










毕业设计:2023-2024年计算机专业毕业设计选题汇总(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕设选题推荐汇总
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、项目介绍
后端:Python语言、Django框架、Echarts可视化、MySQL数据库
前端:vue前端框架 html css js juery bootstrap
该图书管理推荐系统使用Python语言作为后端开发语言,使用Django框架进行后端开发。后端主要负责处理用户请求、与数据库交互以及数据处理等工作。
数据库采用MySQL,用于存储系统中的图书信息、用户信息以及推荐结果等数据。
前端使用Vue前端框架进行开发,使用HTML、CSS、JavaScript、jQuery和Bootstrap等技术进行页面设计和交互。前端负责用户界面的展示和用户与系统的交互。
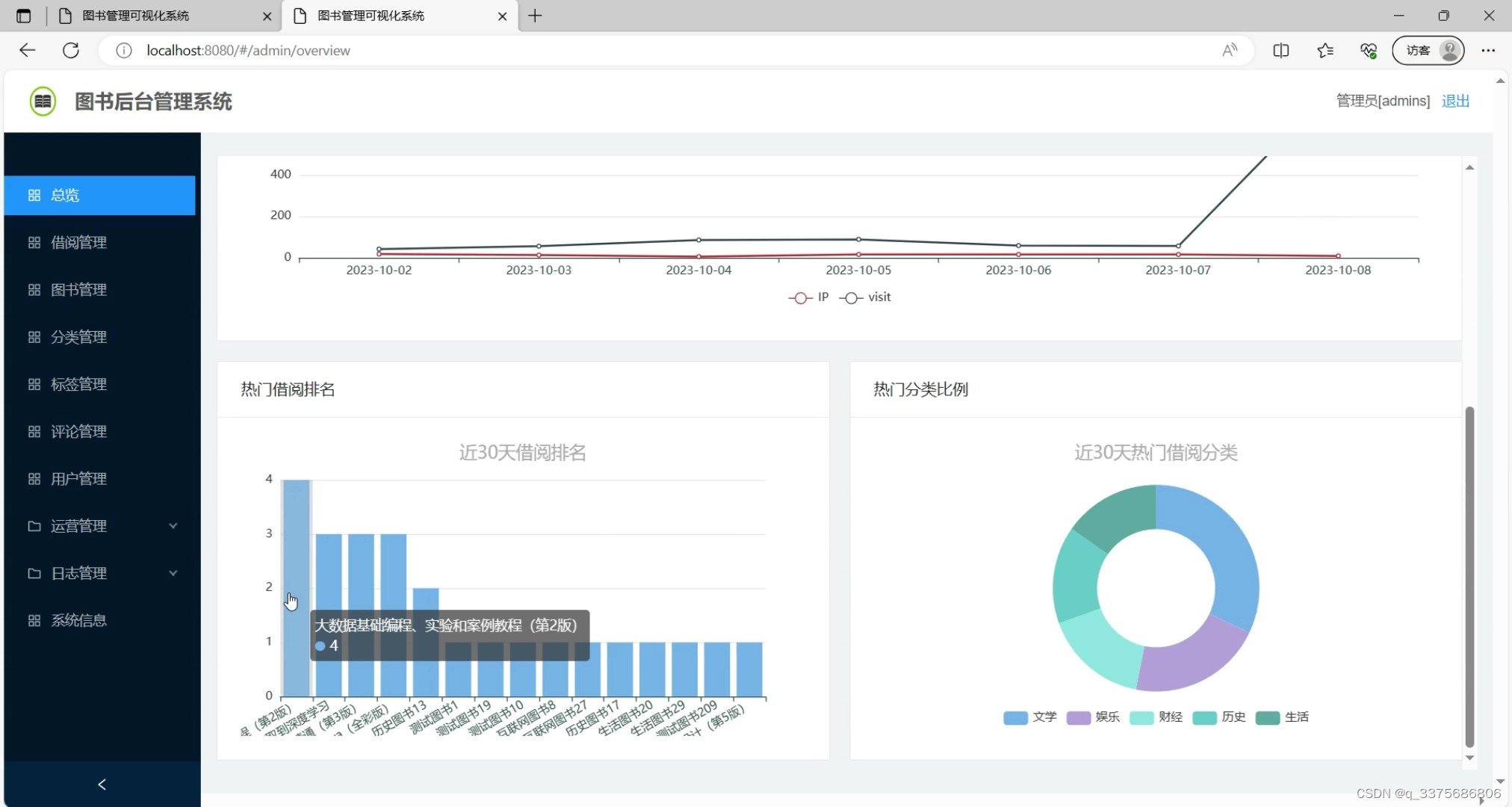
系统还使用Echarts可视化库进行数据可视化,可以将图书的统计信息以图表的形式展示给用户,让用户更直观地了解图书的相关情况。
