体命令创建一个类;增加了系统的复杂性。
命令模式适用于需要将请求发送者和接收者解耦的场景,或者需要支持操作的撤销和重做操作的场景。常见的应用场景包括菜单命令、按钮点击事件、任务调度等。
解析器模式
在C++中,可以使用以下方式来实现解析器模式:
- 定义抽象表达式类(Expression),其中包含一个纯虚方法(interpret),用于解释和处理语法规则。
class Expression {
public:
virtual int interpret() = 0;
};
- 创建具体表达式类,这些类继承自抽象表达式类,并实现其解释方法。
class NumberExpression : public Expression {
private:
int value;
public:
NumberExpression(int num) : value(num) {}
int interpret() override {
return value;
}
};
class AdditionExpression : public Expression {
private:
Expression* exp1;
Expression* exp2;
public:
AdditionExpression(Expression* e1, Expression* e2) : exp1(e1), exp2(e2) {}
int interpret() override {
return exp1->interpret() + exp2->interpret();
}
};
- 创建一个解析器类(Parser),其中包含一个解析方法(parse),用于解析问题的语法表示。
class Parser {
public:
Expression* parse(const std::string& input) {
// 解析 input,根据语法规则构建表达式树,并返回根节点
}
};
- 在客户端代码中,创建解析器对象,并使用解析方法来解析问题的语法表示。
Parser parser;
Expression* expression = parser.parse("1 + 2 * 3"); // 通过解析器解析语法表示,并生成表达式树
int result = expression->interpret(); // 使用解释方法解释表达式树,得到最终结果
delete expression;
通过使用解析器模式,我们可以将复杂问题的语法表示形式定义为一组语法规则,并使用解析器来解释和处理这些规则。此外,解析器模式还可以支持动态地修改或扩展语法规则,从而改变问题的处理方式。
需要注意的是,在实现解析器模式时,需要考虑解析器的构建方法和解析方法的设计,以及如何构建表达式树和处理解释过程。具体的实现可能会因问题的复杂性而有所变化,因此可以根据具体问题选择适合的解析器设计和实现方法。
解析器模式(Interpreter Pattern)是一种行为型设计模式,它用于定义一个语言的文法,并且通过解析器解释执行语言中的表达式。
解析器模式的核心思想是将一个复杂的问题分解为一系列简单的规则和表达式,然后通过解析器来解释和执行这些规则和表达式。
在解析器模式中,有以下几个角色:
-
抽象表达式(Abstract Expression):定义了解析器的接口,声明了解析器的解释方法。
-
终结符表达式(Terminal Expression):实现了抽象表达式的解释方法,它是解析器的基本元素,不能再进行拆分。
-
非终结符表达式(Non-terminal Expression):实现了抽象表达式的解释方法,在解析器中可以进行拆分和组合,形成较为复杂的语法规则。
-
上下文(Context):包含需要解释的语句或表达式,提供解释器所需的信息。
-
客户端(Client):创建和配置解析器的对象,并且调用解析器进行解析和执行。
解析器模式的工作流程如下:
-
客户端创建和配置解析器对象,并将需要解释的语句或表达式传递给解析器。
-
解析器根据语法规则,将语句或表达式解析成抽象语法树(AST)。
-
客户端可以通过调用解释方法,对抽象语法树进行解释和执行。
解析器模式的优点包括:可以灵活地扩展和修改语言的文法,支持对复杂表达式的解释和执行。
然而,解析器模式也有一些缺点,例如随着语法规则的复杂性增加,解析器的设计和实现变得困难;解析器模式可能会导致性能问题,解释器需要对语法树进行递归解析,可能会影响执行效率。
解析器模式适用于需要解析和执行特定语法规则的场景,如编程语言解析、正则表达式解析、简单计算器等。它可以帮助实现复杂的语法解析和执行。
策略
在C++中实现策略模式通常有以下步骤:
- 定义一个抽象策略类,它声明了策略方法的接口。
class Strategy {
public:
virtual void execute() = 0;
};
- 实现具体的策略类,它们继承自抽象策略类,并实现了策略方法。
class ConcreteStrategyA : public Strategy {
public:
void execute() override {
// 具体策略A的实现
}
};
class ConcreteStrategyB : public Strategy {
public:
void execute() override {
// 具体策略B的实现
}
};
- 定义一个上下文类,它包含一个策略成员变量,并提供方法用于设置和执行策略。
class Context {
private:
Strategy* strategy;
public:
void setStrategy(Strategy* strategy) {
this->strategy = strategy;
}
void executeStrategy() {
strategy->execute();
}
};
使用策略模式的示例代码:
int main() {
Context context;
// 使用具体策略A
ConcreteStrategyA strategyA;
context.setStrategy(&strategyA);
context.executeStrategy();
// 使用具体策略B
ConcreteStrategyB strategyB;
context.setStrategy(&strategyB);
context.executeStrategy();
return 0;
}
策略模式的优点是可以在运行时动态地选择算法行为,提高了代码的灵活性和可扩展性。同时,它也符合开闭原则,因为可以通过添加新的策略类来扩展系统。然而,策略模式可能会增加类的数量,增加了代码的复杂性。
策略模式是一种行为型设计模式,它定义了一系列的算法,并将每个算法封装成独立的策略类。在运行时,可以根据需要选择不同的策略类来执行相应的算法。
在策略模式中,有三个关键角色:
-
环境(Context):环境类持有一个策略对象的引用,并在需要执行算法时调用策略对象的方法。
-
抽象策略(Strategy):抽象策略定义了算法的接口,它是策略类的共同父类或接口。
-
具体策略(Concrete Strategy):具体策略实现了抽象策略定义的算法接口,提供了具体的算法实现。
策略模式的优点包括:
-
算法的解耦:策略模式将每个算法封装在独立的策略类中,使得算法可以独立地变化和扩展,不影响其他算法。
-
程序的灵活性:通过在运行时动态地选择不同的策略类,可以根据需要执行不同的算法。
-
可扩展性:可以很容易地添加新的策略类,以实现新的算法。
策略模式的缺点包括:
-
增加了类的数量:策略模式需要定义多个策略类,可能会增加类的数量。
-
客户端需要了解不同的策略类:客户端需要了解每个策略类的区别和适用场景,才能正确选择和使用策略。
总之,策略模式是一种常用的设计模式,它提供了一种动态选择算法的方法。通过将不同的算法封装成独立的策略类,并在运行时选择不同的策略类,可以实现算法的灵活性和可扩展性。策略模式适用于当有多个算法可供选择时,并且需要根据不同的情况选择不同的算法。
状态模式
#include <iostream>
#include <string>
class State {
public:
virtual ~State() {}
virtual void handleState() = 0;
};
class ConcreteStateA : public State {
public:
void handleState() override {
std::cout << "Handling state A." << std::endl;
}
};
class ConcreteStateB : public State {
public:
void handleState() override {
std::cout << "Handling state B." << std::endl;
}
};
class Context {
private:
State* currentState;
public:
Context() : currentState(nullptr) {}
void setState(State* state) {
delete currentState;
currentState = state;
}
void execute() {
if (currentState) {
currentState->handleState();
}
}
};
int main() {
Context context;
context.setState(new ConcreteStateA());
context.execute();
context.setState(new ConcreteStateB());
