







使用*或//来注释单行或多行代码,Ctrl + / 为选中段落加注释。Ctrl加Enter是在命令窗口里换行
Stata文件种类:
.dta (Stata datafile),应该按照各个版本去保存
.do(Stata命令文件);
.smcl或者 .log(Stata output log file)
最流行的
Stata 非官方命令下载平台为“统计软件成分”
(Statistical Software Components
,
SSC), 由
Boston College 维护,网址为
http://ideas.repec.org/s/boc/bocode.html
相关命令:
ssc new (
罗列
SSC
的最新非官方
Stata
命令及简介
)
ssc install newcommand (
安装
SSC 非官方命令 “
newcommand
”
)
下载东西的时候要确定路径是英文名,不然识别不出来。
如果要使用某种估计方法,但不知道它是否存在,可搜索:
search keyword (
搜索帮助文件、
FAQs
、例子、
Stata
Journal
(SJ),
Stata Technical Bulletin
(STB)
等
)
findit keyword (
搜索以上内容,以及
Stata 的网络资源
)
实例操作
以 Nerlove(1963)对电力行业规模报酬的经典研究来介绍 Stata 的实际操作。该数据集nerlove.xls (Excel文件) 包括了 1955 年美国 145 家电力企业的横截面数据。
1.数据导入(Excel)
点击菜单 File → Import,然后导入各种格式的数据。
导入后,即会看到右上方的Variables窗口出现了5 个变量,分别为
TC(total cost,总成本)
Q(total output,总产量)
PL(price of labor,小时工资率)
PF(price of fuel,燃料价格)
PK(user cost of capital,资本的租赁价格)
点击 Save 图标 (也可点击菜单File → Save),将数据存为 Stata 格式的文件(扩展名为 dta ),比如nerlove.dta。(Excel转dta)
打开的方式有两种:
方法一:点击 Open 图标 (也可点击菜单 File → Open),寻找要打开的 dta 文件位置。
方法二:在命令窗口输入以下命令并回车(按 Enter 键): use “文件地址”, clear
其中,逗号“,”之后的“clear”为“选择项”(option),表示可替代内存中的已有数据。
如要关闭一个数据集,以便使用另外一个数据集,可输入命令: clear /clear all
2.变量的标签
在变量窗口,变量的“名字”(Name) 右边显示 其“标签”(label)。