2、项目界面
(1)图书数据可视化
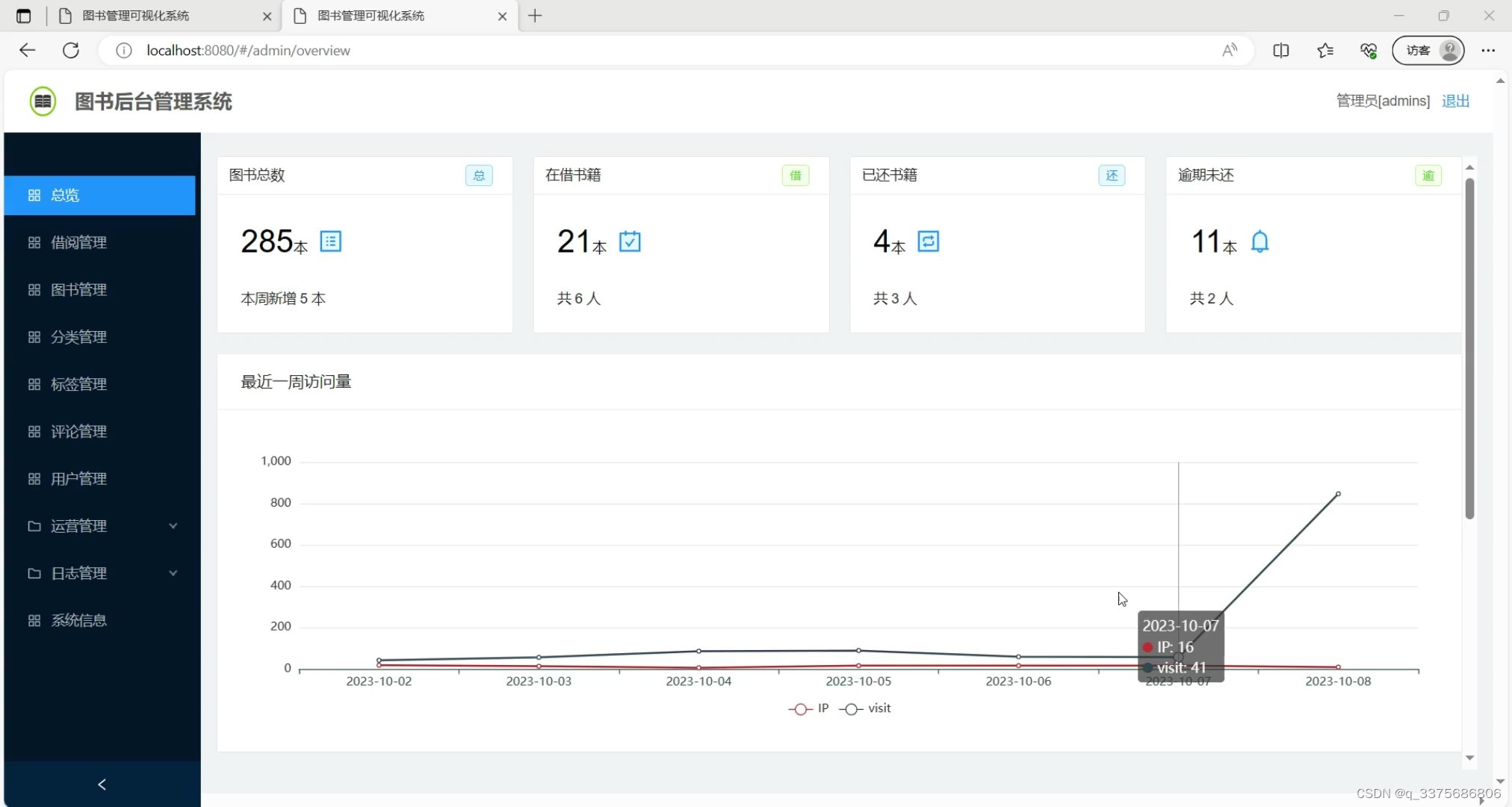
(2)图书数据概况
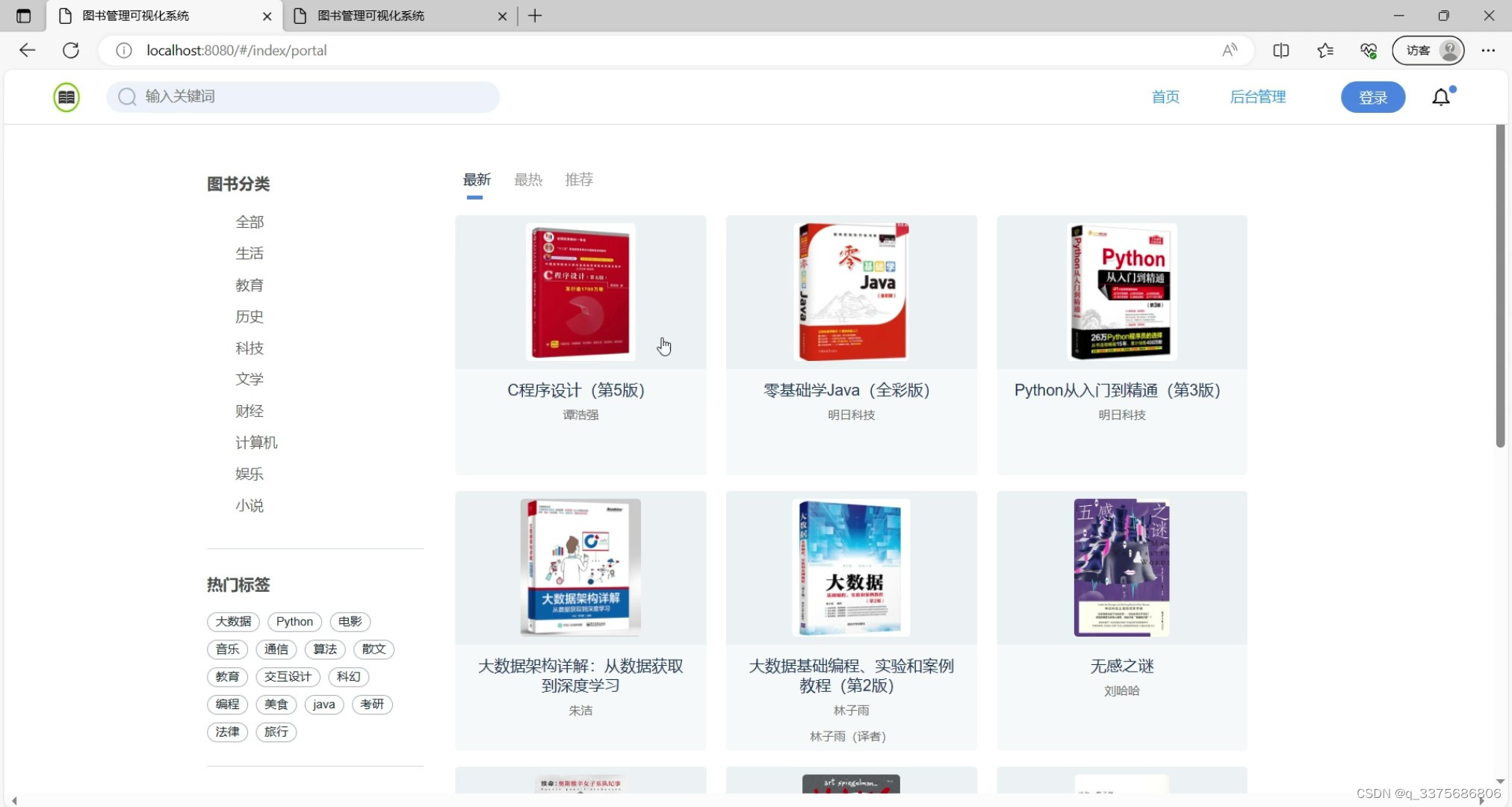
(3)图书数据分类
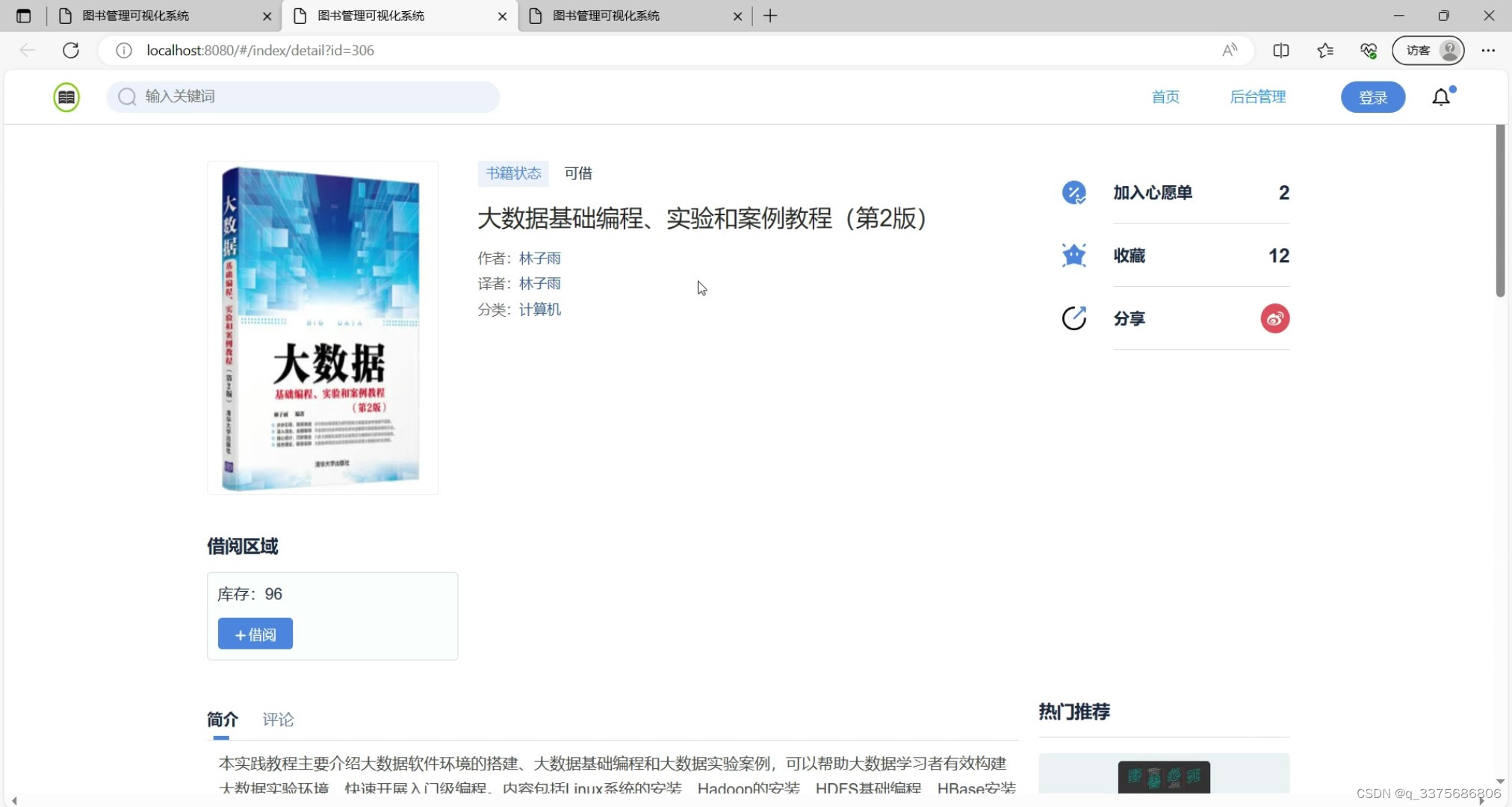
(4)图书详情
(5)图书借阅