context.execute();
return 0;
}
状态模式是一种行为型设计模式,它允许一个对象在内部状态变化时改变其行为。状态模式将对象的行为封装在不同的状态类中,使得对象在不同状态下可以有不同的行为。
在状态模式中,有三个主要的角色:
-
环境(Context):环境类持有一个状态对象的引用,并在需要执行行为时调用状态对象的方法。环境类可以根据内部状态的变化来改变当前状态对象。
-
抽象状态(State):抽象状态定义了可以执行的行为接口,它是状态类的共同父类或接口。
-
具体状态(Concrete State):具体状态实现了抽象状态定义的行为接口,提供了具体的行为实现。
状态模式的优点包括:
-
将状态逻辑封装:状态模式将不同的状态逻辑封装在不同的状态类中,使得状态逻辑更加清晰和易于维护。
-
状态的切换简单:通过将状态切换的逻辑放在环境类中,状态模式使得状态切换变得简单和可控。
-
扩展性强:可以很容易地添加新的状态类,以实现新的状态和行为。
状态模式的缺点包括:
-
增加了类的数量:状态模式需要定义多个状态类,可能会增加类的数量。
-
状态转换规则复杂:如果状态之间的转换规则较为复杂,可能会导致状态模式的实现变得复杂。
总之,状态模式是一种常用的设计模式,它提供了一种将对象的行为与其内部状态相结合的方法。通过将不同的状态逻辑封装在不同的状态类中,并通过环境类来管理状态的切换,状态模式提供了一种灵活和可扩展的方式来处理对象的状态变化。状态模式适用于当一个对象的行为在不同状态下不同且需要根据内部状态改变行为时使用。
访问者模式
#include <iostream>
#include <vector>
// 前向声明
class ElementB;
// 抽象访问者
class Visitor {
public:
virtual void visit(class ElementA* element) = 0;
virtual void visit(ElementB* element) = 0;
};
// 具体访问者
class ConcreteVisitor : public Visitor {
public:
void visit(class ElementA* element) override;
void visit(ElementB* element) override;
};
// 抽象元素
class Element {
public:
virtual void accept(Visitor* visitor) = 0;
};
// 具体元素A
class ElementA : public Element {
public:
void accept(Visitor* visitor) override {
visitor->visit(this);
}
std::string operationA() {
return "ElementA operation";
}
};
// 具体元素B
class ElementB : public Element {
public:
void accept(Visitor* visitor) override {
visitor->visit(this);
}
std::string operationB() {
return "ElementB operation";
}
};
// 具体访问者实现
void ConcreteVisitor::visit(ElementA* element) {
std::cout << "ConcreteVisitor: Visiting " << element->operationA() << std::endl;
}
void ConcreteVisitor::visit(ElementB* element) {
std::cout << "ConcreteVisitor: Visiting " << element->operationB() << std::endl;
}
// 对象结构
class ObjectStructure {
private:
std::vector<Element*> elements;
public:
void addElement(Element* element) {
elements.push_back(element);
}
void accept(Visitor* visitor) {
for (Element* element : elements) {
element->accept(visitor);
}
}
};
// 客户端代码
int main() {
ObjectStructure objectStructure;
objectStructure.addElement(new ElementA());
objectStructure.addElement(new ElementB());
ConcreteVisitor visitor;
objectStructure.accept(&visitor);
return 0;
}
访问者模式是一种行为型设计模式,它允许你在不改变已有对象结构的前提下,定义了新的操作(访问者),并将其应用于对象结构中的元素上。该模式将数据结构与操作分离,使得可以在不修改数据结构的情况下,添加新的操作。
访问者模式的核心思想是:在对象结构中定义一个accept方法,该方法接受一个访问者作为参数,并将自己作为参数传递给访问者的具体方法。访问者中定义了对不同类型元素的访问方法,通过多态的方式,在具体访问者中实现这些方法。
访问者模式包含以下角色:
- 抽象访问者(Visitor):声明了对各种元素的访问方法。它定义了多个访问方法,对每个具体元素类型都有一个访问方法。通过这些方法,访问者可以访问和操作不同类型的元素。
- 具体访问者(ConcreteVisitor):实现了抽象访问者中声明的访问方法。每个具体访问者都负责对某一种元素类型的访问和操作。
- 抽象元素(Element):定义了一个接受访问者的接口,通常包含一个accept方法。该方法接受一个访问者作为参数,并将自己作为参数传递给访问者的具体方法。
- 具体元素(ConcreteElement):实现了抽象元素中的accept方法。根据访问者的类型,调用访问者的具体方法来实现对自身的访问和操作。
- 对象结构(Object Structure):包含一组元素对象的集合,并提供了遍历元素的方法。它可以是一个容器,如列表、数组,或者是一个复杂的数据结构。
访问者模式的使用过程如下:
- 定义抽象访问者,声明对不同元素类型的访问方法。
- 定义具体访问者,实现抽象访问者中的访问方法,根据不同元素类型执行相应的操作。
- 定义抽象元素,声明一个接受访问者的方法。
- 定义具体元素,实现抽象元素中的接受访问者的方法,在方法中调用访问者的具体方法。
- 定义对象结构,并在对象结构中添加元素。
- 在客户端代码中,创建具体访问者和对象结构的实例,将访问者传递给对象结构,并通过对象结构的遍历方法,调用访问者的访问方法。
访问者模式的优点是可以在不改变元素的类层次结构的情况下,添加新的操作。它将相关的操作封装在访问者中,增加了系统的灵活性和可扩展性。同时,它也符合开闭原则,因为可以通过添加新的具体访问者来扩展系统的功能。
然而,访问者模式也存在一些缺点。首先,它增加了类的数量,使得系统变得更加复杂。其次,访问者模式破坏了元素的封装性,因为具体元素需要暴露accept方法给访问者使用。此外,如果元素的类型发生变化或新增新的类型,需要修改访问者的接口和具体访问者的实现,这会导致访问者模式的可维护性变差。
因此,在使用访问者模式时,需要权衡系统的灵活性和复杂性,并考虑是否值得引入该模式。
模板方法
#include <iostream>
// 抽象类
class AbstractClass {
public:
// 模板方法
void TemplateMethod() {
Step1();
Step2();
Step3();
}
protected:
// 抽象方法,由子类实现
virtual void Step1() = 0;
virtual void Step2() = 0;
// 具体方法
void Step3() {
std::cout << "Step3: Perform common step" << std::endl;
}
};
// 具体类A
class ConcreteClassA : public AbstractClass {
protected:
void Step1() override {
std::cout << "ConcreteClassA: Step1" << std::endl;
}
void Step2() override {
std::cout << "ConcreteClassA: Step2" << std::endl;
}
};
// 具体类B
class ConcreteClassB : public AbstractClass {
protected:
void Step1() override {
std::cout << "ConcreteClassB: Step1" << std::endl;
}
void Step2() override {
std::cout << "ConcreteClassB: Step2" << std::endl;
}
};
int main() {
AbstractClass* classA = new ConcreteClassA();
AbstractClass* classB = new ConcreteClassB();
// 调用模板方法
