








目的:待判断的对象x = (x1, x2,…, xm)T是属于已知类A1, A2,…, Ar中的哪一类?
判别规则:用于衡量待判对象与各已知类别接近程度的方法准则。往往通过的某个函数来表达, 我们把它称为判别函数, 记作W(i; x)。
一般要求这种准则在某种意义下是最优的,如错判率最小或错判损失最小。
常用的方法有:距离判别法,Fisher判别法,贝叶斯判别法,逐步判别法。
判别分析的各阶段需要把握以下原则:事前的分类标准要尽可能准确和可靠;所分析的自变量应是因变量的重要影响因素, 应该挑选既有重要特性又有区别能力的变量, 达到以最少的变量实现强辨别能力的目的;初始分析数据(作为训练集的个案数)不能太少.
(1)贝叶斯判别法
基本思想:总是假设对所研究的对象已有一定的认识(每类密度已知或可估计),计算新给样品属于各总体的条件概率![]() 。比较这个概率的大小,然后将新样品判归为来自概率最大的总体。
。比较这个概率的大小,然后将新样品判归为来自概率最大的总体。
例:人文发展指数是联合国开发计划署于1990年5月发表的一份《人类发展报告》中公布的数据如下,试通过已知的样品建立判别函数,误判率是多少?并判断待判的归类。
data ex;input g x1-x3 @@;
cards;
1 76 99 5374 1 79.5 99 5359 1 78 99 5372
1 72.1 95.9 5242 1 73.8 77.7 5370 2 71.2 93
4250 2 75.3 94.9 3412 2 70 91.2 3390 2 72.8
99 2300 2 62.9 80.6 3799
;
data ex1; input x1-x3 @@;
cards;
68.5 79.3 1950 69.9 96.9 2840 77.6 93.8 5233
69.3 90.3 5159
;
proc discrim data=ex testdata=ex1
anova manova simple list testout=ex2;
class g; var x1-x3;proc print
data=ex2;run;(1)Data=数据集名,指定输入数据集名,若缺省则指定最新建立的数据集。
(2)Testdata=数据集名,指定待作出判别的数据集名,其中的变量名须上Data数据集中的变量名一致。
(3)Testout=数据集名,指定输出数据集,输出Testdata数据集中所有观测值以及每个观测值的后验概率和判别后的类别。
(4)List,指定打印每个观测值的回代结果。
(5)Anova,指定输出各类均值检验的一元统计量。
(6)Manova,指定输出各类均值检验的多元统计量。
(7)Simple,指定打印总体和组内的简单统计量。

