







核心:某物与距它较近的事物的关联度大于与他距离较远的事物的关联度(也叫空间效应)。
怎么衡量空间效应:空间效应分为空间依赖性和空间异质性,衡量他需要空间数据。
空间数据的表现形式是空间权重矩阵W。其中矩阵W中的数据Wnm表示地区n和地区m是否是相邻的。其中1表示相邻,0表示不相邻;对称矩阵;对角线为零。
目录
概述:研究空间效应、空间数据
探究个体自变量x对其他个体因变量y的影响,考虑了横截面单位之间的空间依赖性(也叫空间相关性、空间相关性,例如地理环境、寡头竞争市场的厂商、模仿行为:差生模仿好生、溢出效应:贸易往来对多边联盟的形成有正的溢出效应、测量误差)。
空间(权重)矩阵:把空间效应纳入模型的媒介
1.分类:先选择具体哪一种
依据"距离"对位置进行量化(数字话):邻接距离、地理距离、经济距离、产业距离和技术距离。
邻近距离:相邻的边界
车相邻(共同的边)、象相邻(共同的顶点)、后相邻(公共的边或公共的顶点)
地理距离:欧式距离的倒数
根据区域的质心坐标计算两区域间的欧式距离。矩阵里的元素一般是距离的倒数(因为距离越小,元素越大,越相关)。pace提出了关于距离的(不是关于元素的)具体的一个临界值,大于取0,小于取1.
经济距离:刻画经济发展的指标的倒数
通过经济指标的差值刻画两地距离:GDP、人均GDP 差值的绝对值。同样的矩阵里的元素也是距离的倒数。
产业距离同经济距离。技术距离还没学。
综合距离(看论文找一下、问一下)
采用单个距离指标进行量化,构造空间权重矩阵、不能全面衡量空间相关性。故可以按照相对重要程度对各距离进行加权平均处理,得到综合距离。
2.标准化处理
原因
1.未处理的矩阵都是对称矩阵(双向),与现实不符:空间效应是非双向的(差生模仿好生)
