






原文章是使用tensorflow实现的,这里重新使用了PyTorch实现一下。
model.py
import torch
import torch.nn as nn
import numpy as np
class SmartphoneActivityRecognitionCNN(nn.Module):
def __init__(self, dropout_rate=0.3):
super(SmartphoneActivityRecognitionCNN, self).__init__()
# 卷积层部分
self.model =nn.Sequential(
nn.Conv1d(3, 96, kernel_size=(10,)),
nn.ReLU(),
nn.MaxPool1d(kernel_size=3,stride=3),
nn.Conv1d(96, 192, kernel_size=(10,)),
nn.ReLU(),
nn.MaxPool1d(kernel_size=3,stride=3)
)
# 全连接层部分
self.flatten = nn.Flatten()
self.dropout = nn.Dropout(dropout_rate)
self.fc = nn.Linear(1920, 6)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
x = self.model(x)
x = self.flatten(x)
x = self.dropout(x)
x = self.fc(x)
x = self.softmax(x)
return x
data.py
import torch
from torch.utils.data import Dataset
import numpy as np
import pandas as pd
from pandas import DataFrame
def feature_normalize(dataset):
mu = np.mean(dataset, axis=0)
sigma = np.std(dataset, axis=0)
return (dataset - mu) / sigma
class CNNDataset(Dataset):
def __init__(self,train = False,transfrom = None,file_path = "./datas/WISDM_ar_v1.1_fix.txt"):
super(CNNDataset, self).__init__()
column_names = ['user-id', 'activity', 'timestamp', 'x-axis', 'y-axis', 'z-axis']
self.data = pd.read_csv(file_path,header=None,names=column_names,on_bad_lines='skip')
self.data.dropna(axis=0,inplace=True)
self.data['x-axis'] = feature_normalize(self.data['x-axis'])
self.data['y-axis'] = feature_normalize(self.data['y-axis'])
self.data['z-axis'] = feature_normalize(self.data['z-axis'])
self.class_dict = {
"Walking":0,
"Jogging":1,
"Upstairs":2,
"Downstairs":3,
"Sitting":4,
"Standing":5
}
self.train = train
self.transfrom = transfrom
def __len__(self):
if self.train:
return int(((self.data.shape[0] - 64) * 0.7) / 64)
else:
return int(((self.data.shape[0]- 64) * 0.3) / 64)
def __getitem__(self,index):
bias = 0
if self.train == False:
bias = int((self.data.shape[0]- 64) * 0.7) + 1
x = self.data['x-axis'][bias + index * 64 : bias + index * 64 + 128]
y = self.data['y-axis'][bias + index * 64 : bias + index * 64 + 128]
z = self.data['z-axis'][bias + index * 64: bias + index * 64 + 128]
labels = self.data['activity'][bias + index * 64 : bias + index * 64 + 128].value_counts().idxmax()
