










[毕业设计]2023-2024年最新最全计算机专业毕设选题推荐汇总
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人 。
1、项目介绍
Python、Flask框架、MySQL数据库、selenium爬虫框架
预测模型:model_final.py 线性回归模型
采集:猎聘网
https://www.liepin.com/zhaopin
2、项目界面
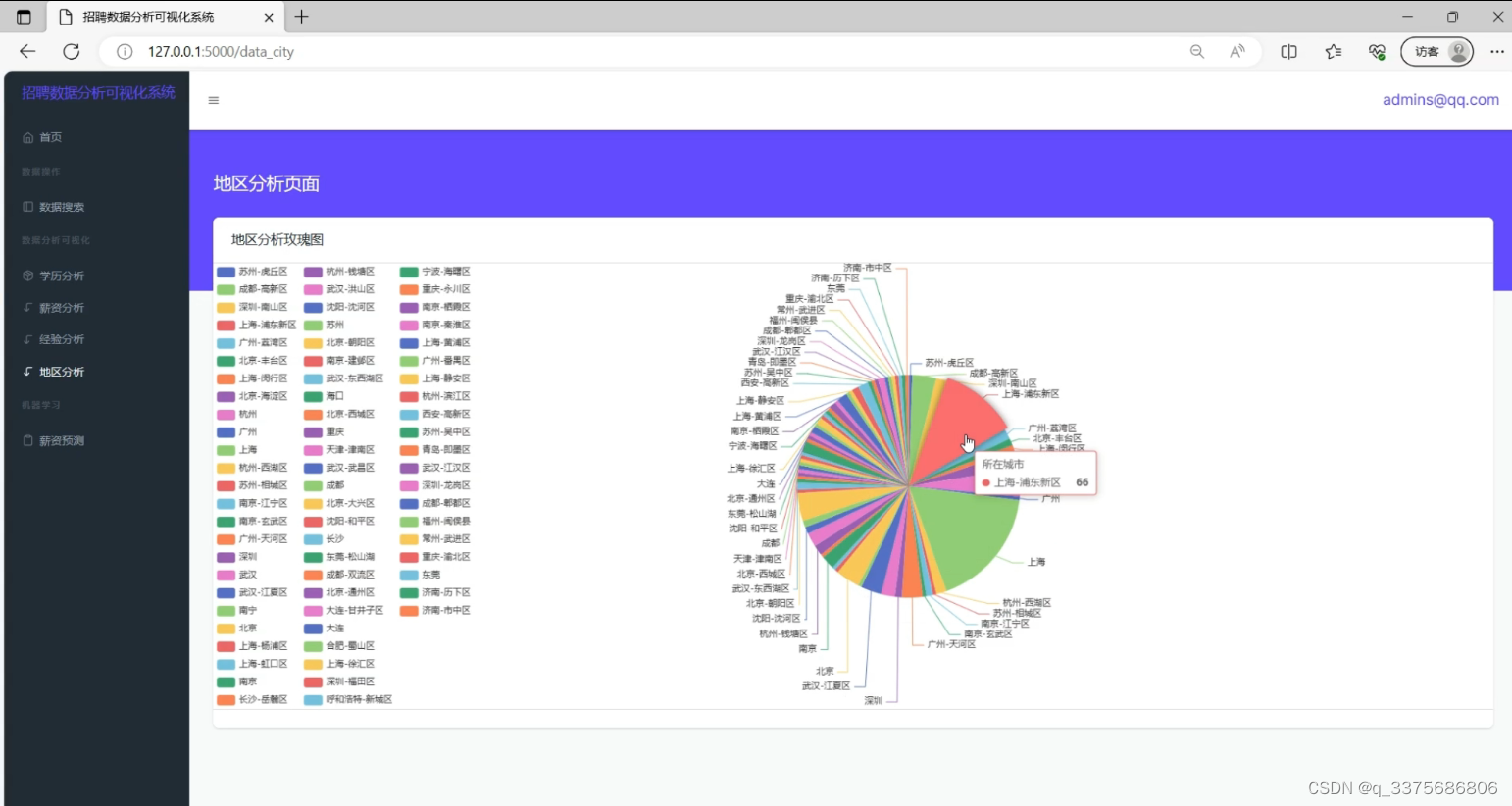