2.无法显示邻居空间效应的相对距离强弱:邻近距离长短不一样,不能简单的判断为1或0.例如湖南和湖北邻近距离大于湖南和重庆的邻近距离(应该湖南和湖北的相关强一点),但是反映在未处理的矩阵上都是1.
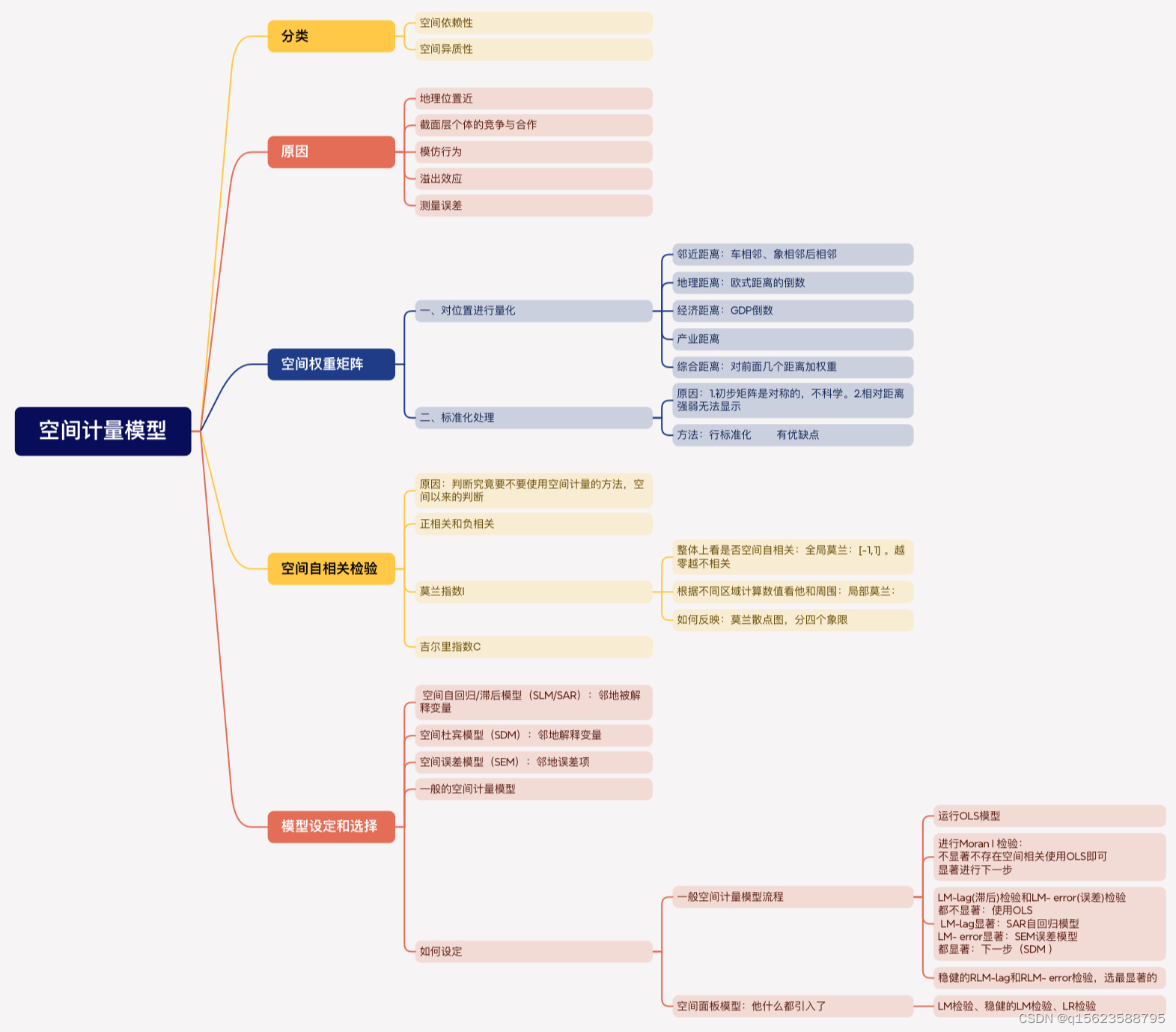
方法:行标准化
行标准化:分子可以理解成是区域 i 与区域 j 间的空间距离,分母是区域 i 与其他区域的空间距离总和。
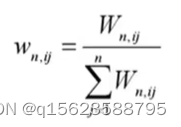 例如:
例如:
优点:
缺点:将矩阵标准化后,由于每行元素之和均为1,这意味着区域 i 所受其邻居的影响之和一定等于区域 j 所受其邻居的影响之和(任何 i != j ):此假设可能过强。
空间自相关检验:究竟要不要用空间计量
可以理解为位置相近的区域具有相似的变量取值。如果高值与高值集聚在一起,低值与低值集聚在一起,则为“正空间自相关”;反之,如果高值与低值相邻,则为“负空间自相关”;如果高值与低值完全随机地分布,则不存在空间自相关。
目前常用来考察数据空间自相关的指标为Morans'I 莫兰指数 I 和Geary's C 吉尔里指数 C ,其中莫兰指数是最常用的。
1.莫兰指数 I
全局莫兰指数 spatgsa globe的

取值一般介于-1到1之间,大于0表示正自相关,即高值与高值相邻、低值与低值相邻;小于0表示负自相关,即高值与低值相邻。一般来说,正自相关比负自相关更常见。如果莫兰指数I接近于0,则表明空间分布是随机的,不存在空间自相关。全局莫兰指数可以视为观测值与其空间滞后(观测值周围邻居数据的加权平均)的相关系数。
局部莫兰指数 spatlsa local的
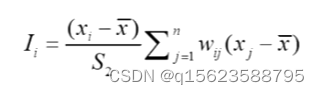