# 创建3通道的numpy数组
datas = np.stack((x, y, z))
return torch.tensor(datas,dtype=torch.float32) , self.class_dict[labels]trian.py
import torchvision.transforms
from torch import nn
from model import SmartphoneActivityRecognitionCNN
from torch.utils.data import DataLoader
from data import CNNDataset
import torch
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter('./log')
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if __name__ == '__main__':
data_train = CNNDataset(train=True)
data_test = CNNDataset(train=False)
dataloader_train = DataLoader(data_train, batch_size=128, num_workers=3)
dataloader_test = DataLoader(data_test, batch_size=128, num_workers=3)
# 模型定义
model = SmartphoneActivityRecognitionCNN()
model = model.to(device)
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, weight_decay=0.00005, momentum=0.5)
epochs = 5000
train_counter = 0
for epoch in range(epochs):
print("Epoch {}/{}".format(epoch + 1, epochs))
model.train()
for datas, labels in dataloader_train:
datas = datas.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(datas)
loss = loss_fn(outputs, labels)
loss.backward()
optimizer.step()
train_counter += 1
writer.add_scalar('loss', loss.item(), train_counter)
if train_counter % 100 == 0:
print("总的训练次数: {},loss:{}".format(train_counter, loss.item()))
total_test_loss = 0.0
total_test_acc = 0.0
model.eval()
with torch.no_grad():
for datas, labels in dataloader_test:
datas = datas.to(device)
labels = labels.to(device)
outputs = model(datas)
test_loss = loss_fn(outputs, labels)
total_test_loss = total_test_loss + test_loss.item()
accuracy = (outputs.argmax(1)==labels).sum()
total_test_acc = total_test_acc + accuracy
print("整体测试集上的总loss: {}, acc: {}".format(total_test_loss, total_test_acc / len(data_test)))
writer.add_scalar('accuracy', total_test_acc / len(data_test) * 100, train_counter)
if epoch % 10 == 0:
torch.save(model.state_dict(), "./weights/model{}.pth".format(epoch))
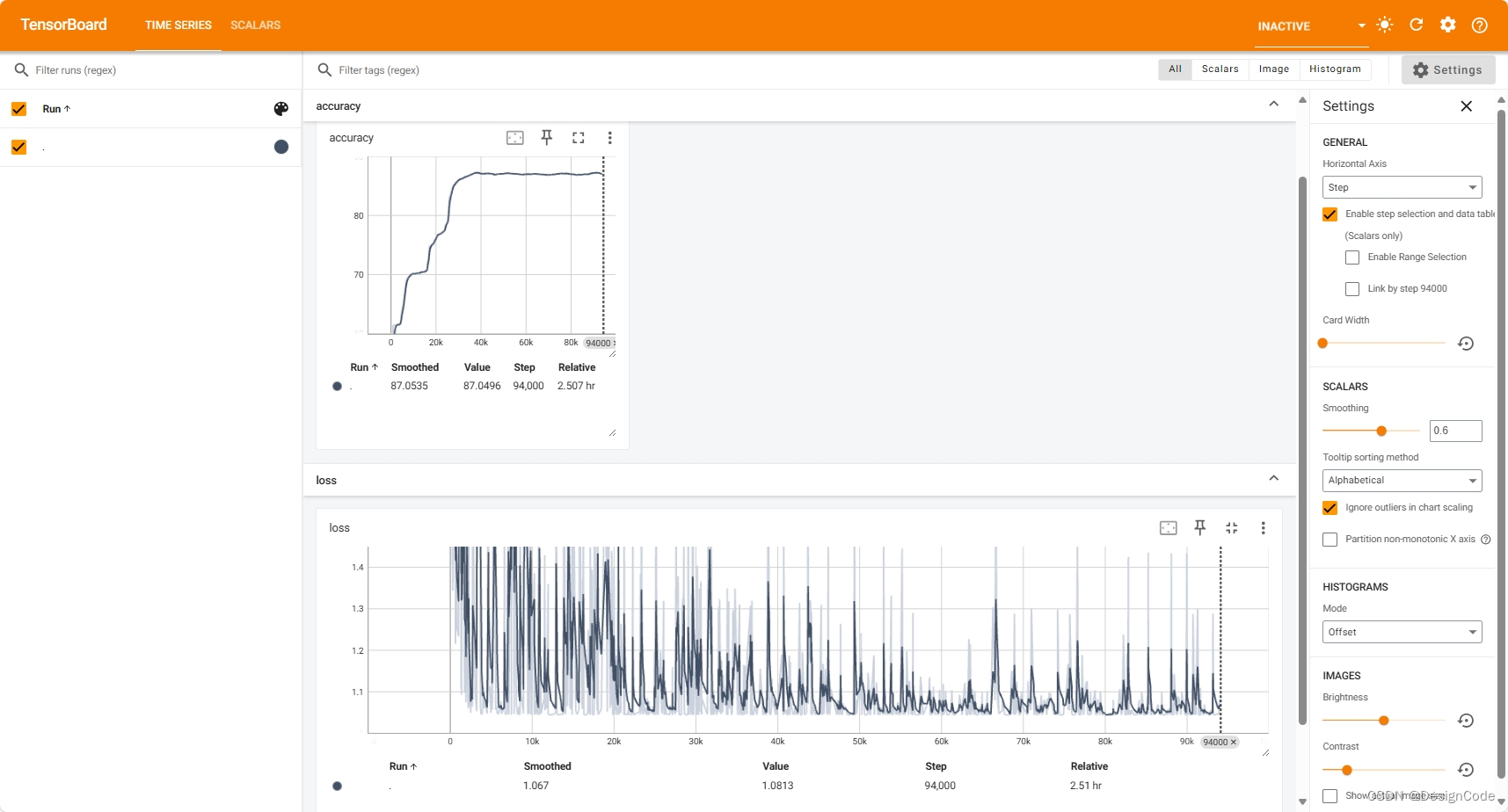
writer.close()但是有个问题就是总是跑不到原文章的88%的准确度,不知道是哪里出现了问题有懂得大佬评论一下!















 839
839











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









