







理论介绍

上式中,
L(w)
为前向loss,N为一个mini-batch的batchsize,
fw(x(i))
是单个输入数据
x(i)
的输出loss,
λ
是正则项的权重,在caffe中是weight_decay,
r(w)
是一个关于参数
w
的正则项,在caffe中默认为L2正则项,即
在caffe中,forward只有前面一项,正则项是反向更新的时候才加上的。
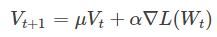
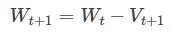
上面一式中, Vt 为更新的历史情况,在caffe中保存在history blob中, μ 为动量, ▽L(Wt) 为loss导数, α 为学习率。二是中,即为对权重进行更新。
SGD solver
任何一个solver的对权重进行更新时都要完成一次forward和backward。在solver.cpp中完成这一步的函数是step()。
template <typename Dtype>
void Solver<Dtype>::Step(int iters) {
......
for (int i = 0; i < param_.iter_size(); ++i) {
loss += net_->ForwardBackward();//执行网络的forward和backward
}
......
ApplyUpdate();//更新参数
......执行完forward和backward后,就是对参数的更新,ApplyUpdate()函数完成这一操作。ApplyUpdate()函数是个虚函数,因此不同的solver可以实现不同的更新策略。在SGD中,主要有归一化、正则化、计算更新量、更新这四个函数。
template <typename Dtype>
void SGDSolver<Dtype>::ApplyUpdate() {
......
ClipGradients();
for (int param_id = 0; param_id < this->net_->learnable_params().size();
++param_id) {
Normalize(param_id);//归一化
Regularize(param_id);//正则化
ComputeUpdateValue(param_id, rate);//计算更新量
}
this->net_->Update();//更新
}假设为L2正则化,正则项的导数为w
template <typename Dtype>
void SGDSolver<Dtype>::Regularize(int param_id) {
......
if (regularization_type == "L2") {
// add weight decay
caffe_axpy(net_params[param_id]->count(),
local_decay,
net_params[param_id]->cpu_data(),
net_params[param_id]->mutable_cpu_diff());//diff=diff + decay * w
}
......
}然后计算更新量,并保存
template <typename Dtype>
void SGDSolver<Dtype>::ComputeUpdateValue(int param_id, Dtype rate) {
......
// Compute the update to history, then copy it to the parameter diff.
switch (Caffe::mode()) {
case Caffe::CPU: {
//history = momentum * history + diff * learning_rate
caffe_cpu_axpby(net_params[param_id]->count(), local_rate,
net_params[param_id]->cpu_diff(), momentum,
history_[param_id]->mutable_cpu_data());
caffe_copy(net_params[param_id]->count(),//diff = history
history_[param_id]->cpu_data(),
net_params[param_id]->mutable_cpu_diff());
break;
}
......
default:
LOG(FATAL) << "Unknown caffe mode: " << Caffe::mode();
}
}最后对整个网络权重进行更新
this->net_->Update();整个网络的更新其实就是w-diff,在net.cpp中调用
template <typename Dtype>
void Net<Dtype>::Update() {
for (int i = 0; i < learnable_params_.size(); ++i) {
learnable_params_[i]->Update();//w-diff
}
}这里其实就是调用了blob的update进行更新。















 3156
3156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