全局莫兰指数只能从整体上把握数据的空间自相关性,并不能对某个区域的空间集聚性进行识别。因此,还需要借助局部莫兰指数来解决该问题。如果为正数,表示区域 i 的高(低)值被周围的高(低)值所包围;如果
为负数,则表示区域 i 的高(低)值被周围低(高)值所包围。
莫兰散点图
四个象限:一三象限局部莫兰指数大于零
2.吉尔里指数C(不常用,了解为主)

空间计量模型的设定与选择
1.空间自回归/滞后模型(SAR)
被解释变量间存在较强的空间依赖性,进而邻地被解释变量会通过空间传导机制影响到本地的被解释变量。(技术扩散)
2.空间杜宾模型(SDM)
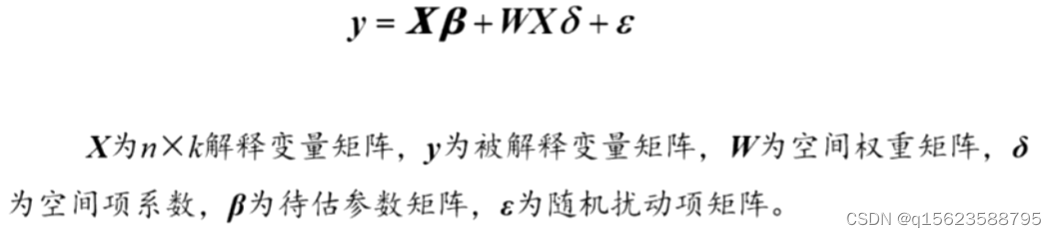
本地被解释变量的变化不仅受到本地解释变量的影响,还受到邻地解释变量的影响。(知识溢出效应)
3.空间误差模型(SEM)

在空间误差模型中,邻地误差项会通过空间传导机制影响本地的被解释变量的变化。该模型主要适用于研究机构或地区之间的相互作用因所处的相对位置不同而存在差异的情况。此外,遗漏变量和不正确的函数形式也会造成空间误差效应。
4.一般计量模型(针对截面)
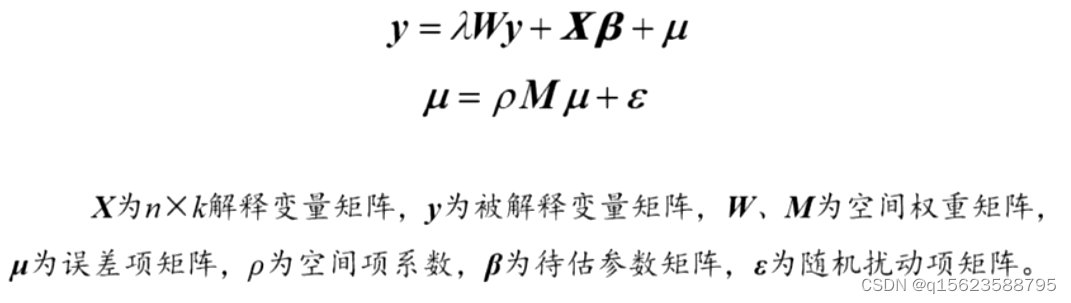
一般性的空间计量模型是将空间自回归模型、空间杜宾模型和空间误差模型结合,构建的具有一般化推广的空间计量模型
5.如何设定合适的空间模型
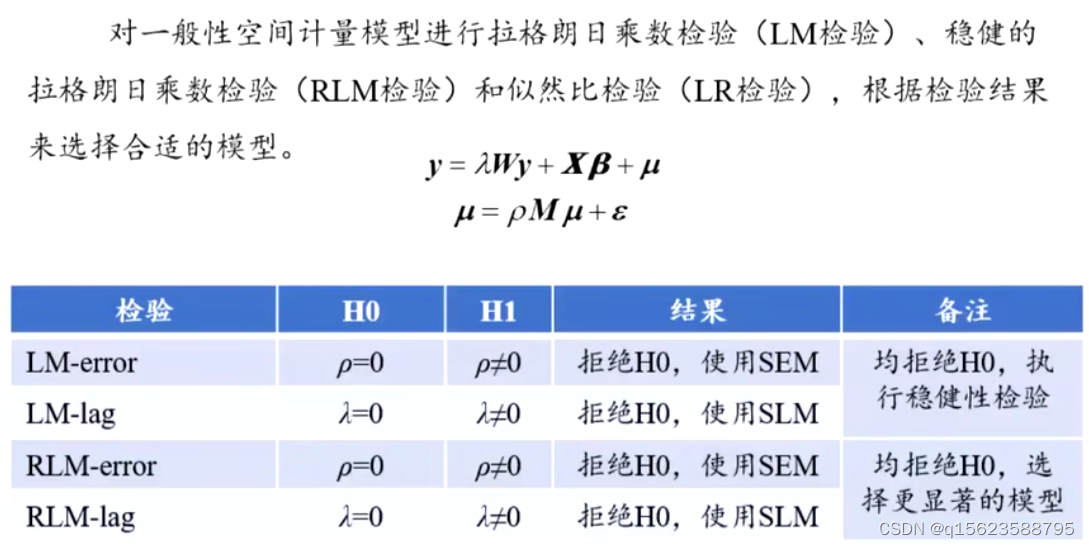

6.空间面板模型

空间面板模型和空间截面模型:
-
空间面板模型(Spatial Panel Model):
- 空间面板模型考虑了空间相关性,即不同地区(或单位)之间的相互影响。