法一:点击菜单Data → Variables Manager,然后编辑变量名、标签以及变量的存储格式。
例:把 TC,Q,PL,PF 与 PK 的标签分别改为“total cost”“total output”,“price of labor”,“price of fuel”与“user cost of capital”。
法二:输入命令:label variable 变量 “标签名"
3.生成新变量及变量重命名
其中:
一:生成新变量
原变量取对数:gen lnTC=log(TC)
生成平方项Q2:gen Q2=Q^2
生成交互项lnPL×lnPK:gen lnPLlnPK=lnPL*lnPK
二:变量重命名
rename old_varname new_varname
4.审视数据
想看数据集中的变量名单、标签等,可输入命令:
describe
其中,“
describe”的下划线表示,可将该命令简写为 “
d
”。
给数据集加一个标签,说明来自“Nerlove 1963 paper”:
label data "Nerlove 1963 paper"
再次运行命令“
describe” ,就会看到数据集的标签 “
Nerlove 1963 paper
”
种一:如果想看变量
TC
与
Q 的具体数据,可使用命令:
list TC Q
如想中途停止该命令的执行,可点击
Break
图标。
种二:只对数据集的一部分执行命令,比如只看
TC 与 Q
的前
5
个数据:
list TC Q in 1/5
如要罗列从第
32-36
个观测值,可输入命令:
list TC Q in 32/36
种三:也可通过逻辑关系来定义数据集的子集。如要列出所有满足条 件“
Q
≥
10000”
的变量
TC
与
Q 的数据,可使用以下命令:
list TC Q if Q >= 10000
种四:查看具体数据的直接方法是,点击 Data Editor (Edit)
图标,或者点击该图标右边的 Data Editor (Browse)
图标。
如要删除满足“
Q
≥
10000”条件的观测值,输入命令:
drop if Q >= 10000
如只想保留满足“
Q
≥
10000”条件的观测值,可使用命令:
keep if Q >= 10000
5.考察变量的统计特征
如果看变量
Q
的统计特征,可输入命令:
summarize Q (su Q)
显示变量
Q 的样本容量、平均值、标准差、最小值与 最大值。
如想看更多的统计指标,使用命令:
su Q, detail
新增的统计指标有百分位数
(percentiles),方差(variance)
,偏度
(skewness)
与峰度
(kurtosis)
。
如果要显示变量
PL 的经验累积分布函数 (empirical cumulative distribution function),
