






课程地址:https://github.com/huggingface/diffusion-models-class/blob/main/unit2/
今天跟随DataWhale的直播课程,进一步认识到模型的本质都是概率模型。扩散模型中通过在 UNet 下采样增加噪声,训练拟合噪声,在推理时从tn逐步预测t0的图像。
ControlNet 和 CLIP 等本质是在操控 UNet 的部分,同时 CLIP 是通过对比学习的方式通过图像文本对训练出来的。
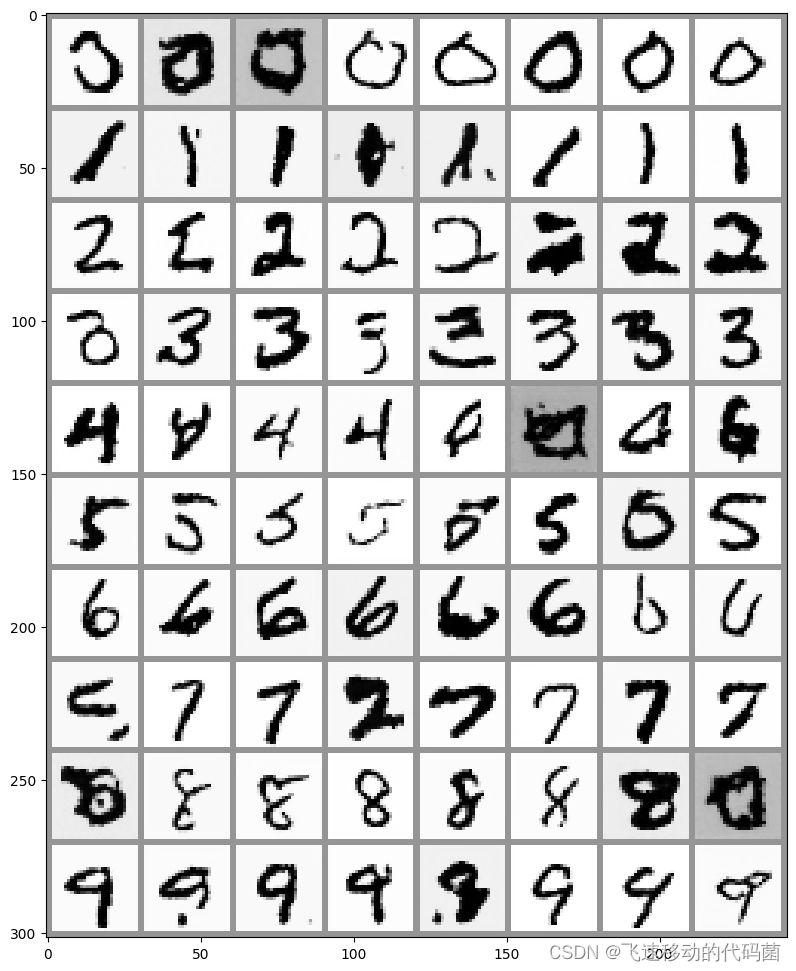
最后用扩散模型生成的手写数字如下图:
课程地址:https://github.com/huggingface/diffusion-models-class/blob/main/unit2/
今天跟随DataWhale的直播课程,进一步认识到模型的本质都是概率模型。扩散模型中通过在 UNet 下采样增加噪声,训练拟合噪声,在推理时从tn逐步预测t0的图像。
ControlNet 和 CLIP 等本质是在操控 UNet 的部分,同时 CLIP 是通过对比学习的方式通过图像文本对训练出来的。
最后用扩散模型生成的手写数字如下图:
 1683
382
767
1683
382
767











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言