classA->TemplateMethod();
std::cout << std::endl;
classB->TemplateMethod();
delete classA;
delete classB;
return 0;
}
模板方法模式是一种行为设计模式,它定义了一个算法的骨架,将一些步骤延迟到子类中实现。模板方法模式使得子类可以在不改变算法结构的情况下重新定义算法中的某些步骤。
模板方法模式包含以下几个角色:
- 抽象类(AbstractClass):定义了一个模板方法,该方法包含了算法的骨架,以及一些抽象方法的声明,这些抽象方法由子类实现。抽象类可以定义具体方法,也可以将某些步骤交给子类实现。
- 具体类(ConcreteClass):继承自抽象类,并实现了抽象方法,完成算法中的具体步骤。
模板方法模式的核心思想是将公共的部分抽象出来,具体的实现交给子类完成。通过模板方法,可以确保算法的结构不变,将可变的部分延迟到子类中实现。这样可以提高代码的复用性和扩展性。
一个经典的例子是制作咖啡和茶。假设有一个制作饮料的流程,包含以下几个步骤:煮水、冲泡、倒入杯中、加入调料。具体的制作方法和调料可以由子类实现。抽象类中定义了模板方法,其中包含了上述步骤的调用顺序。
使用模板方法模式的好处是,将算法的实现从具体的子类中分离出来,提供了一种统一的算法结构,可以减少冗余代码。同时,模板方法可以保证算法的结构不变,使得子类的实现更加灵活。
迭代器模式
#include <iostream>
#include <vector>
// 迭代器接口
template<class T>
class Iterator {
public:
virtual bool HasNext() const = 0;
virtual T Next() = 0;
};
// 具体迭代器
template<class T>
class ConcreteIterator : public Iterator<T> {
public:
ConcreteIterator(const std::vector<T>& collection) : collection(collection), position(0) {}
bool HasNext() const override {
return position < collection.size();
}
T Next() override {
if (HasNext()) {
return collection[position++];
}
throw std::out_of_range("Reached the end of the collection");
}
private:
const std::vector<T>& collection;
size_t position;
};
// 容器接口
template<class T>
class Container {
public:
virtual Iterator<T>* CreateIterator() const = 0;
};
// 具体容器
template<class T>
class ConcreteContainer : public Container<T> {
public:
ConcreteContainer(const std::vector<T>& collection) : collection(collection) {}
Iterator<T>* CreateIterator() const override {
return new ConcreteIterator<T>(collection);
}
private:
const std::vector<T>& collection;
};
int main() {
std::vector<int> numbers = {1, 2, 3, 4, 5};
Container<int>* container = new ConcreteContainer<int>(numbers);
Iterator<int>* iterator = container->CreateIterator();
while (iterator->HasNext()) {
std::cout << iterator->Next() << " ";
}
std::cout << std::endl;
delete iterator;
delete container;
return 0;
}
迭代器模式是一种行为设计模式,它提供一种访问容器对象中各个元素的方法,而无需暴露该对象的内部表示。迭代器模式将遍历和容器对象分离,使得它们可以独立变化。
迭代器模式包含以下几个角色:
- 迭代器(Iterator):定义访问和遍历元素的接口,包括获取下一个元素、判断是否还有元素等方法。
- 具体迭代器(ConcreteIterator):实现迭代器接口,在具体容器对象上进行遍历。
- 容器(Container):定义获取迭代器的接口。
- 具体容器(ConcreteContainer):实现容器接口,返回一个具体迭代器的实例。
迭代器模式的核心思想是将遍历和容器对象分离,将遍历操作抽象成一个独立的迭代器对象。这样可以提供一种统一的遍历方式,无需了解容器对象的内部结构。
一个经典的例子是使用迭代器遍历一个集合对象。假设有一个集合类,其中包含若干元素,并且提供了获取迭代器的方法。迭代器类实现了迭代器接口,能够遍历集合对象中的元素。通过迭代器模式,我们可以在不暴露集合类内部实现的情况下,使用统一的迭代器接口遍历集合中的元素。
使用迭代器模式的好处是,将遍历操作与具体的容器对象解耦,提供了一种统一的遍历方式。同时,迭代器模式可以隐藏容器对象的内部结构,保护数据的一致性和完整性。另外,迭代器模式也可以提供多种不同的遍历方式,增加了灵活性和扩展性。
总结起来,迭代器模式通过提供一个独立的迭代器对象,将遍历和容器对象分离,使得遍历操作可以独立变化,提供了一种统一的遍历方式,同时保护了数据的封装性和安全性。
备忘录模式
#include <iostream>
#include <string>
#include <vector>
// 备忘录类
class Memento {
public:
Memento(const std::string& state) : state(state) {}
std::string GetState() const {
return state;
}
private:
std::string state;
};
// 发起人类
class Originator {
public:
void SetState(const std::string& state) {
this->state = state;
}
std::string GetState() const {
return state;
}
Memento* CreateMemento() const {
return new Memento(state);
}
void RestoreFromMemento(const Memento* memento) {
state = memento->GetState();
}
private:
std::string state;
};
// 管理者类
class Caretaker {
public:
void AddMemento(Memento* memento) {
mementos.push_back(memento);
}
Memento* GetMemento(size_t index) const {
if (index < mementos.size()) {
return mementos[index];
}
throw std::out_of_range("Invalid index");
}
private:
std::vector<Memento*> mementos;
};
int main() {
Originator originator;
Caretaker caretaker;
// 设置初始状态
originator.SetState("State 1");
std::cout << "Current state: " << originator.GetState() << std::endl;
// 创建备忘录并保存到管理者
Memento* memento = originator.CreateMemento();
caretaker.AddMemento(memento);
// 修改状态
originator.SetState("State 2");
std::cout << "Current state: " << originator.GetState() << std::endl;
// 恢复到备忘录中保存的状态
memento = caretaker.GetMemento(0);
originator.RestoreFromMemento(memento);
std::cout << "Restored state: " << originator.GetState() << std::endl;
return 0;
}
备忘录模式是一种行为设计模式,它允许在不破坏封装的情况下捕获和存储对象的内部状态,并在需要时将对象恢复到之前的状态。备忘录模式将对象的状态封装在一个备忘录对象中,以便可以随时回滚到之前的状态。
备忘录模式包含以下几个角色:
- 发起人(Originator):创建并管理备忘录对象,可以保存和恢复自身的状态。
- 备忘录(Memento):存储发起人的内部状态的对象。备忘录可以包含多个状态属性。