可使用命令:
tabulate PL
如要显示内存中 3 个价格变量之间的相关系数,输入命令:
pwcorr PL PF PK,sig star(.05)
选择项“
sig
”表示显示相关系数的显著性水平
(
即 𝑝值,列在相关系数的下方
)
,选择项“
star(.05)
”表示
给所有显著性水平小于或等于
5%的相关系数打上星号。
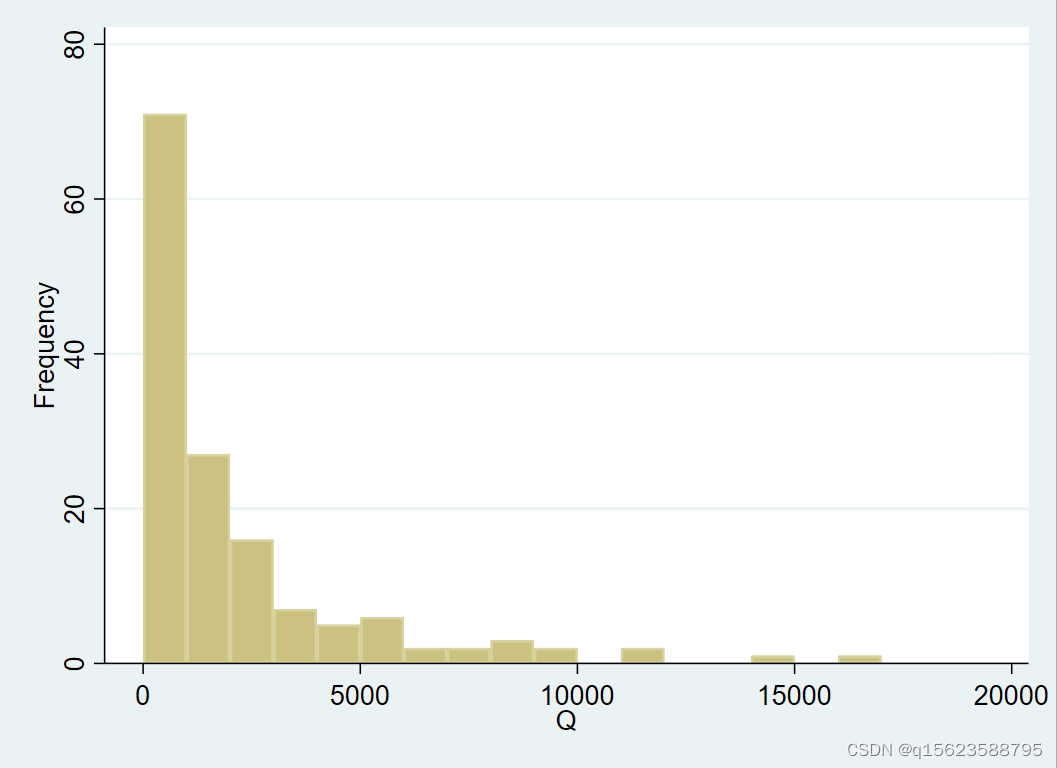
6.画图
画变量
Q
的直方图
(
假定组宽为
1000),输入命令:
histogram Q, width(1000) frequency
逗号“
,
”之后的“
width(1000)
”与“
frequency”为“选择项”
(options)
,分别表示将组宽设为
1000,将纵坐标定为频数。
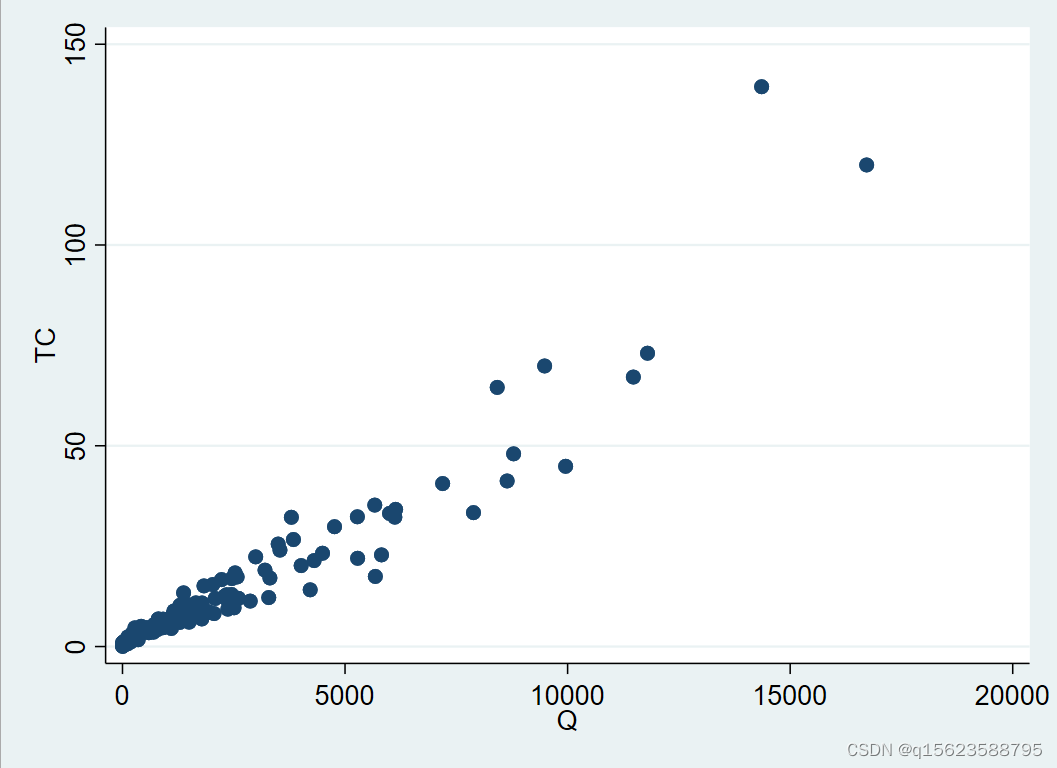
画
TC
与
Q 之间的散点图,输入命令:
scatter TC Q
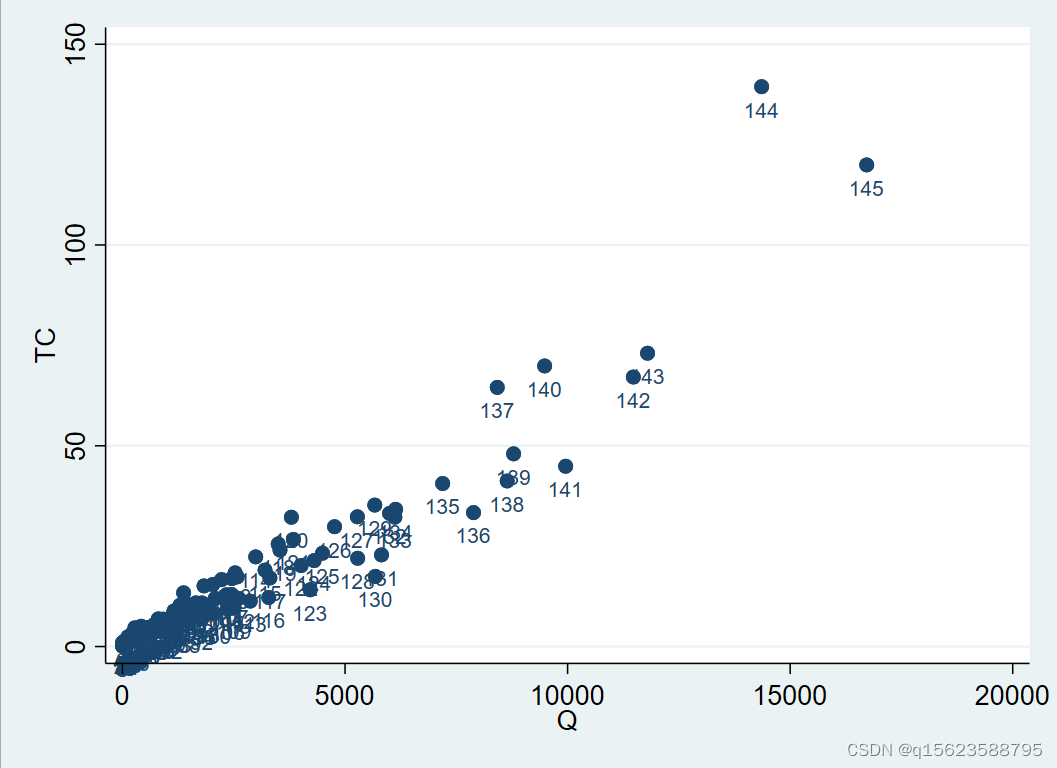
在上面的散点图中,无法知道每个点分别对应哪个观测值。为此,首先定义一个新变量“
n
”来表示
第
n 个观测值:
gen n=_n
其中,“
_n
”即表示第
n
个观测值。
输入命令:
scatter TC Q, mlabel(n) mlabpos(6)
选择项“
mlabel(n)
”表示以变量“
n
”作为“mark label
”
(
标签
)
;选择项“
mlabpos(6)
”(mark label position) 表示将此标签放在散点正下方
(6
点钟的位置
),默认位置为散点的右边
(3
点钟
)
。
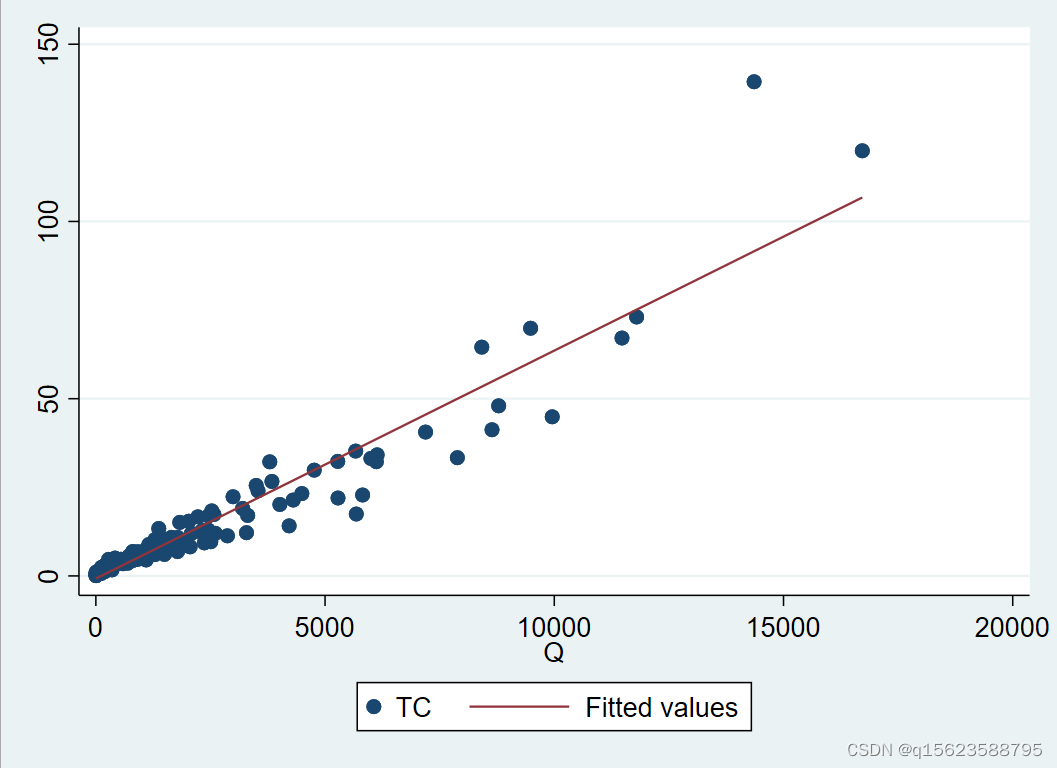
如想在散点图上同时画出回归直线,使用命令: twoway (scatter TC Q)(lfit TC Q)
其中,“
lfit
”表示“
linear fit
”
(
线性拟合
)
。
如想在散点图上同时画出二次回归曲线,使用命令:
twoway (scatter TC Q)(qfit TC Q)
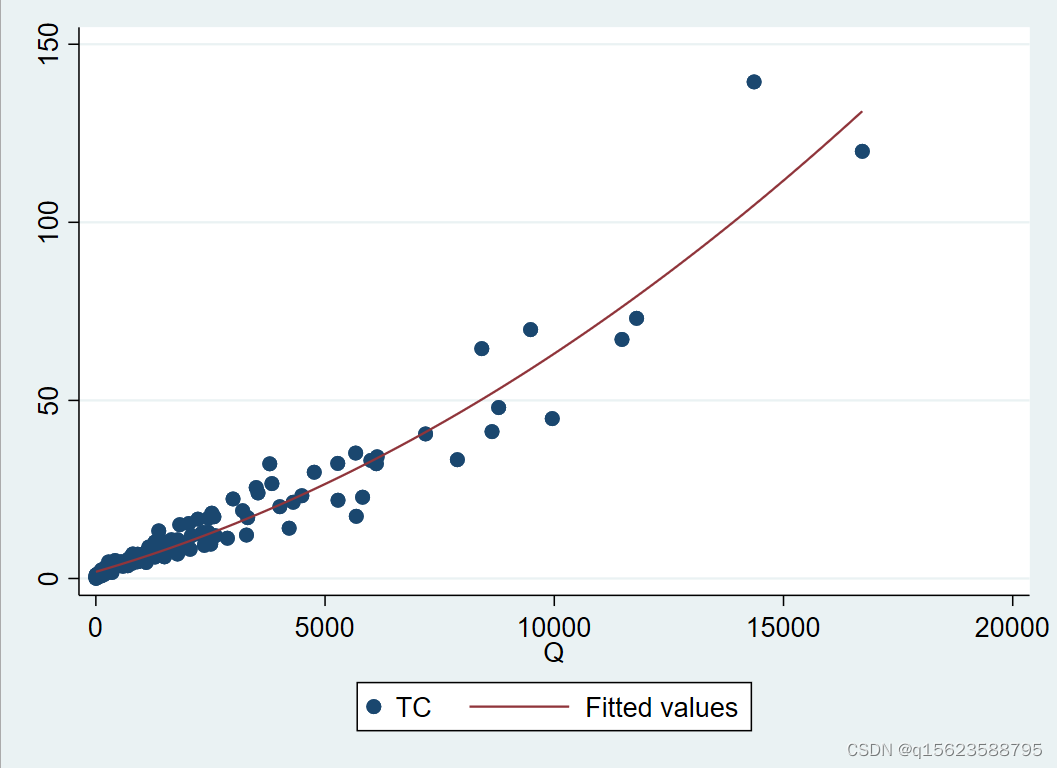
graph combine scatter1.gph scatter2.gph
更多作图方法,参见菜单“
Graphics”。对于任何命令,只要输入“
help command
”
(
比如,help histogram)
,即可看到详细说明
7.线性回归分析
一元线性回归: Stata
中回归分析的命令为
regress
,可简写为reg
reg y x [
,
option]
其中,
y
为因变量
,x
为自变量。
[