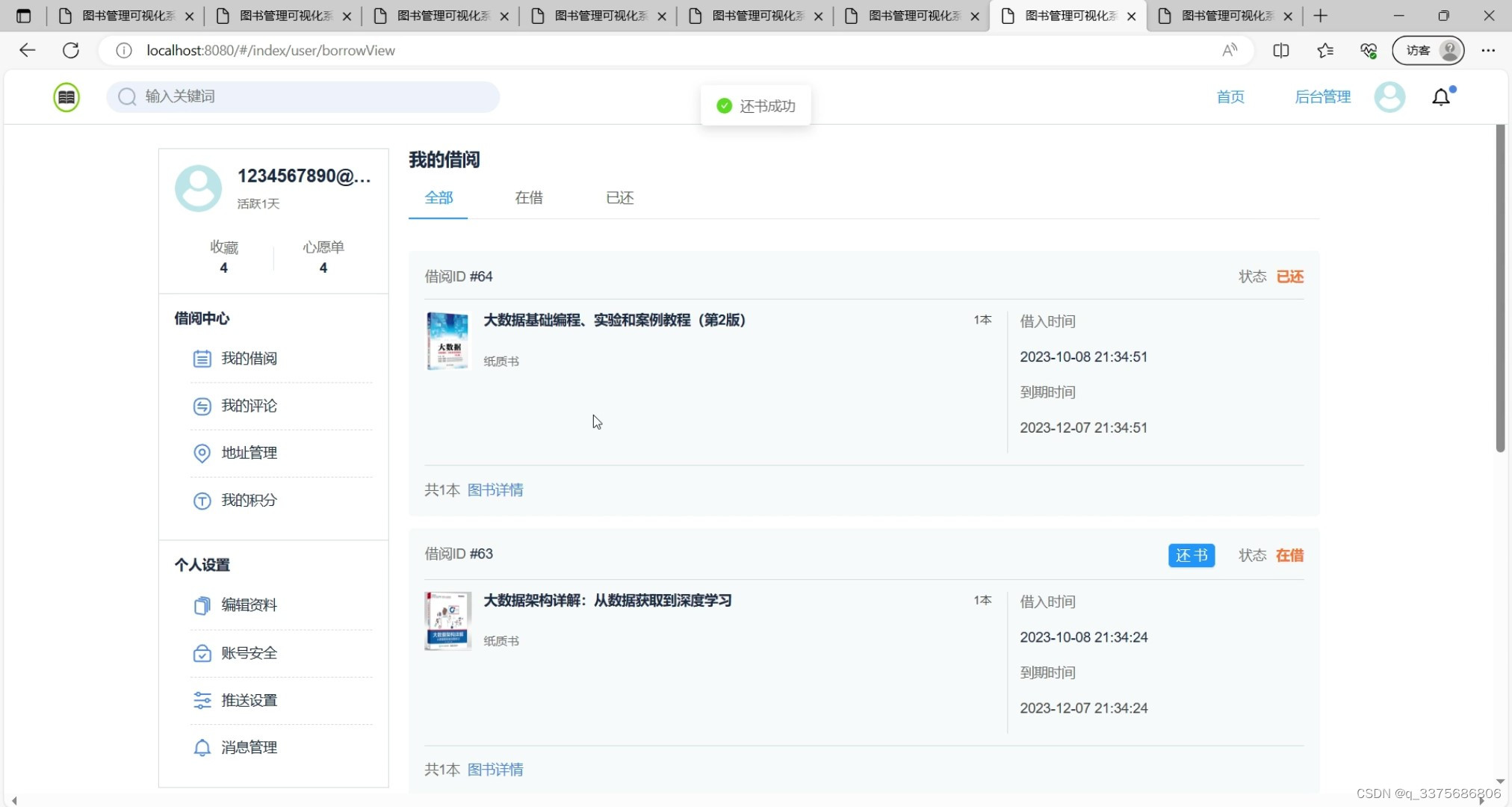
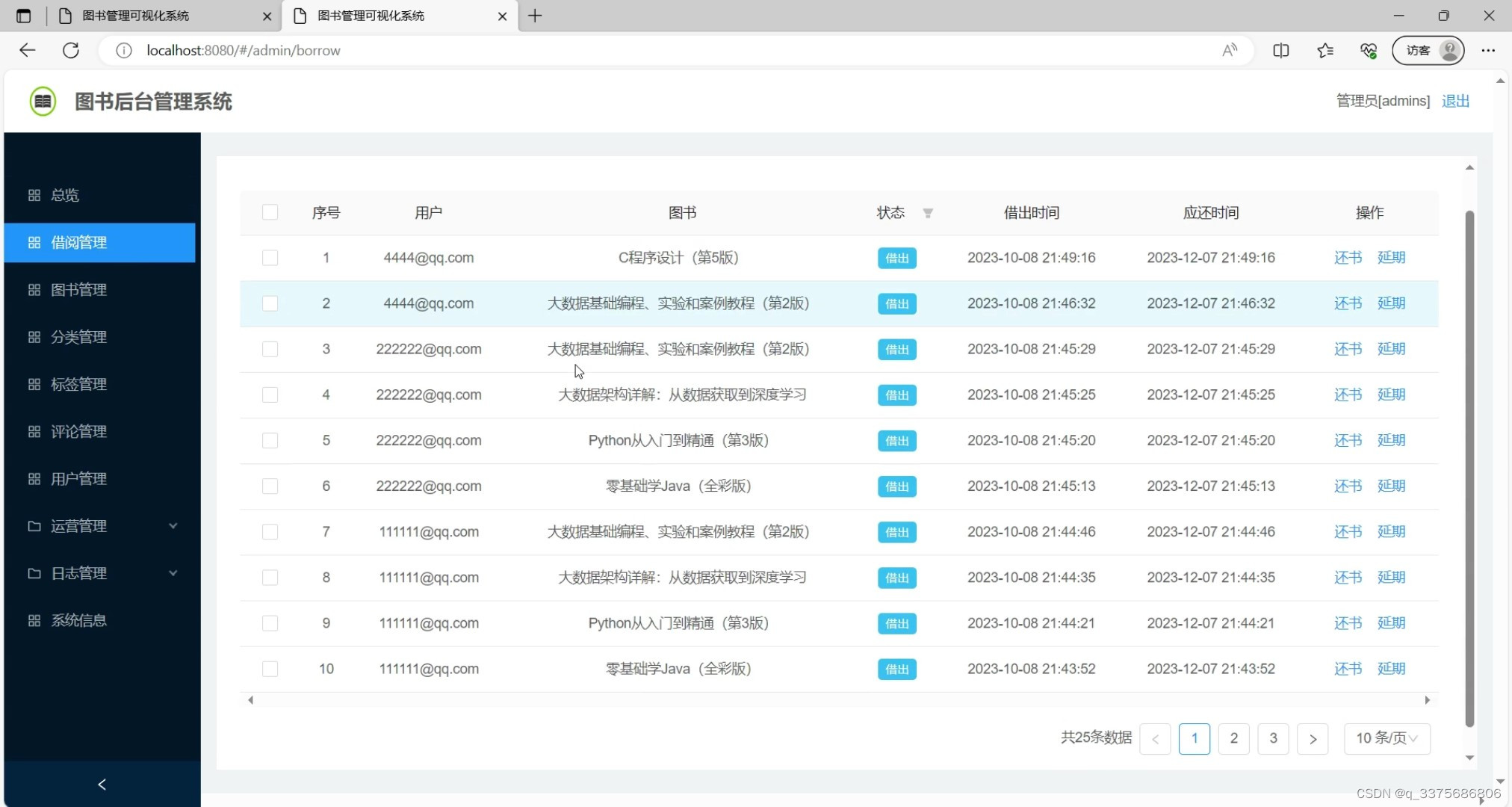
(6)借阅管理
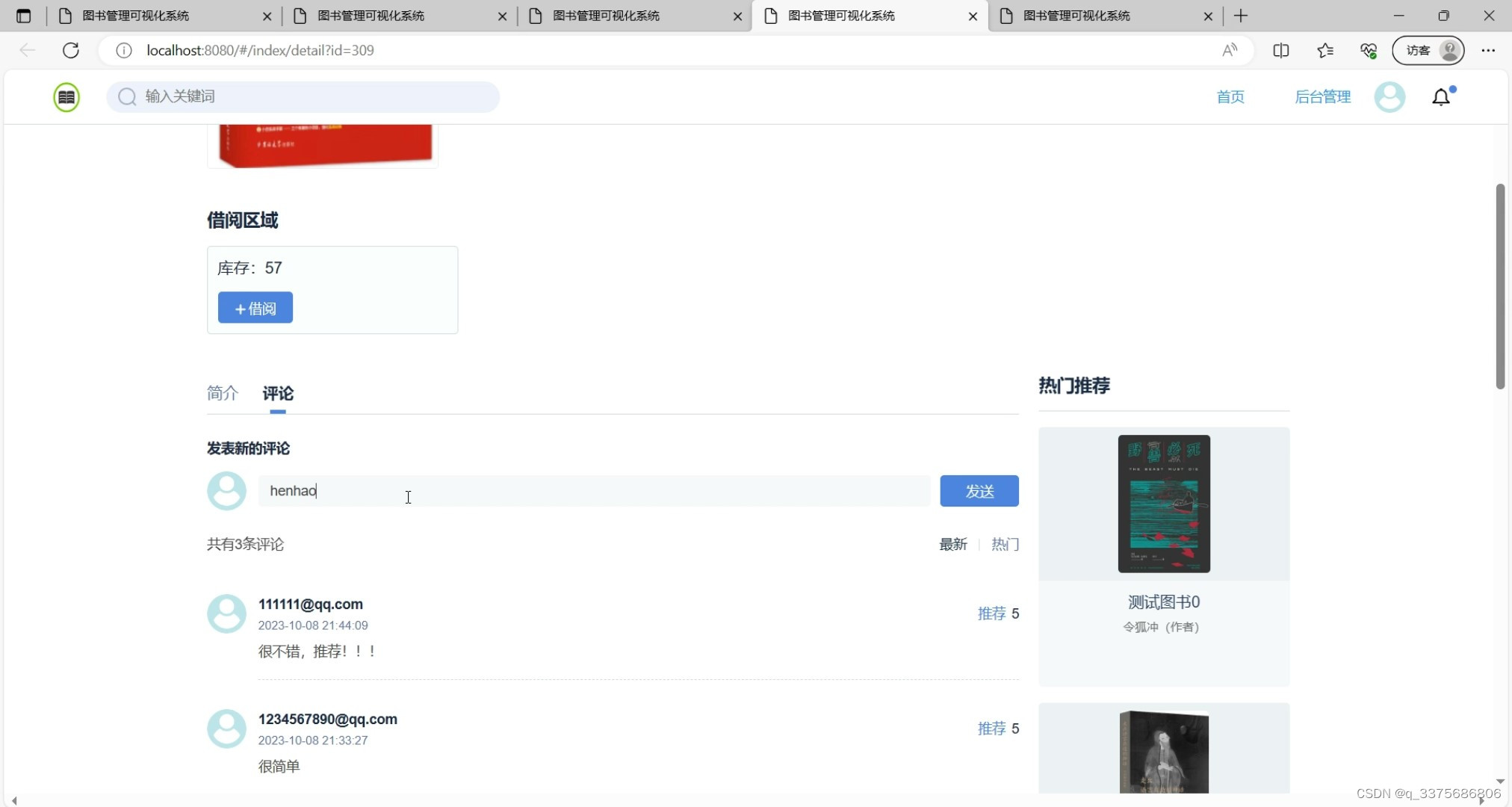
(7)热门推荐
3、项目说明
该图书管理推荐系统使用Python语言作为后端开发语言,使用Django框架进行后端开发。后端主要负责处理用户请求、与数据库交互以及数据处理等工作。
数据库采用MySQL,用于存储系统中的图书信息、用户信息以及推荐结果等数据。
前端使用Vue前端框架进行开发,使用HTML、CSS、JavaScript、jQuery和Bootstrap等技术进行页面设计和交互。前端负责用户界面的展示和用户与系统的交互。
系统还使用Echarts可视化库进行数据可视化,可以将图书的统计信息以图表的形式展示给用户,让用户更直观地了解图书的相关情况。
该图书管理推荐系统可以实现图书的管理、查询、借阅和归还等功能。同时,系统还具备推荐功能,根据用户的历史借阅记录和个人偏好,为用户推荐适合的图书。用户可以通过系统进行图书的搜索,并查看图书的详细信息、借阅状态和借阅历史等。系统还提供图书的预约和续借功能,方便用户进行操作。