- 管理者(Caretaker):负责管理备忘录对象,可以存储和获取备忘录。
备忘录模式的核心思想是将对象的状态保存到备忘录中,并由发起人管理备忘录对象。发起人可以根据需要创建备忘录对象、存储状态、获取状态,并将当前状态恢复到之前的某个状态。
一个经典的例子是文本编辑器的撤销功能。假设有一个文本编辑器类,用户可以输入和编辑文本,并且可以通过撤销按钮撤销之前的操作。在这种情况下,发起人是文本编辑器对象,备忘录是文本的状态。
当用户进行编辑操作时,发起人将当前的文本状态保存在备忘录中。当用户点击撤销按钮时,发起人从管理者处获取最近的备忘录,并将当前文本状态恢复到备忘录中保存的状态。这样,用户可以回滚到之前的某个操作状态,实现了撤销功能。
备忘录模式的优点是它提供了一种轻松恢复对象状态的方式,而无需暴露对象的实现细节。它允许在不破坏封装的情况下实现撤销和恢复功能。此外,备忘录模式还可以在需要时保存对象的快照,用于日志记录或版本控制等应用。
总结起来,备忘录模式提供了一种捕获和存储对象状态的机制,以便可以随时恢复到之前的状态。它可以在不破坏封装的情况下实现撤销和恢复功能,并且可以应用于许多需要保存对象状态的情况。
结构型
代理模式
#include <iostream>
// 抽象主题类
class Subject {
public:
virtual void request() = 0;
};
// 真实主题类
class RealSubject : public Subject {
public:
void request() override {
std::cout << "真实主题类的请求" << std::endl;
}
};
// 代理类
class Proxy : public Subject {
public:
Proxy(Subject* subject) : subject_(subject) {}
void request() override {
preRequest();
if (subject_) {
subject_->request();
}
postRequest();
}
private:
void preRequest() {
std::cout << "代理类的前置请求" << std::endl;
}
void postRequest() {
std::cout << "代理类的后置请求" << std::endl;
}
Subject* subject_;
};
// 客户端代码
int main() {
Subject* realSubject = new RealSubject();
Proxy* proxy = new Proxy(realSubject);
proxy->request();
delete proxy;
delete realSubject;
return 0;
}
代理模式是一种结构型设计模式,它允许通过创建一个代理对象来控制对另一个对象的访问。
在代理模式中,代理对象充当了被代理对象的接口,它可以接收来自客户端的请求,并根据需要将请求传递给被代理对象。代理对象还可以在传递请求之前或之后执行其他操作,例如身份验证、访问控制、缓存等。
代理模式通常用于以下情况:
-
远程代理:当客户端需要访问远程对象时,代理模式可以隐藏底层的网络通信细节,使得客户端可以像访问本地对象一样访问远程对象。
-
虚拟代理:当对象的创建或加载需要很长时间时,代理模式可以使用虚拟代理延迟加载对象,从而提高系统的性能和响应时间。
-
安全代理:代理模式可以控制客户端对对象的访问权限,例如,根据用户的角色或权限限制对敏感对象的访问。
-
缓存代理:代理模式可以使用缓存来缓存对象的结果,从而避免重复计算或减少网络通信的次数。
代理模式由以下几个角色组成:
-
抽象主题(Subject):定义了代理对象和被代理对象的公共接口。在代理模式中,代理对象和被代理对象都实现了抽象主题。
-
真实主题(Real Subject):实现了抽象主题接口的被代理对象。真实主题包含了真正需要执行的业务逻辑。
-
代理(Proxy):实现了抽象主题接口,并包含了对真实主题的引用。代理对象可以在执行真实主题之前或之后执行其他操作,例如校验输入、缓存结果等。
代理模式的优点包括:
-
可以提供额外的功能,例如权限控制、缓存等,而无需修改真实主题。
-
可以隐藏真实主题的实现细节,使得客户端无需关注真实主题的创建和销毁。
-
可以实现远程代理,使得客户端可以方便地访问远程对象。
代理模式的缺点包括:
-
增加了系统的复杂性,因为引入了额外的抽象和代理对象。
-
可能会降低系统的性能,因为代理对象需要处理额外的操作。
总之,代理模式是一种常用的设计模式,它可以通过提供额外的功能和控制对对象的访问来提高系统的灵活性和性能。
装饰模式
#include <iostream>
#include <string>
// 抽象组件类
class Component {
public:
virtual void operation() = 0;
};
// 具体组件类
class ConcreteComponent : public Component {
public:
void operation() override {
std::cout << "具体组件类的操作" << std::endl;
}
};
// 抽象装饰类
class Decorator : public Component {
public:
Decorator(Component* component) : component_(component) {}
void operation() override {
if (component_) {
component_->operation();
}
}
protected:
Component* component_;
};
// 具体装饰类A
class ConcreteDecoratorA : public Decorator {
public:
ConcreteDecoratorA(Component* component) : Decorator(component) {}
void operation() override {
Decorator::operation();
addedBehavior();
}
void addedBehavior() {
std::cout << "具体装饰类A的附加行为" << std::endl;
}
};
// 具体装饰类B
class ConcreteDecoratorB : public Decorator {
public:
ConcreteDecoratorB(Component* component) : Decorator(component) {}
void operation() override {
Decorator::operation();
addedBehavior();
}
void addedBehavior() {
std::cout << "具体装饰类B的附加行为" << std::endl;
}
};
// 客户端代码
int main() {
Component* component = new ConcreteComponent();
Decorator* decoratorA = new ConcreteDecoratorA(component);
Decorator* decoratorB = new ConcreteDecoratorB(decoratorA);
decoratorB->operation();
delete decoratorB;
delete decoratorA;
delete component;
return 0;
}
装饰模式是一种结构型设计模式,它允许将行为动态地添加到对象中,而无需更改其原始类的代码。
在装饰模式中,有一个抽象组件(Component)类,它定义了需要被装饰的对象的接口。然后有一个具体组件(ConcreteComponent)类,它实现了抽象组件的接口,并定义了基本的行为。
装饰器(Decorator)类实现了抽象组件的接口,并持有一个对抽象组件的引用。装饰器类可以在保持原始类接口不变的情况下,动态地为抽象组件添加额外的行为。装饰器类还可以在调用原始类的方法之前或之后执行其他操作。
使用装饰模式可以实现以下效果:
-
动态地为对象添加功能,避免使用继承创建大量的子类。
-
在不修改原始类的情况下,扩展对象的行为。
-
可以在运行时添加和删除组件。
装饰模式的参与者包括:
-
抽象组件(Component):定义了需要被装饰的对象的接口。
-
具体组件(ConcreteComponent):实现了抽象组件的接口,并定义了基本的行为。
-
装饰器(Decorator):实现了抽象组件的接口,并持有一个对抽象组件的引用。装饰器可以在调用原始类的方法之前或之后执行其他操作。
-
具体装饰器(ConcreteDecorator):扩展了装饰器类的功能。
装饰模式的优点包括:
-
可以动态地添加或删除对象的功能。
-
可以通过装饰器类扩展对象的行为,而无需修改原始类的代码。
-
可以对对象进行多次装饰,实现复杂的功能组合。
装饰模式的缺点包括:
-
可能会导致类的数量增加,增加系统的复杂性。
-
可能会导致装饰器类和抽象组件类之间出现许多微小的接口差异。
总之,装饰模式是一种常用的设计模式,它提供了一种灵活的方式来动态地扩展对象的功能。它可以避免使用继承创建大量的子类,并保持原始类的接口稳定。
桥接模式
#include <iostream>
using namespace std;
// 实现部分接口
class Implementor {
public:
virtual void operationImpl() = 0;
