







MapReduce设计理念:移动计算,而不移动数据
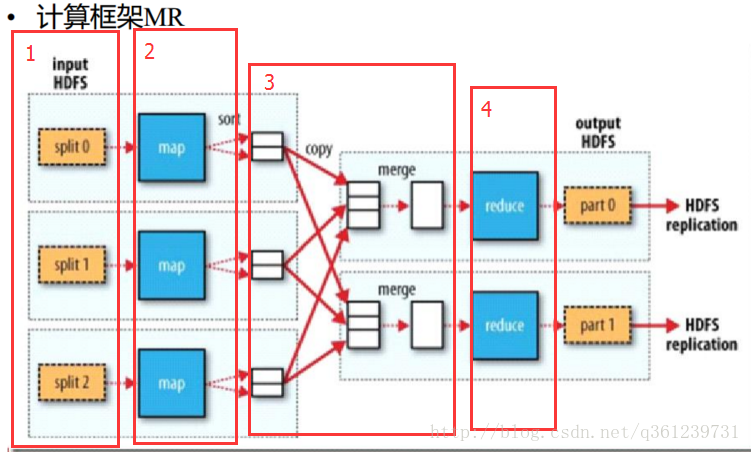
计算框架MR说明:
- 分为4个步骤,按顺序执行:
- split(左浅黄色框):将单个的block进行切割,得到数据片段。
- map Task(左蓝色框):自己写的map程序,一个map程序就叫一个map任务,有多少个碎片,就有多少个map任务(Java线程),输入的数据就是键值对数据,输出的数据也是键值对。
- shuffle(洗牌,白色框):将map输出的数据进行分组、排序、合并。
- reduce Task(右蓝色框):在整个MapReduce执行过程中,默认只有一个Reduce Task(可以自己进行设定),自己写程序去定制计算内容,最后得到结果。
执行过程:
一个文件被切成1024个碎片段,对应着1024个Mapper Task,这些MapperTask在有碎片段的结点(DataNode)去执行,每个DataNode上都有个NodeManager来执行MapReduce程序,NodeManager有一个与之对应的AppMaster,由它负责请ResourceManager中去请求资源,这个资源被称为Container,AppMaster就会去执行MapperTask,通过Executer对象来执行,在执行过程中,会监控Mapper Taks的执行状态和执行进度,并想NodeManager汇报,然后NodeManager向ResourceManager汇报。Executer在调用MapperTask时,首先初始化这个类(通过反射),调用(只调用一次)setup()方法来进行初始化,之后循环调用map方法。因为有1024个MapperTask,那么Mapper程序会被初始化1024次。
MapReduce执行过程:
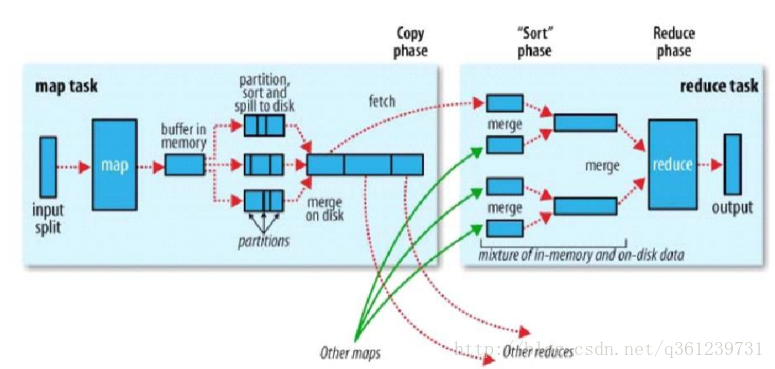
说明:
- spill to disk:map输出的数据放到内存中,溢出时,执行spill to disk
- partition:(默认由计算框架通过取模(key的hash值)算法)将map输出的key-value数据进行分区,并得到分区号。目的是将需要执行的数据分配到对应的reduce Task中。
- sort:将map task输出的数据,按key进行排序(默认为字典排序)。
- fetch:按照分区号来抓取数据,分配到对应的reduce task。
- sort phase:同上面的 3
- group:将数据按键值是否相等,分为一组。
- 将分组传给reduce进行计算
- 还有一个combiner过程,在下图讲解
Hadoop计算框架shuffle过程详解
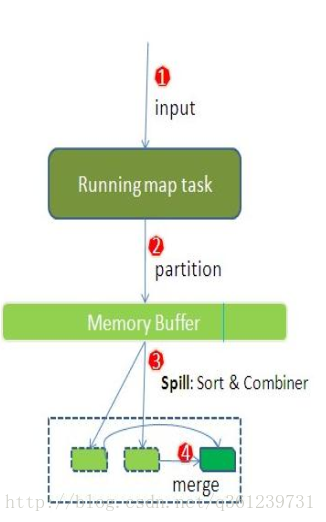
- 每个map task都有一个内存缓冲区(默认是100MB),存储着map的输出结果
- 当缓冲区快满的时候需要将缓冲区的数据以一个临时文件的方式存放到磁盘(Spill)
- 溢写是由单独线程来完成,不影响往缓冲区写map结果的线程(spill.percent,默认是0.8)
- 当溢写线程启动后,需要对这80MB空间内的key做排序(Sort)
Combiner讲解
- 假如client设置过Combiner,那么现在就是使用Combiner的时候了。 将有相同key的key/value对的value加起来,减少溢写到磁盘的数据量。(reduce1,word1,[8])。
- 当整个map task结束后再对磁盘中这个map task产生的所有临时文件做合并(Merge),对于“word1”就是像这样的:{“word1”, [5, 8, 2, …]},假如有Combiner,{word1 [15]},最终产生一个文件。
- reduce 从tasktracker copy数据
- copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比map端的更为灵活,它基于JVM的heap size设置
- merge有三种形式:1)内存到内存 2)内存到磁盘 3)磁盘到磁盘。 merge从不同tasktracker上拿到的数据,{word1 [15,17,2]}
MapReduce 的运行环境 YARN
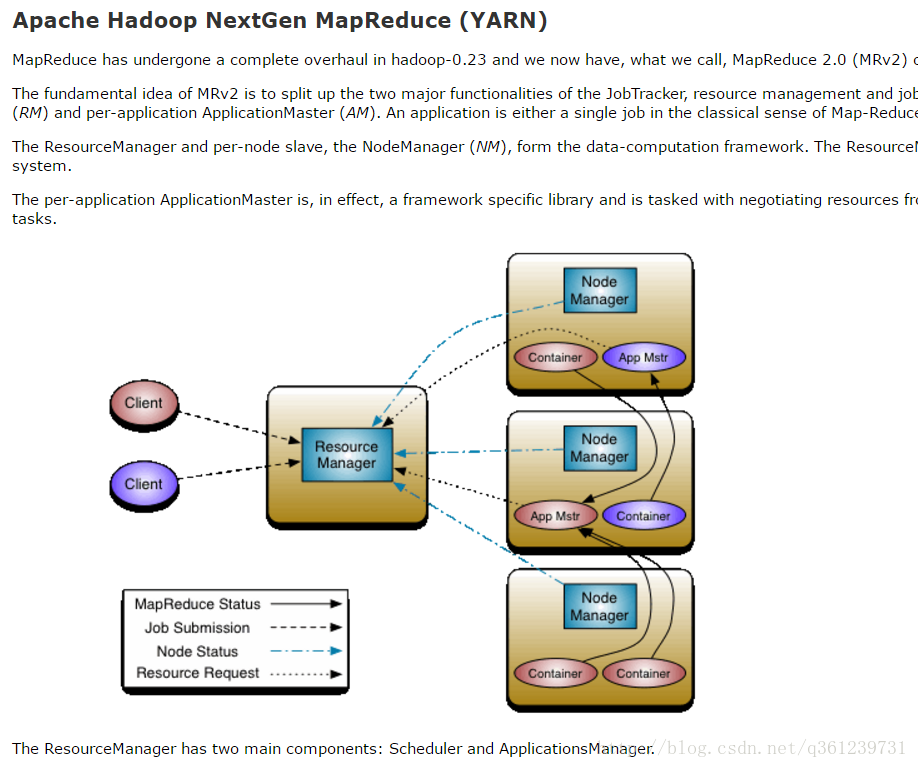
The ResourceManager has two main components: Scheduler and ApplicationsManager.