,
option]为添加的条件表达式
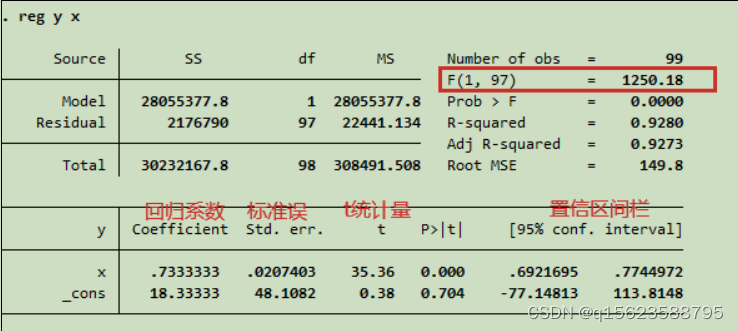 𝑦 = 18.33 + 0.73x
𝑦 = 18.33 + 0.73x
多元线性回归: reg y x1 x2 x3 x4 [
,
option]
在进行回归时,若不需要常数项 reg educ exper tenure numdep, noc
若只对女性子样本进行回归 reg educ exper tenure numdep if female==1
模型拟合值与残差:
predict yhat
计算被解释变量的拟合值,并记为
yhat
predict e1, residuals
计算残差,并记
e1
估算方差与协方差矩阵
qui reg educ exper tenure numdep
vce
估算方差膨胀因子
qui reg educ exper tenure numdep
vif
// Stata文件种类:
// .dta (Stata datafile),应该按照各个版本去保存
// .do(Stata命令文件);
// .smcl或者 .log(Stata output log file)
*******************************实例操作***********************************
// 以 Nerlove(1963)对电力行业规模报酬的经典研究来介绍 Stata 的实际操作。该数据集 nerlove.xls
// (Excel文件) 包括了 1955 年美国 145 家电力企业的横截面数据。
**************************1.数据导入***************************
// 点击菜单 File → Import,然后导入各种格式的数据。
// 导入后,即会看到右上方的Variables窗口出现了5 个变量,分别为
// TC(total cost,总成本)
// Q(total output,总产量)
// PL(price of labor,小时工资率)
// PF(price of fuel,燃料价格)
// PK(user cost of capital,资本的租赁价格)
// 点击 Save 图标 (也可点击菜单File → Save),将数据存为 Stata 格式的文件(扩展名为 dta ),比如nerlove.dta。
// 打开的方式有两种:
// 方法一:点击 Open 图标 (也可点击菜单 File → Open),寻找要打开的 dta 文件位置。
// 方法二:在命令窗口输入以下命令并回车(按 Enter 键): use “文件地址”, clear
// 其中,逗号“,”之后的“clear”为“选择项”(option),表示可替代内存中的已有数据。