};
// 具体实现类A
class ConcreteImplementorA : public Implementor {
public:
void operationImpl() override {
cout << "Concrete Implementor A operation" << endl;
}
};
// 具体实现类B
class ConcreteImplementorB : public Implementor {
public:
void operationImpl() override {
cout << "Concrete Implementor B operation" << endl;
}
};
// 抽象类接口
class Abstraction {
protected:
Implementor* implementor;
public:
Abstraction(Implementor* impl) : implementor(impl) {}
virtual void operation() = 0;
};
// 扩展抽象类A
class RefinedAbstractionA : public Abstraction {
public:
RefinedAbstractionA(Implementor* impl) : Abstraction(impl) {}
void operation() override {
cout << "Refined Abstraction A operation" << endl;
implementor->operationImpl();
}
};
// 扩展抽象类B
class RefinedAbstractionB : public Abstraction {
public:
RefinedAbstractionB(Implementor* impl) : Abstraction(impl) {}
void operation() override {
cout << "Refined Abstraction B operation" << endl;
implementor->operationImpl();
}
};
int main() {
Implementor* implementorA = new ConcreteImplementorA();
Implementor* implementorB = new ConcreteImplementorB();
Abstraction* abstractionA = new RefinedAbstractionA(implementorA);
abstractionA->operation();
Abstraction* abstractionB = new RefinedAbstractionB(implementorB);
abstractionB->operation();
delete implementorA;
delete implementorB;
delete abstractionA;
delete abstractionB;
return 0;
}
桥接模式是一种结构型设计模式,用于将抽象和实现分离,并独立地变化它们,以便可以在运行时动态地将不同的抽象与不同的实现进行组合。
桥接模式中的关键角色包括抽象接口(Abstraction)、实现接口(Implementor)、具体实现类(Concrete Implementor)和具体抽象类(Concrete Abstraction)。
-
抽象接口(Abstraction)定义了抽象类的接口,其中包含了一个指向实现接口的引用。它可以包含一些基于实现接口的操作方法。
-
实现接口(Implementor)定义了实现类的接口,其中包含了实现类的具体操作方法。
-
具体实现类(Concrete Implementor)实现了实现接口定义的具体操作方法。
-
具体抽象类(Concrete Abstraction)是基于抽象接口的扩展类,它实现了抽象类定义的操作方法,并通过依赖实现接口来具体实现这些方法。
桥接模式的主要优势在于它可以减少抽象和实现之间的紧耦合关系,使它们可以独立地进行变化。这样,可以在不影响其他部分的情况下,单独修改抽象或实现的某一方。它还提供了一种更灵活的扩展方式,允许在运行时动态改变抽象和实现的组合。
桥接模式通常适用于以下情况:
- 当需要在运行时动态地将不同的抽象与实现进行组合时。
- 当有多个独立变化的维度时,使用继承会导致类的组合爆炸时。
- 当希望避免在抽象和实现之间存在固定的绑定关系时。
总而言之,桥接模式通过将抽象和实现分离,使得它们可以独立地进行变化和演化,提供了更灵活、可扩展和可维护的设计方式。
外观模式
#include <iostream>
class Subsystem1 {
public:
void operation1() {
std::cout << "Subsystem1 operation1" << std::endl;
}
};
class Subsystem2 {
public:
void operation2() {
std::cout << "Subsystem2 operation2" << std::endl;
}
};
class Subsystem3 {
public:
void operation3() {
std::cout << "Subsystem3 operation3" << std::endl;
}
};
class Facade {
private:
Subsystem1 subsystem1;
Subsystem2 subsystem2;
Subsystem3 subsystem3;
public:
void doSomething() {
subsystem1.operation1();
subsystem2.operation2();
subsystem3.operation3();
}
};
int main() {
Facade facade;
facade.doSomething();
return 0;
}
外观模式是一种结构型设计模式,旨在为客户端提供一个简化接口,以便与复杂子系统进行交互。它通过定义一个高层接口,封装了子系统的复杂性,并将客户端与子系统的直接依赖关系解耦。
在软件设计中,复杂的系统往往由多个子系统或组件组成,每个子系统都有自己的接口和实现。客户端在使用这些子系统时可能需要了解每个子系统的接口和调用方式,这增加了系统的复杂性,并使客户端代码变得冗长而难以维护。而外观模式通过引入外观类,将这些复杂的子系统封装在一个简化的接口下,简化了使用复杂系统的过程。
外观模式的主要角色包括:
- 外观(Facade):外观类封装了子系统的复杂性,并提供了一个简化的接口供客户端使用。它知道如何调用子系统的各个组件,以实现客户端需要的功能。
- 子系统(Subsystem):子系统是一个或多个相关的类或组件,它们实现了系统的功能。外观类通过与子系统交互,完成客户端请求。
使用外观模式的好处包括:
- 简化客户端代码:通过提供一个简化的接口,外观模式隐藏了系统的复杂性,简化了客户端的代码。客户端只需要与外观类交互,而无需了解子系统的具体实现细节。
- 解耦子系统与客户端:外观模式将子系统与客户端的依赖关系解耦,使得子系统的变化不会影响到客户端。客户端只与外观类进行交互,可以灵活地调用不同的子系统功能,而不需要修改自己的代码。
- 提高代码的可维护性:外观模式将系统的复杂性封装在一个外观类中,使得系统更易于理解和维护。如果系统的实现发生变化,只需修改外观类的代码即可,而不需要修改客户端的代码。
需要注意的是,外观模式并不限制客户端直接访问子系统,客户端仍然可以通过外观类之外的接口直接访问子系统。外观模式的目的是提供一个简化的接口,而不是完全限制客户端对子系统的访问。
适配器模式
适配器模式(Adapter Pattern)是一种结构型设计模式,旨在将一个类的接口转换成另一个客户端所期望的接口。适配器模式使得原本由于接口不兼容而不能一起工作的类可以协同工作。
在软件开发中,有时候我们需要使用已有的类,但它们的接口与我们需要的接口不匹配。如果我们直接修改这些类的代码来满足新的接口,不仅会破坏原有的代码,还可能引入新的问题。适配器模式提供了一种转换接口的解决方案,可以在不修改原有类的情况下,适配新的接口。
适配器模式主要包括以下几个角色:
- 目标接口(Target):目标接口是客户端所期望的接口,它定义了客户端需要使用的方法。
- 源类(Adaptee):源类是需要被适配的类,它包含了不能与目标接口直接兼容的方法。
- 适配器(Adapter):适配器类是适配器模式的核心,它将源类的接口转换成客户端所期望的接口。适配器可以通过组合或继承的方式与源类进行协同工作,同时实现目标接口。
以下是一个使用C++实现适配器模式的示例代码:
#include <iostream>
// 目标接口
class Target {
public:
virtual ~Target() {}
virtual void request() = 0;
};
// 源类
class Adaptee {
public:
void specificRequest() {
std::cout << "Adaptee specificRequest" << std::endl;
}
};
// 适配器
class Adapter : public Target {
private:
Adaptee adaptee;
public:
void request() override {
adaptee.specificRequest();
}
};
int main() {