0、地区分析
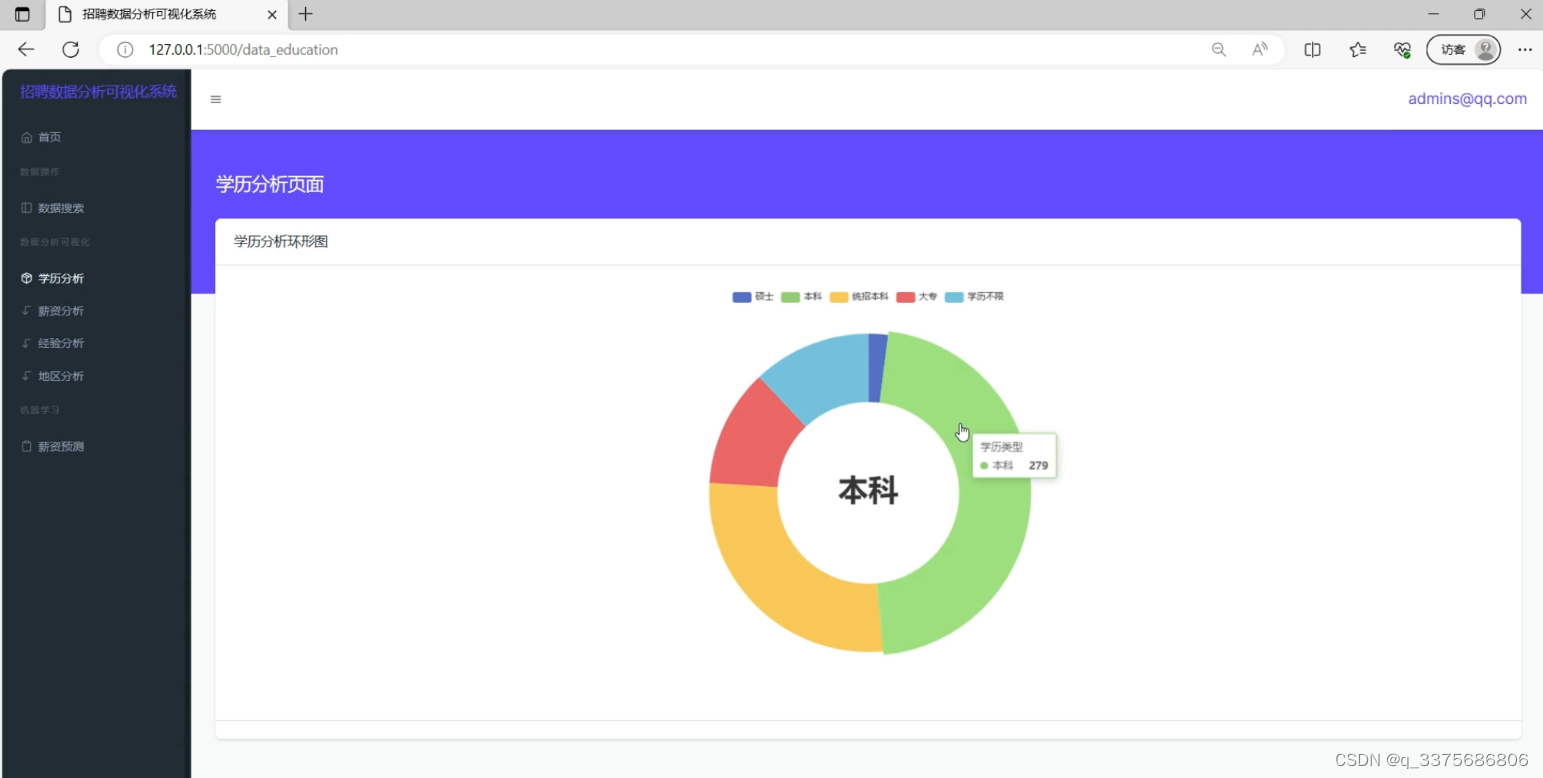
1、学历分析可视化
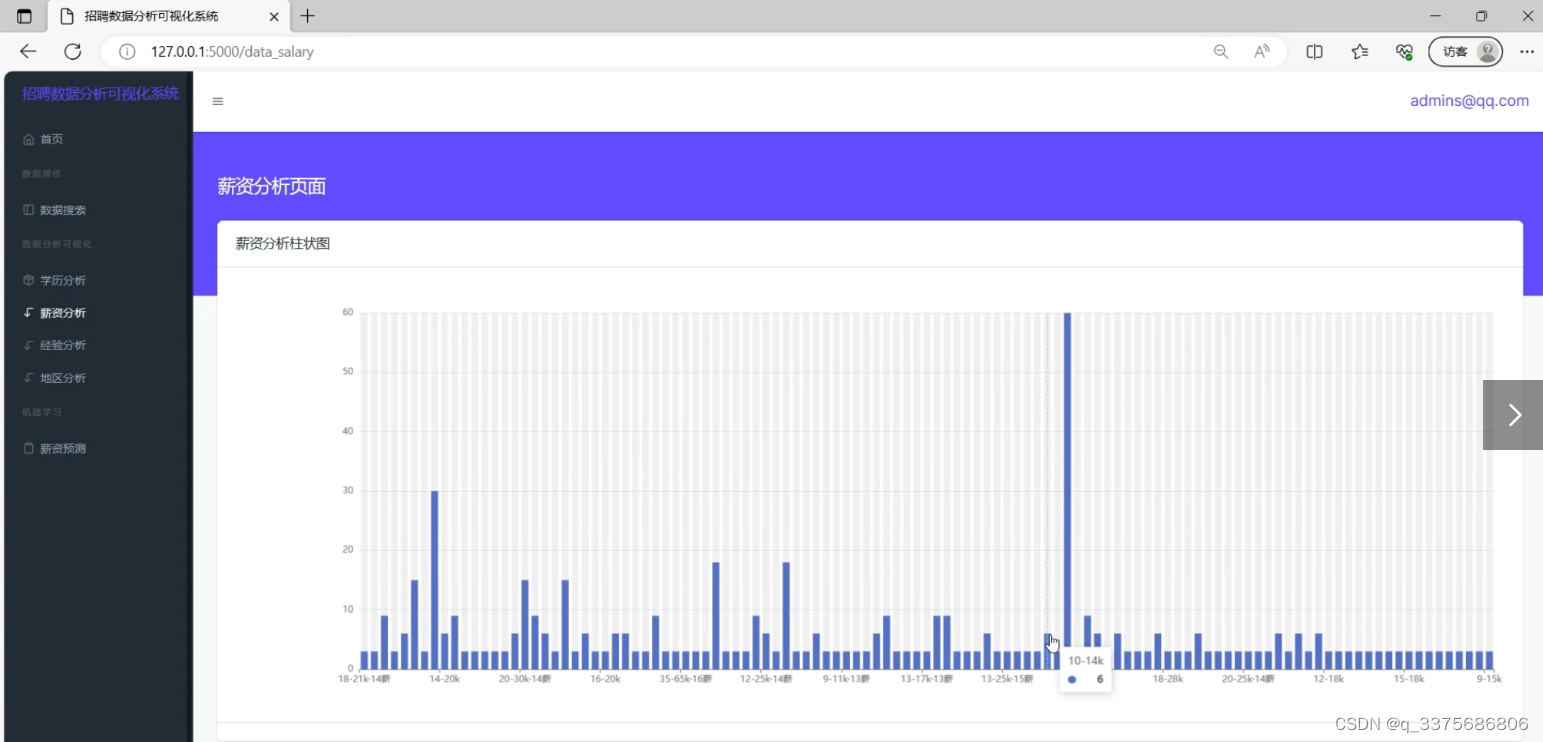
2、薪资 分析可视化
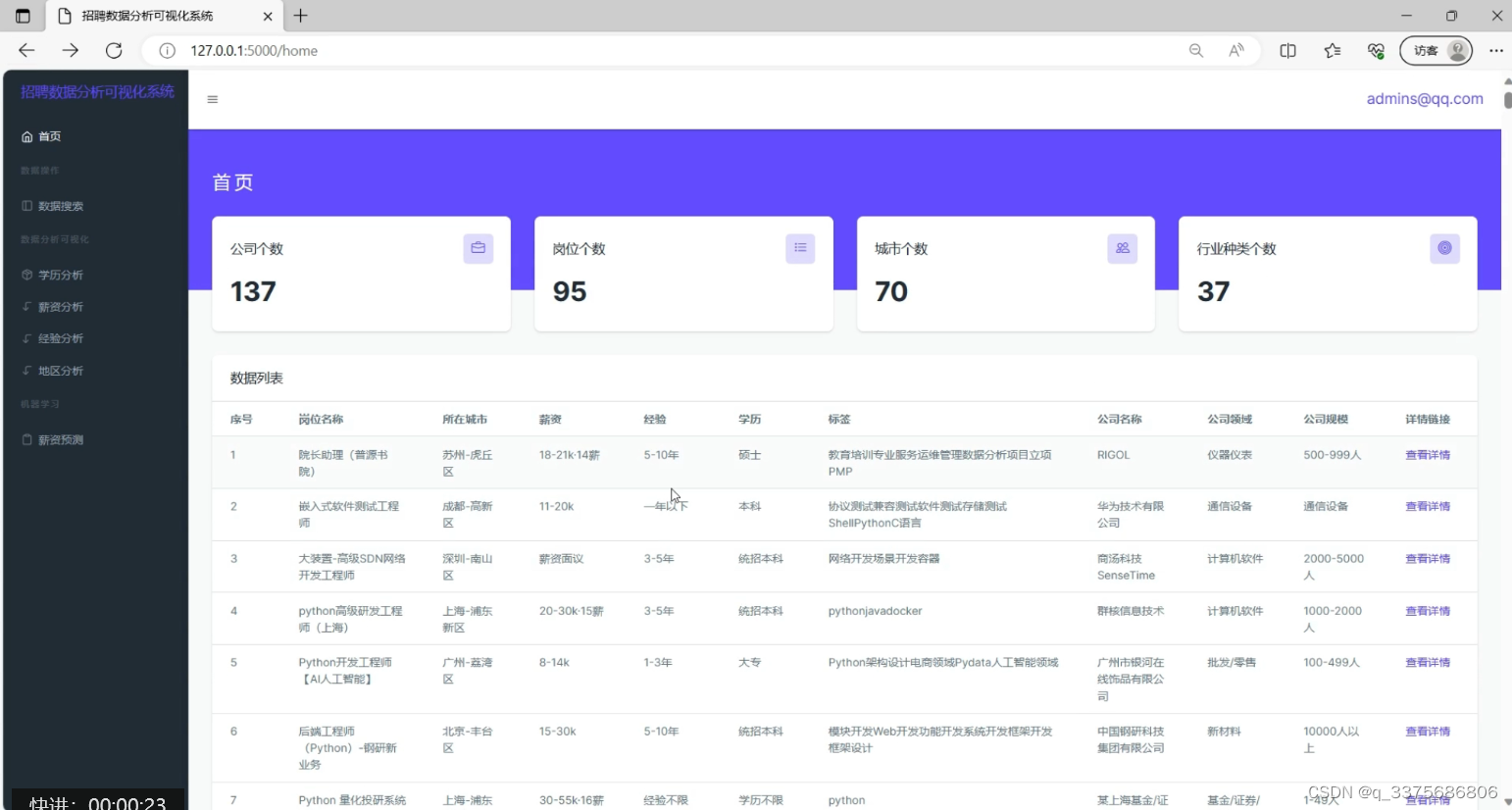
3、首页数据管理
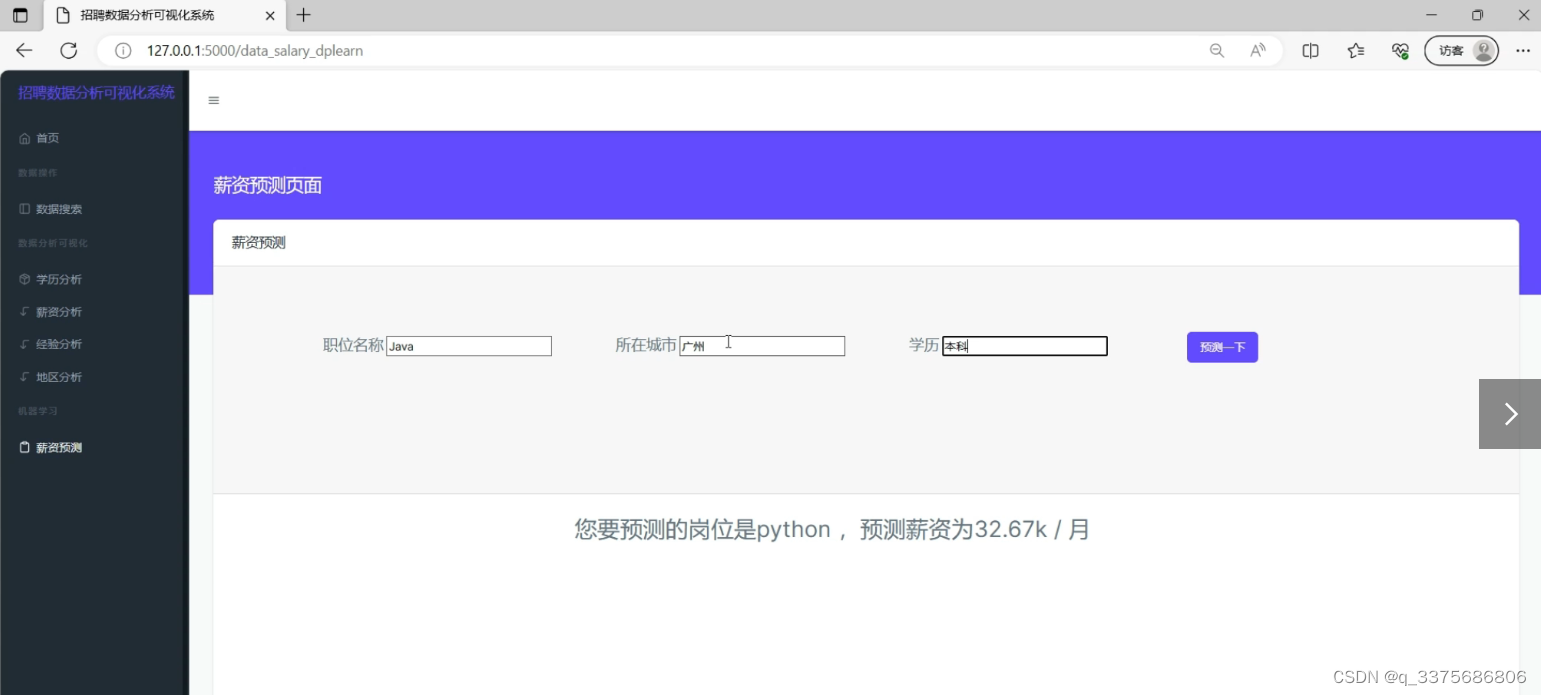
4、机器学习薪资预测
5、登录
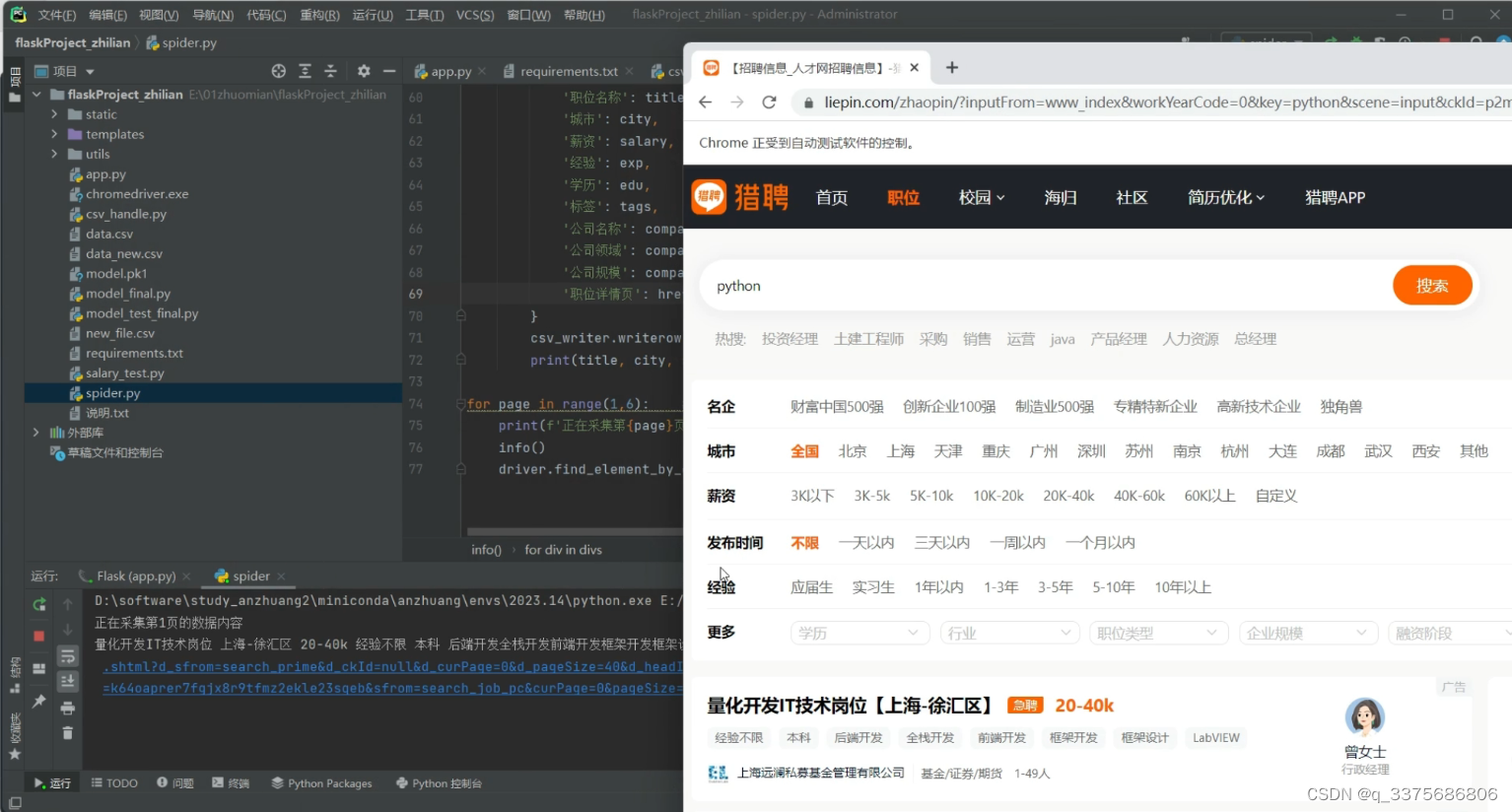