- 空间面板模型假设不同地区之间存在空间依赖性,即一个地区的观测值可能受到邻近地区观测值的影响。
- 空间面板模型通常包括空间滞后项(Spatial Lag)或空间误差项(Spatial Error),用于捕捉地区之间的空间相关性。
- 空间面板模型常用的估计方法包括空间面板最小二乘法(Spatial Panel Least Squares)和空间面板广义矩估计(Spatial Panel Generalized Method of Moments)。
-
空间截面模型(Spatial Cross-Section Model):
- 空间截面模型主要关注不同地区(或单位)在同一时间点的观测数据。
- 空间截面模型假设不同地区之间的观测值是相互独立的,不考虑地区之间的空间相关性。
- 空间截面模型通常不包括空间滞后项或空间误差项。
- 空间截面模型的估计方法与传统的截面数据模型相似,可以使用最小二乘法等进行估计。
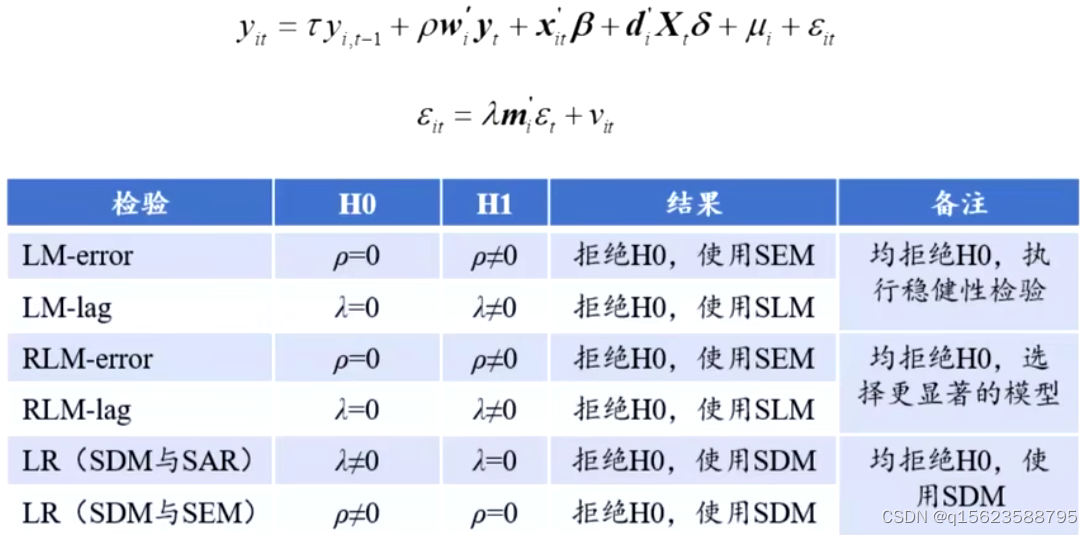
LM和稳健的LM(RLM)检验要不要引入空间滞后项,事前检验
LR检验是针对模型的检验,事后的检验,看是不是最优的,能不能退化成其他的
空间面板模型估计步骤
事前检验:莫兰检验、LM检验和RLM检验(判断模型是否需要引入空间项)
事后检验:LR检验、Wald检验、Hausmman检验(选择合适模型)
模型回归:选择变量合适形式,正式进行回归
效应分解:根据实际需求,进行空间效应分解(直接效应与间接效应)空间杜宾模型要做这个
稳健性检验/内生性检验/异方差检验
根据后续检验调整模型,直至模型稳健正确为止。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