Target* target = new Adapter();
target->request();
return 0;
}
在上述示例中,我们有一个已经存在的类Adaptee,它具有一个specificRequest()方法,但其接口与我们需要的目标接口不匹配。然后我们引入适配器类Adapter,它继承了目标接口Target,并将Adaptee的特定方法封装在其request()方法中。
在main函数中,我们通过创建一个适配器对象,将其赋值给目标接口指针,调用request()方法。客户端只需要与目标接口交互,而无需直接与Adaptee类交互,适配器类将工作委托给Adaptee对象来完成。
输出结果:
Adaptee specificRequest
适配器模式的优点包括:
- 透明的接口转换:适配器模式使得两个不兼容的接口可以协同工作,客户端对此并不感知,通过适配器的存在,使得接口转换的过程对客户端来说是透明的。
- 保持原有类的封装性:适配器模式可以保持原有类的封装性,无需修改已有类的代码,只需要创建适配器类来实现接口转换即可。
- 提高代码的复用性:通过适配器模式,我们可以复用已有的类,使得其可以适应不同的接口需求,提高了代码的复用性。
需要注意的是,适配器模式主要用于接口之间的转换,而不是解决不同的功能需求。如果需要进行功能扩展,可能需要使用其他设计模式。
组合模式
#include <iostream>
#include <vector>
// 抽象类或接口,表示 Component 对象的共同特征
class Component {
public:
virtual void operation() const = 0;
};
// 叶子对象,没有子对象的对象
class Leaf : public Component {
public:
void operation() const override {
std::cout << "Leaf: Doing operation." << std::endl;
}
};
// 容器对象,包含其他 Component 对象
class Composite : public Component {
private:
std::vector<Component*> children;
public:
void operation() const override {
std::cout << "Composite: Doing operation." << std::endl;
// 调用子对象的 operation() 方法
for (Component* child : children) {
child->operation();
}
}
void add(Component* component) {
children.push_back(component);
}
void remove(Component* component) {
// 在实际应用中可能需要根据特定需求进行元素的查找和删除操作
children.erase(std::remove(children.begin(), children.end(), component), children.end());
}
};
int main() {
// 创建叶子对象
Component* leaf1 = new Leaf();
Component* leaf2 = new Leaf();
// 创建容器对象
Composite* composite = new Composite();
// 将叶子对象添加到容器对象中
composite->add(leaf1);
composite->add(leaf2);
// 调用容器对象的 operation() 方法,会递归调用子对象的 operation() 方法
composite->operation();
// 清理资源
delete leaf1;
delete leaf2;
delete composite;
return 0;
}
组合模式是一种结构型设计模式,它允许将对象组合成树形结构来表示“部分-整体”的层次结构。组合模式使得用户对单个对象和组合对象的使用具有一致性。
在组合模式中,有两种类型的对象:叶子对象和容器对象。叶子对象是没有子对象的对象,而容器对象则包含子对象。容器对象可以是叶子对象或其他容器对象的组合。
组合模式的核心思想是使用一个抽象类或接口来表示对象的共同特征,并提供一些通用的方法。对于容器对象,它既可以实现这个抽象类或接口,也可以包含其他这个抽象类或接口的对象。这样一来,客户端可以像对待单个对象一样对待容器对象,而不需要区分它们的类型。
组合模式的优点包括:简化客户端代码,客户端可以一致地对待单个对象和组合对象;增加新的叶子对象和容器对象都很容易,无需修改现有的代码;可以用来构建复杂的层次结构。
组合模式在以下情况下特别适用:需要表示“部分-整体”层次结构的场景;希望客户端可以一致地对待单个对象和组合对象的场景;希望简化客户端代码的场景;需要增加新的叶子对象和容器对象的场景。
总而言之,组合模式通过将对象组合成树形结构来表示“部分-整体”的层次结构,提供了一种简化客户端代码的方式。它使得客户端可以一致地对待单个对象和组合对象,同时也使得增加新的对象变得更加容易。
享元模式
#include <iostream>
#include <unordered_map>
// 抽象享元类
class Flyweight {
public:
virtual void operation(int extrinsicState) const = 0;
};
// 具体享元类
class ConcreteFlyweight : public Flyweight {
private:
int intrinsicState;
public:
ConcreteFlyweight(int state) : intrinsicState(state) {}
void operation(int extrinsicState) const override {
std::cout << "Concrete Flyweight: Intrinsic State = " << intrinsicState
<< ", Extrinsic State = " << extrinsicState << std::endl;
}
};
// 享元工厂类
class FlyweightFactory {
private:
std::unordered_map<int, Flyweight*> flyweights;
public:
Flyweight* getFlyweight(int state) {
if (flyweights.find(state) == flyweights.end()) {
flyweights[state] = new ConcreteFlyweight(state);
}
return flyweights[state];
}
~FlyweightFactory() {
// 清理资源
for (auto& pair : flyweights) {
delete pair.second;
}
flyweights.clear();
}
};
int main() {
FlyweightFactory factory;
// 获取享元对象
Flyweight* flyweight1 = factory.getFlyweight(1);
Flyweight* flyweight2 = factory.getFlyweight(2);
Flyweight* flyweight3 = factory.getFlyweight(1);
// 调用享元对象的操作方法
flyweight1->operation(10);
flyweight2->operation(20);
flyweight3->operation(30);
// 清理资源
delete flyweight1;
delete flyweight2;
delete flyweight3;
return 0;
}
享元模式是一种结构型设计模式,它旨在通过共享对象来减少内存使用和提高性能。享元模式将对象分为可共享和不可共享两种类型,可共享对象可以在多个上下文中共享,而不可共享对象则每次都需要创建新的实例。
在享元模式中,共享对象被存储在一个享元工厂(Flyweight Factory)中,该工厂负责创建和管理共享对象的实例。当客户端需要使用共享对象时,可以通过享元工厂获取共享对象的实例。如果共享对象不存在,则享元工厂会创建一个新的实例并存储在内部,以便于后续重复使用。
享元模式的核心思想是将对象的状态(内部数据)分为内部状态(Intrinsic State)和外部状态(Extrinsic State)。内部状态是可以被多个对象共享的部分,而外部状态是不可共享的部分。通过将外部状态作为参数传递给共享对象的方法,可以在不修改共享对象的情况下改变它的行为。
享元模式的优点包括:减少内存使用,因为共享对象可以在多个上下文中共享;提高性能,因为共享对象可以重复使用,避免了频繁创建和销毁对象的开销;简化客户端代码,因为客户端只需要关注外部状态,无需关心内部状态。
享元模式在以下情况下特别适用:需要创建大量相似对象的场景;需要减少内存使用和提高性能的场景;希望简化客户端代码的场景。
总而言之,享元模式通过共享对象来减少内存使用和提高性能。它将对象分为可共享和不可共享两种类型,并通过享元工厂来创建和管理共享对象的实例。通过将外部状态作为参数传递给共享对象的方法,可以在不修改共享对象的情况下改变它的行为。
创建型
单例模式