6、爬虫数据采集
3、项目说明
如今时代,人们获取信息的方式已经从传统媒体如电视、报纸、书籍、信件等转变为以互联网为主要来源,这促进了信息的快速更新和获取,与此同时,计算机的存储能力和复杂算法的飞速发展,导致数据量在近年是指数级增长,导致各行各业的决策越来越依赖于数据,从“业务驱动”向“数据驱动”转变。因此,我们需要充分利用大数据的海量处理和智能分析能力,准确抓取时代的热点数据,并在此基础上构建高效率的分析系统。
本论文旨在通过使用Python的requests库爬取拉勾网的招聘数据,并对数据进行清洗和持久化保存,以研究市场上招聘信息的趋势和分布情况。使用Flask框架作为后端技术,将数据库中的数据呈现给前端展示,借助基于前端框架Layui的应用,并结合图表展示工具ECharts,将数据以饼图、条形图等形式进行可视化展示。主要展示了招聘信息的数量分布、薪资分布情况以及关键词的分布情况。通过数据分析和可视化展示,得出如下结论:不同城市和行业的招聘信息数量和薪资水平有明显差异,而不同的招聘职位则有不同的职能和技能要求。因此,这些数据和分析结果对于个人求职者和企业招聘者提供了有益的参考。
4、部分代码
from flask import Flask, render_template, request, redirect, session
from utils import query
from utils.getDataHandle import getCityHandle, getIndustry
from utils.getIndexNum import indexNum
from utils.getTotalJob import *
from utils.getEducation import getEducationNum
from utils.getSalaryNum import getSalaryNum
from utils.getExp import getExpNum
from utils.getCity import getCityNum
import pandas as pd
import model_final
import model_test_final
app = Flask(__name__)
app.secret_key = 'this is session_key!'