// 如要关闭一个数据集,以便使用另外一个数据集,可输入命令:
clear /clear all
************************2.变量的标签*****************************
// 在变量窗口,变量的“名字”(Name) 右边显示其“标签”(label)。
// 点击菜单Data → Variables Manager,然后编辑变量名、标签以及变量的存储格式。
// 例:把 TC,Q,PL,PF 与 PK 的标签分别改为“total cost”“total output”,“price of labor”,“price of fuel”与“user cost of capital”。
// 或输入命令:label variable 变量 “标签名"
************************3.生成新变量及变量重命名******************************
// 生成新变量
// 原变量取对数:
gen lnTC=log(TC)
// 生成平方项Q2:
gen Q2=Q^2
// 生成交互项lnPL×lnPK:
gen lnPLlnPK=lnPL*lnPK
// 变量重命名
rename old_varname new_varname
************************4。审视数据********************************************
// 想看数据集中的变量名单、标签等,可输入命令:
describe
d
// 其中,“describe”的下划线表示,可将该命令简写为“d”。
// 给数据集加一个标签,说明来自“Nerlove 1963 paper”:
label data "Nerlove 1963 paper"
// 再次运行命令“describe”,就会看到数据集的标签“Nerlove 1963 paper”
// 如果想看变量 TC 与 Q 的具体数据,可使用命令:
list TC Q
// 如想中途停止该命令的执行,可点击 Break 图标。
// 只对数据集的一部分执行命令,比如只看 TC 与Q 的前 5 个数据:
list TC Q in 1/5
// 如要罗列从第 32-36 个观测值,可输入命令:
list TC Q in 32/36
// 也可通过逻辑关系来定义数据集的子集。如要列出所有满足条 件“Q ≥ 10000”的变量 TC 与 Q 的数据,可使用以下命令:
list TC Q if Q >= 10000
// 查看具体数据的直接方法是,点击 Data Editor (Edit)图标,
// 或者点击该图标右边的 Data Editor (Browse)图标。
// 如要删除满足“Q ≥ 10000”条件的观测值,输入命令:
drop if Q >= 10000
// 如只想保留满足“Q ≥ 10000”条件的观测值,可使用命令:
keep if Q >= 10000
***********************5.考察变量的统计特征*************************************
// 如果看变量 Q 的统计特征,可输入命令:
summarize Q
// 显示变量 Q 的样本容量、平均值、标准差、最小值与最大值。
// 如想看更多的统计指标,使用命令:
su Q, detail
//新增的统计指标有百分位数(percentiles),方差(variance),偏度(skewness)与峰度(kurtosis)。
// 如果要显示变量PL 的经验累积分布函数
// (empirical cumulative distribution function),可使用命令:
tabulate PL
// 如要显示内存中 3 个价格变量之间的相关系数,输入命令:
pwcorr PL PF PK,sig star(.05)
// 选择项“sig”表示显示相关系数的显著性水平(即 𝑝值,列在相关系数的下方),
// 选择项“star(.05)”表示给所有显著性水平小于或等于 5%的相关系数打上星号。
************************6.画图**************************************************
// 1. 画变量 Q 的直方图(假定组宽为 1000),输入命令:
histogram Q, width(1000) frequency
// 逗号“,”之后的“width(1000)”与“frequency”为“选择项”(options),
// 分别表示将组宽设为 1000,将纵坐标定为频数
// 2.1 画 TC 与 Q 之间的散点图,输入命令:
scatter TC Q
// 2.2 在上页的散点图中,无法知道每个点分别对应哪个观测值。
// 为此,首先定义一个新变量“n”来表示第 n 个观测值:
// 其中,“_n”即表示第 n 个观测值。
gen n=_n
// 2.3 输入命令:
scatter TC Q, mlabel(n) mlabpos(6)
// 选择项“mlabel(n)”表示以变量“n”作为“mark label”(标签);
//选择项“mlabpos(6)”(mark label position)表示将此标签放在散点正下方(6 点钟的位置),默认位置为散点的右边(3 点钟)。
// 2.4 如想在散点图上同时画出回归直线,使用命令:
// 其中,“lfit”表示“linear fit”(线性拟合)。
twoway (scatter TC Q)(lfit TC Q)
// 2.5 如想在散点图上同时画出二次回归曲线,使用命令:
twoway (scatter TC Q)(qfit TC Q)
// 2.6 将上述两张图并列排放在一张图上:
graph combine scatter1.gph scatter2.gph
//更多作图方法,参见菜单“Graphics”。对于任何命令,只要输入“help
// command”(比如,help histogram),即可看到详细说明。
***********************7.线性回归分析*******************************************
// 1. 一元线性回归:
// Stata中回归分析的命令为regress,可简写为reg
// 其中,y为因变量,x为自变量。[,option]为添加的条件表达式
// reg y x [,option]
reg TC Q
// 2. 多元线性回归:
// reg y x1 x2 x3 x4 [,option]
reg TC Q PL
// 3. 线性回归分析
// 在进行回归时,若不需要常数项
reg educ exper tenure numdep, noc
// 若只对女性子样本进行回归
reg educ exper tenure numdep if female==1
// 模型拟合值与残差
predict yhat //计算被解释变量的拟合值,并记为yhat
predict e1, residuals //计算残差,并记e1
// 估算方差与协方差矩阵
qui reg educ exper tenure numdep
vce
// 估算方差膨胀因子
qui reg educ exper tenure numdep
vif
// 最流行的 Stata 非官方命令下载平台为“统计软件成分”(Statistical Software Components,SSC),
// 由 Boston College 维护,网址为
// http://ideas.repec.org/s/boc/bocode.html。
// 相关命令:
ssc new (罗列 SSC 的最新非官方 Stata 命令及简介)
ssc install newcommand (安装 SSC 非官方命令 “newcommand”)
// 如果要使用某种估计方法,但不知道它是否存在,可搜索:
search keyword
// (搜索帮助文件、FAQs、例子、Stata Journal (SJ), Stata Technical Bulletin (STB)等)
findit keyword (搜索以上内容,以及 Stata 的网络资源)

















 6480
6480

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