单例模式是一种常见的设计模式,它确保类只能创建一个实例,并提供一个全局访问点来获取该实例。这意味着在整个应用程序中,只有一个对象会被创建。
单例模式适用于以下情况:
- 当一个类只能有一个实例,而且需要提供一个全局访问点来访问该实例时。
- 当这个唯一实例需要被子类化,且客户端只使用这个子类的实例时。
实现单例模式需要注意以下几点:
- 将类的构造方法定义为私有,这样其他类就无法直接实例化该类。
- 创建一个私有的静态成员变量来保存实例,确保只有一个实例被创建。
- 提供一个公共的静态方法来获取实例,该方法负责创建实例并返回。
单例模式的完整C++代码示例如下:
#include <iostream>
using namespace std;
class Singleton {
private:
// 将构造函数设为私有,防止其他类直接实例化
Singleton() {}
static Singleton* instance;
public:
// 提供静态公共方法,返回单例实例
static Singleton* getInstance() {
if (instance == nullptr) {
instance = new Singleton();
}
return instance;
}
void showMessage() {
cout << "Hello, Singleton!" << endl;
}
};
// 初始化静态成员变量
Singleton* Singleton::instance = nullptr;
int main() {
Singleton* singleton = Singleton::getInstance();
singleton->showMessage();
return 0;
}
在这个例子中,通过将构造函数设为私有,其他类无法直接实例化Singleton类。getInstance()方法负责在首次调用时创建一个Singleton实例,并在之后的调用中返回该实例。在main函数中,首先通过getInstance()方法获取单例实例,然后调用showMessage()方法输出一条信息。
需要注意的是,这个示例是懒汉式单例模式,在多线程环境下可能存在竞态条件。为了实现线程安全的单例模式,可以在getInstance()方法中添加互斥锁或使用双重检查锁定等方式来确保只有一个实例被创建。
工厂模式
工厂模式是一种常见的设计模式,它提供了一种封装对象创建过程的方式。工厂模式将对象的创建和使用分离,客户端只需通过工厂类来创建所需的对象,而无需关心对象的具体创建过程。
工厂模式适用于以下情况:
- 当需要创建的对象较复杂,且创建过程可能涉及到多个步骤或条件判断时,可以使用工厂模式将创建过程封装起来,简化客户端代码。
- 当需要统一管理对象的创建,或者需要灵活调整创建过程时,可以使用工厂模式。
工厂模式包括以下几个角色:
- 抽象产品(Abstract Product):定义了产品的接口,所有具体产品都必须实现该接口。
- 具体产品(Concrete Product):实现了抽象产品接口的具体类。
- 抽象工厂(Abstract Factory):定义了创建产品的接口,包含一个或多个创建产品的抽象方法。
- 具体工厂(Concrete Factory):实现抽象工厂接口,负责具体产品的创建。
完整的工厂模式示例如下:
#include <iostream>
using namespace std;
// 抽象产品接口
class Product {
public:
virtual void show() = 0;
};
// 具体产品:产品A
class ConcreteProductA : public Product {
public:
void show() {
cout << "This is Product A" << endl;
}
};
// 具体产品:产品B
class ConcreteProductB : public Product {
public:
void show() {
cout << "This is Product B" << endl;
}
};
// 抽象工厂接口
class Factory {
public:
virtual Product* createProduct() = 0;
};
// 具体工厂:工厂A
class ConcreteFactoryA : public Factory {
public:
Product* createProduct() {
return new ConcreteProductA();
}
};
// 具体工厂:工厂B
class ConcreteFactoryB : public Factory {
public:
Product* createProduct() {
return new ConcreteProductB();
}
};
int main() {
Factory* factoryA = new ConcreteFactoryA();
Product* productA = factoryA->createProduct();
productA->show();
Factory* factoryB = new ConcreteFactoryB();
Product* productB = factoryB->createProduct();
productB->show();
delete factoryA;
delete productA;
delete factoryB;
delete productB;
return 0;
}
在这个例子中,抽象产品(Product)定义了产品的共同接口,具体产品(ConcreteProductA、ConcreteProductB)实现了该接口。抽象工厂(Factory)定义了创建产品的接口,具体工厂(ConcreteFactoryA、ConcreteFactoryB)实现了该接口,并分别负责创建具体产品。
在main函数中,首先通过ConcreteFactoryA创建了ConcreteProductA,并调用show()方法输出相应信息。然后通过ConcreteFactoryB创建了ConcreteProductB,并调用show()方法输出相应信息。
工厂模式的优点是封装了对象创建的过程,使得客户端与具体产品的创建过程解耦。这样可以便于扩展和维护,且符合开闭原则。
抽象工厂
抽象工厂模式是一种常见的设计模式,它提供了一种创建一系列相关或者相互依赖的对象的接口,而无需指定具体的实现类。抽象工厂模式可以看作是多个工厂方法模式的组合。
抽象工厂模式适用于以下情况:
- 当需要创建一系列相关或相互依赖的对象时,可以使用抽象工厂模式。这些对象通常有共同的接口或继承关系。
- 当希望客户端与具体的产品实现解耦时,可以使用抽象工厂模式。
抽象工厂模式包括以下几个角色:
- 抽象产品接口(Abstract Product):定义了产品的接口,所有具体产品都必须实现该接口。
- 具体产品(Concrete Product):实现了抽象产品接口的具体类。
- 抽象工厂接口(Abstract Factory):定义了创建一系列产品的接口,包含多个创建产品的抽象方法。
- 具体工厂(Concrete Factory):实现抽象工厂接口,负责创建一系列具体产品。
下面是一个完整的抽象工厂模式的C++代码示例:
#include <iostream>
using namespace std;
// 抽象产品A接口
class AbstractProductA {
public:
virtual void display() = 0;
};
// 具体产品A1
class ProductA1 : public AbstractProductA {
public:
void display() {
cout << "Product A1" << endl;
}
};
// 具体产品A2
class ProductA2 : public AbstractProductA {
public:
void display() {
cout << "Product A2" << endl;
}
};
// 抽象产品B接口
class AbstractProductB {
public:
virtual void display() = 0;
};
// 具体产品B1
class ProductB1 : public AbstractProductB {
public:
void display() {
cout << "Product B1" << endl;
}
};
// 具体产品B2
class ProductB2 : public AbstractProductB {
public:
void display() {
cout << "Product B2" << endl;
}
};
// 抽象工厂接口
class AbstractFactory {
public:
virtual AbstractProductA* createProductA() = 0;
virtual AbstractProductB* createProductB() = 0;
};
// 具体工厂1
class ConcreteFactory1 : public AbstractFactory {
public:
AbstractProductA* createProductA() {
return new ProductA1();
}
AbstractProductB* createProductB() {
return new ProductB1();
}
};
// 具体工厂2
class ConcreteFactory2 : public AbstractFactory {