判别函数为
y1=-323.21568+5.79107x1+0.26498x2+0.03407x3;y2=-236.03823+5.14034x1+0.25167x2+0.02533x3
 :两类误判概率均为零。
:两类误判概率均为零。
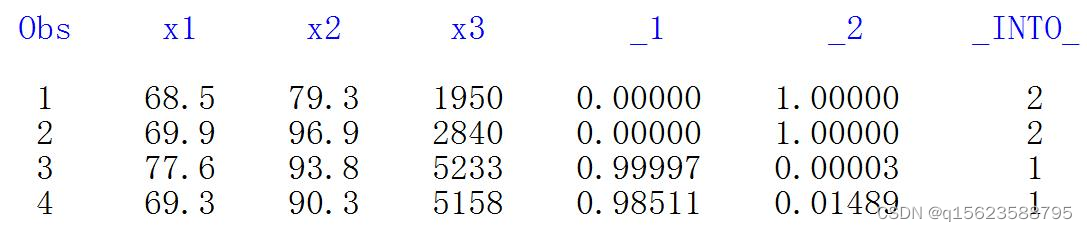
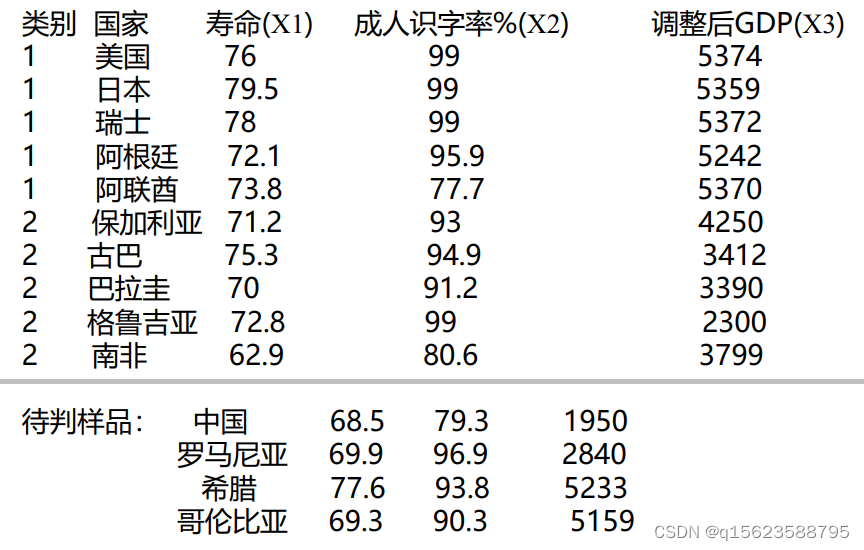
由上可知中国与罗马尼亚归入第二类,希腊与哥伦比亚归入第一类。
一个判别函数的判别样本归类的功能强弱很大程度上取决于指标的选取。如果判别函数中特异性强的指标越多,则判别函数的判别功能也就越强。相反,不重要的指标越多,判别函数就越不稳定,其判别效果非但得不到改善,甚至会适得其反。因此,要建立一个有效的判别函数,指标的选取很重要,过多过少都不一定合适。一方面要根据专业知识和经验来筛选指标,另一方面要借助统计分析方法检验指标的性能。
(2)逐步判别法
在判别问题中,当判别变量个数较多时,如果不加选择地一概采用来建立判别函数,不仅计算量大,还由于变量之间的相关性,可能使求解逆矩阵的计算精度下降,建立的判别函数不稳定。因此适当地筛选变量的问题就成为一个很重要的事情。凡具有筛选变量能力的判别分析方法就统称为逐步判别法。类似于逐步回归分析
步骤:
1.计算各总体中各变量的均值和总均值以及似然统计量,
规定引入变量和剔除变量的临界值F进、F出。
2.逐步计算,计算全部变量的判别能力,在已入选变量中考虑剔除可能存在的最不显著变量。在未选入变量中选出最大判别能力的变量,对变量作F检验通过检验则接受,否则剔除变量。直到能剔除又不能增加新变量,逐步计算结束。
3.建立判别式,使用第2步中选入的变量,建立判别式。
4.对待判样本进行判别分类。
data ex;
input g x1-x3 @@;
cards;
1 76 99 5374 1 79.5 99 5359 1 78 99 5372 1 72.1 95.9 5242 1 73.8 77.7 5370 2 71.2
93 4250 2 75.3 94.9 3412 2 70 91.2 3390 2 72.8 99 2300 2 62.9 80.6 3799
;
data ex1; input x1-x3 @@;
cards;
68.5 79.3 1950 69.9 96.9
2840 77.6 93.8 5233 69.3 90.3 5159
;
proc stepdisc data=ex method=stepwise sle=0.3 sls=0.3;
/*选择用逐步判别法,sle引入变量的显著性水平,sls剔除变量的显著
性水平。不注明时系统默认为0.15*/
class g; var x1-x3;
run;1.逐步判别选取变量:
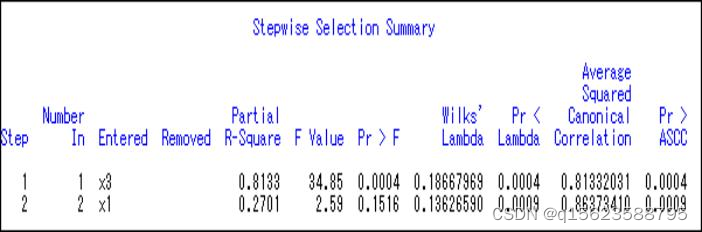
结果显示:通过逐步判别分析选入两个变量X1、X3作为判别分析的指标,接下来再以变量X1 ,X3为参考变量作Bayes判别。
data ex;
input g x1-x3 @@;
cards;
1 76 99 5374 1 79.5 99 5359 1 78 99 5372 1 72.1 95.9 5242 1 73.8 77.7 5370 2 71.2
93 4250 2 75.3 94.9 3412 2 70 91.2 3390 2 72.8 99 2300 2 62.9 80.6 3799
;
data ex1; input x1-x3 @@;
cards;
68.5 79.3 1950 69.9 96.9
2840 77.6 93.8 5233 69.3 90.3 5159
;
proc discrim data=ex testdata=ex1 /*待判别集合*/
anova manova simple list testout=ex2;
class g; var x1 x3; /*选用x1和x3作为判别指标*/
proc print data=ex2;
run;2.得到判别函数:

y1 = -322.01658 + 6.13904x1 + 0x2 + 0.03335x3
y2 = -234.95662 + 5.47083x1 + 0x2 + 0.02465x3
3.误判概率:
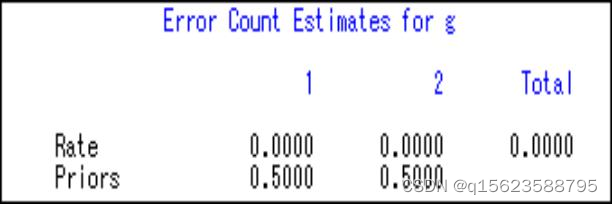
两类的误判率均为0,说明判别能力很强,于是 可以利用已经得到的判别函数去判别新样本。
4.待判样本分类结果:
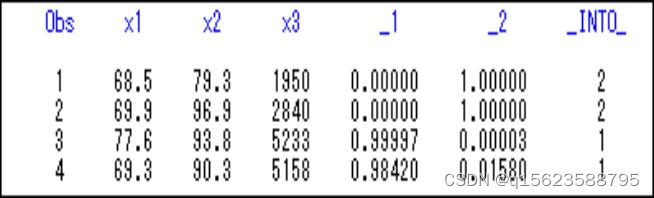
结果表明,中国与罗马尼亚归入第二类,希 腊与哥伦比亚归入第一类。

















 444
444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