总之,该图书管理推荐系统通过后端的Python开发和前端的Vue开发,实现了图书管理和推荐功能,提供了用户友好的界面和交互体验。
4、核心代码
# Create your views here.
from django.db import connection
from django.db.models import Q
from rest_framework.decorators import api_view, authentication_classes
from myapp.auth.authentication import AdminTokenAuthtication
from myapp.handler import APIResponse
from myapp.models import Classification
from myapp.permission.permission import isDemoAdminUser
from myapp.serializers import ClassificationSerializer
from myapp.utils import dict_fetchall
@api_view(['GET'])
def list_api(request):
if request.method == 'GET':
sql_str = 'SELECT x.id AS parentId, x.title AS parentTitle, y.id AS childId ,y.title AS childTitle FROM ' \
'b_classification AS x LEFT JOIN b_classification AS y ON y.pid = x.id WHERE x.pid = -1 order by ' \
'x.create_time desc '
data = []
with connection.cursor() as cursor:
cursor.execute(sql_str)
join_data = dict_fetchall(cursor)
# print(join_data)
for item1 in join_data:
found = False
for item2 in data:
if item2['key'] == item1['parentId']:
found = True
if item1['childId']:
item2['children'].append({
'key': item1['childId'],
'name': item1['childTitle'],
'isParent': False,
# 'children': []
})
break
if not found:
k = {
'key': item1['parentId'],
'name': item1['parentTitle'],
'isParent': True,
'children': []
}
if item1['childId']:
k['children'].append({
'key': item1['childId'],
'name': item1['childTitle'],
'isParent': False,
# 'children': []
})
data.append(k)
return APIResponse(code=0, msg='查询成功', data=data)
@api_view(['POST'])
@authentication_classes([AdminTokenAuthtication])
def create(request):
if isDemoAdminUser(request):
return APIResponse(code=1, msg='演示帐号无法操作')
classification = Classification.objects.filter(title=request.data['title'])
if len(classification) > 0:
return APIResponse(code=1, msg='该名称已存在')
serializer = ClassificationSerializer(data=request.data)
if serializer.is_valid():
serializer.save()
return APIResponse(code=0, msg='创建成功', data=serializer.data)
return APIResponse(code=1, msg='创建失败')
@api_view(['POST'])
@authentication_classes([AdminTokenAuthtication])
def update(request):
if isDemoAdminUser(request):
return APIResponse(code=1, msg='演示帐号无法操作')
try:
pk = request.GET.get('id', -1)
print(pk)
classification = Classification.objects.get(pk=pk)
except Classification.DoesNotExist:
return APIResponse(code=1, msg='对象不存在')
serializer = ClassificationSerializer(classification, data=request.data)
if serializer.is_valid():
serializer.save()
return APIResponse(code=0, msg='更新成功', data=serializer.data)
return APIResponse(code=1, msg='更新失败')
@api_view(['POST'])
@authentication_classes([AdminTokenAuthtication])
def delete(request):
if isDemoAdminUser(request):
return APIResponse(code=1, msg='演示帐号无法操作')
try:
ids = request.GET.get('ids')
ids_arr = ids.split(',')
# 删除自身和自身的子孩子
Classification.objects.filter(Q(id__in=ids_arr) | Q(pid__in=ids_arr)).delete()
except Classification.DoesNotExist:
return APIResponse(code=1, msg='对象不存在')
return APIResponse(code=0, msg='删除成功')
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻















 1908
1908











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