public:
AbstractProductA* createProductA() {
return new ProductA2();
}
AbstractProductB* createProductB() {
return new ProductB2();
}
};
int main() {
AbstractFactory* factory1 = new ConcreteFactory1();
AbstractProductA* productA1 = factory1->createProductA();
AbstractProductB* productB1 = factory1->createProductB();
productA1->display();
productB1->display();
AbstractFactory* factory2 = new ConcreteFactory2();
AbstractProductA* productA2 = factory2->createProductA();
AbstractProductB* productB2 = factory2->createProductB();
productA2->display();
productB2->display();
delete factory1;
delete productA1;
delete productB1;
delete factory2;
delete productA2;
delete productB2;
return 0;
}
在这个例子中,抽象产品A和抽象产品B分别定义了产品A和产品B的接口,具体产品A1、A2和具体产品B1、B2实现了这些接口。抽象工厂定义了创建产品A和产品B的接口,具体工厂1和具体工厂2分别实现了抽象工厂接口,负责创建具体的产品。
在main函数中,首先通过ConcreteFactory1创建了ProductA1和ProductB1,并调用display()方法输出相应信息。然后通过ConcreteFactory2创建了ProductA2和ProductB2,并调用display()方法输出相应信息。
抽象工厂模式的优点是能够将一系列相关的产品组合成一个工厂,便于客户端使用,并且可以轻松切换工厂,以便创建不同的产品组合。同时,抽象工厂模式也符合开闭原则,增加新的产品属于扩展,无需修改现有代码。
建造者模式
#include <iostream>
#include <string>
// 产品类
class Product
public:
void setPartA(const std::string& partA) {
partA_ = partA;
}
void setPartB(const std::string& partB) {
partB_ = partB;
}
void setPartC(const std::string& partC) {
partC_ = partC;
}
void show() {
std::cout << "Part A: " << partA_ << std::endl;
std::cout << "Part B: " << partB_ << std::endl;
std::cout << "Part C: " << partC_ << std::endl;
}
private:
std::string partA_;
std::string partB_;
std::string partC_;
};
// 抽象建造者类
class Builder {
public:
virtual void buildPartA() = 0;
virtual void buildPartB() = 0;
virtual void buildPartC() = 0;
virtual Product* getResult() = 0;
};
// 具体建造者类
class ConcreteBuilder : public Builder {
public:
ConcreteBuilder() {
product_ = new Product();
}
void buildPartA() override {
product_->setPartA("Part A");
}
void buildPartB() override {
product_->setPartB("Part B");
}
void buildPartC() override {
product_->setPartC("Part C");
}
Product* getResult() override {
return product_;
}
private:
Product* product_;
};
// 指导者类
class Director {
public:
void construct(Builder* builder) {
builder->buildPartA();
builder->buildPartB();
builder->buildPartC();
}
};
// 客户端代码
int main() {
Director director;
ConcreteBuilder builder;
director.construct(&builder);
Product* product = builder.getResult();
product->show();
delete product;
return 0;
}
建造者模式是一种创建型设计模式,用于创建复杂对象。它将对象的构建过程与其表示分离,使得同样的构建过程可以创建不同的表示。
该模式将对象的构建过程分为多个步骤,并定义一个指导者(Director)来控制对象的构建过程。具体的构建过程由具体的建造者(Builder)来实现,不同的建造者可以实现不同的构建算法,从而创建不同的产品。最终的产品由产品(Product)类来表示。
建造者模式的主要优点有:
- 可以将构建过程与表示分离,使得同样的构建过程可以创建不同的表示;
- 可以精细控制对象的构建过程,对客户端隐藏具体的构建细节;
- 可以更好地复用构建算法。
建造者模式的结构包括以下几个角色:
- 产品(Product):表示正在构建的复杂对象。
- 抽象建造者(Builder):定义构建过程的抽象接口,包括构建各个部件的方法。
- 具体建造者(ConcreteBuilder):实现抽象建造者接口,实现不同的构建算法。
- 指导者(Director):负责控制构建过程的顺序,调用建造者的方法来构建对象。
- 客户端(Client):使用建造者模式的客户端。
使用建造者模式可以在不同的构建过程中创建不同的对象表示,并且可以将对象的构建过程封装起来,对客户端隐藏具体的构建细节。
原型模式
原型模式(Prototype Pattern)是一种创建型设计模式,它允许通过复制现有对象来创建新对象,而无需通过调用构造函数。这种模式在对象的创建过程中可以提高性能,并且可以避免耗时的构造操作,尤其是在对象的构造过程中涉及到大量资源的申请或初始化。
在C++中,可以通过深拷贝和浅拷贝来实现原型模式。浅拷贝仅复制对象的成员变量的值,而深拷贝会递归地复制对象的所有成员变量,包括指针指向的内容。
下面是一个完整的C++实现示例:
#include <iostream>
#include <string>
// 原型类
class Prototype {
public:
virtual Prototype* clone() const = 0;
virtual void display() const = 0;
};
// 具体原型类
class ConcretePrototype : public Prototype {
private:
std::string name;
public:
ConcretePrototype(const std::string& name): name(name) {}
// 实现深拷贝
Prototype* clone() const override {
return new ConcretePrototype(*this);
}
void display() const override {
std::cout << "Name: " << name << std::endl;
}
};
int main() {
// 创建原型对象
Prototype* prototype = new ConcretePrototype("Prototype");
// 创建新对象并通过原型对象进行复制
Prototype* clone = prototype->clone();
// 分别显示原型对象和克隆对象的内容
prototype->display();
clone->display();
delete prototype;
delete clone;
return 0;
}
以上示例中,首先定义了一个抽象的原型类Prototype,其中包含了两个纯虚函数clone和display。然后创建了一个具体的原型类ConcretePrototype,其中实现了深拷贝的clone函数和显示内容的display函数。
在main函数中,首先创建了一个原型对象prototype,然后通过调用clone函数来创建了一个克隆对象clone。最后分别调用display函数显示原型对象和克隆对象的内容。在程序结束时,需要手动释放创建的对象。
该示例展示了原型模式的基本思想,通过复制现有对象来创建新对象,从而提高性能和代码复用。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