app.config['SESSION_COOKIE_NAME'] = "session_key"
@app.route('/home', methods=['GET', 'POST'])
def home():
email = session.get('email')
total_job = getTotalJob()
companyNum, jobNum, cityNum, industryNum = indexNum()
# print(total_job)
return render_template('index.html', email=email, total_job=total_job, companyNum=companyNum, jobNum=jobNum,
cityNum=cityNum, industryNum=industryNum)
@app.route('/data_education', methods=['GET', 'POST'])
def data_education():
email = session.get('email')
education = getEducationNum()
return render_template('data_education.html', email=email, education=education)
@app.route('/data_city', methods=['GET', 'POST'])
def data_city():
email = session.get('email')
city = getCityNum()
return render_template('data_city.html', email=email, city=city)
@app.route('/data_salary', methods=['GET', 'POST'])
def data_salary():
email = session.get('email')
row, column = getSalaryNum()
return render_template('data_salary.html', email=email, row=row, column=column)
@app.route('/data_experience', methods=['GET', 'POST'])
def data_experience():
email = session.get('email')
row, column = getExpNum()
return render_template('data_experience.html', email=email, row=row, column=column)
@app.route('/data_salary_dplearn', methods=['GET', 'POST'])
def data_salary_dplearn():
email = session.get('email')
salary = 0
if request.method == "GET":
return render_template('data_salary_dplearn.html', email=email, salary=salary)
else:
input_data=dict(request.form)
job_title=input_data['job_title']
input_data_new = {key: [value] for key, value in input_data.items()}
print(input_data_new) # {'job_title': ['python开发工程师'], 'city': ['北京'], 'pre': ['本科']}
input_df = pd.DataFrame(input_data_new)
input_encoded = pd.get_dummies(input_df, columns=['job_title', 'city','education'])
input_encoded = input_encoded.reindex(columns=model_final.X_encoded.columns, fill_value=0)
salary = model_test_final.predict_salary(input_encoded)
return render_template('data_salary_dplearn.html',salary=salary,job_title=job_title)
@app.route('/data_search', methods=['GET', 'POST'])
def data_search():
email = session.get('email')
data_info = dict(request.form)
total_job = getTotalJob()
if request.method == 'GET':
return render_template('data_search.html', email=email, total_job=total_job)
else:
if data_info.get('city') != '':
city_data = data_info['city']
total_job = getCityHandle(city_data)
return render_template('data_search.html', email=email, total_job=total_job)
elif data_info.get('company_type') != '':
industry_data = data_info['company_type']
total_job = getIndustry(industry_data)
return render_template('data_search.html', email=email, total_job=total_job)
@app.route('/register', methods=['GET', 'POST'])
def register():
if request.method == 'GET':
return render_template('register.html')
elif request.method == 'POST':
request.form = dict(request.form)
if request.form['password'] != request.form['checkpassword']:
return render_template('error.html', message='两次密码不一致!请重新注册')
# return '两次密码不一致'
def filter_fn(item):
return request.form['email'] in item # 检测email是否已存在
users = query.querys('select * from data_user', [], 'select')
filter_list = list(filter(filter_fn, users)) # filter()过滤函数序列 第一个参数是函数 第二个是序列
if len(filter_list): # 如果长度不为0,说明在数据库里找到了,说明已存在
return render_template('error.html', message='该用户已被注册')
else:
query.querys('insert into data_user(email,password,address) values (%s,%s,%s)',
[request.form['email'], request.form['password'], request.form['address']], 'no_select')
return redirect('/login')
@app.route('/', methods=['GET', 'POST'])
def login():
if request.method == 'GET':
return render_template('login.html')
elif request.method == 'POST':
request.form = dict(request.form)
# 过滤函数
def filter_fn(item):
return request.form['email'] in item and request.form['password'] in item
users = query.querys('select * from data_user', [], 'select')
filter_user = list(filter(filter_fn, users))
if len(filter_user): # 检测库中是否有账户
session['email'] = request.form['email']
return redirect('/home')
else:
return render_template('error.html', message='用户邮箱或密码错误')
@app.route('/loginOut')
def loginOut():
session.clear()
return redirect('/login')
if __name__ == '__main__':
app.run(debug=True)
源码获取:
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的头像和用户名就可以找到我啦🍅
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻















 694
694











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