The Scheduler is responsible for allocating(分配) resources to the various(多方面的) running applications subject to familiar constraints(约束) of capacities(容量), queues etc. The Scheduler is pure scheduler in the sense that it performs no monitoring or tracking of status for the application. Also, it offers no guarantees(保证) about restarting failed tasks either due to application failure or hardware failures. The Scheduler performs its scheduling function based the resource requirements of the applications; it does so based on the abstract notion(概念) of a resource Container which incorporates(合并) elements such as memory, cpu, disk, network etc. In the first version, only memory is supported.
The Scheduler has a pluggable policy plug-in, which is responsible for partitioning the cluster resources among the various queues, applications etc. The current Map-Reduce schedulers such as the CapacityScheduler and the FairScheduler would be some examples of the plug-in.
The CapacityScheduler supports hierarchical queues to allow for more predictable sharing of cluster resources
The ApplicationsManager is responsible for accepting job-submissions, negotiating(协商) the first container for executing the application specific ApplicationMaster and provides the service for restarting the ApplicationMaster container on failure.
The NodeManager is the per-machine framework agent(代理) who is responsible for containers, monitoring their resource usage (cpu, memory, disk, network) and reporting the same to the ResourceManager/Scheduler.
The per-application ApplicationMaster has the responsibility of negotiating appropriate(恰当的) resource containers from the Scheduler, tracking their status and monitoring for progress.
MRV2 maintains(维持) API compatibility(兼容性) with previous stable release (hadoop-1.x). This means that all Map-Reduce jobs should still run unchanged on top of MRv2 with just a recompile.
程序员需要做的是,计算程序的开发。不需要去管Resource Manager















 2484
2484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









