










博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2025年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2025年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
技术栈:
Python语言、Django框架、Echarts可视化、HTML、Prophet时间序列算法模型
空气质量分析+爬虫+Prophet预测系统-时间序列+文档
2、项目界面
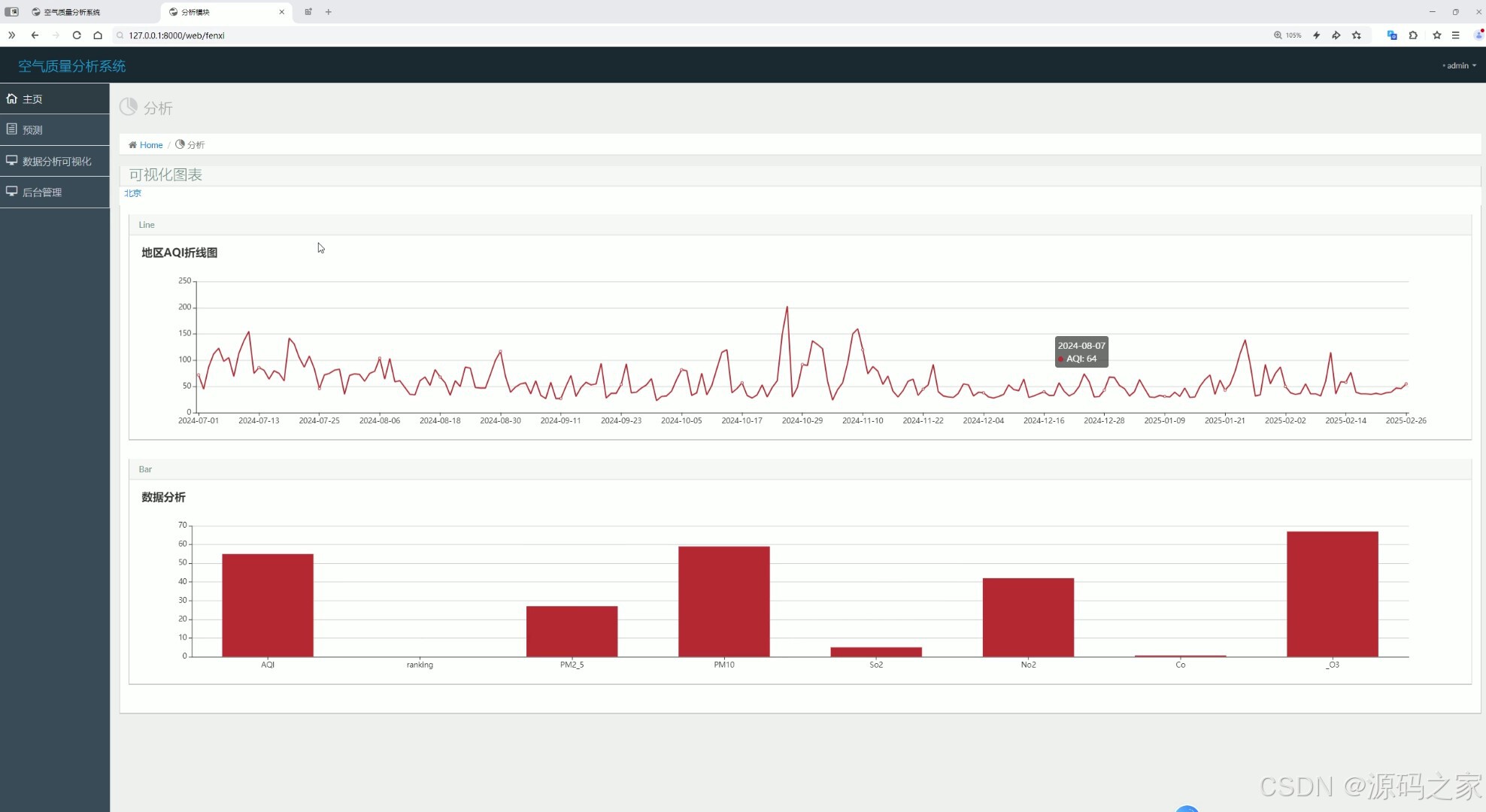
(1)数据分析可视化
(2)数据中心
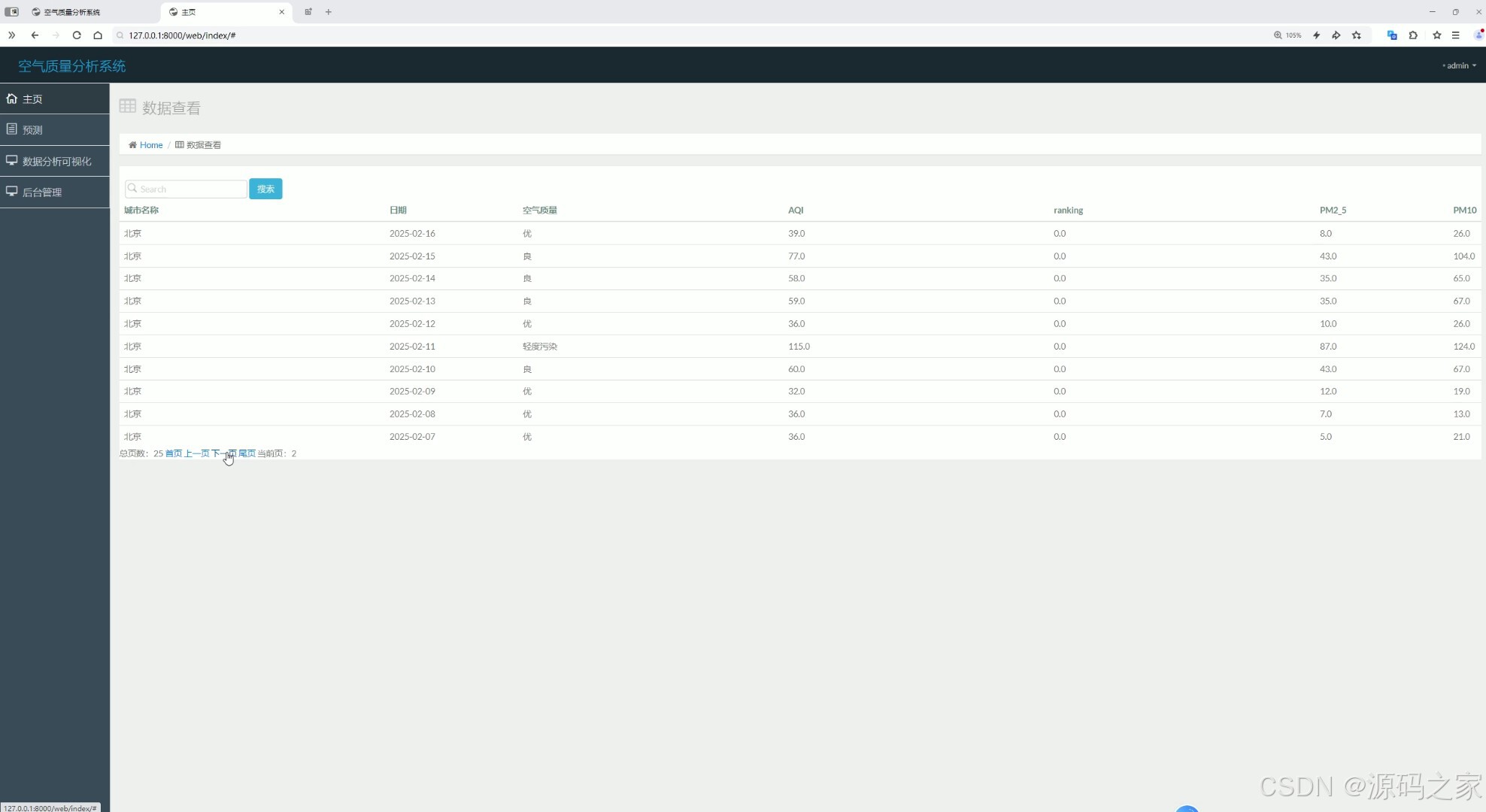
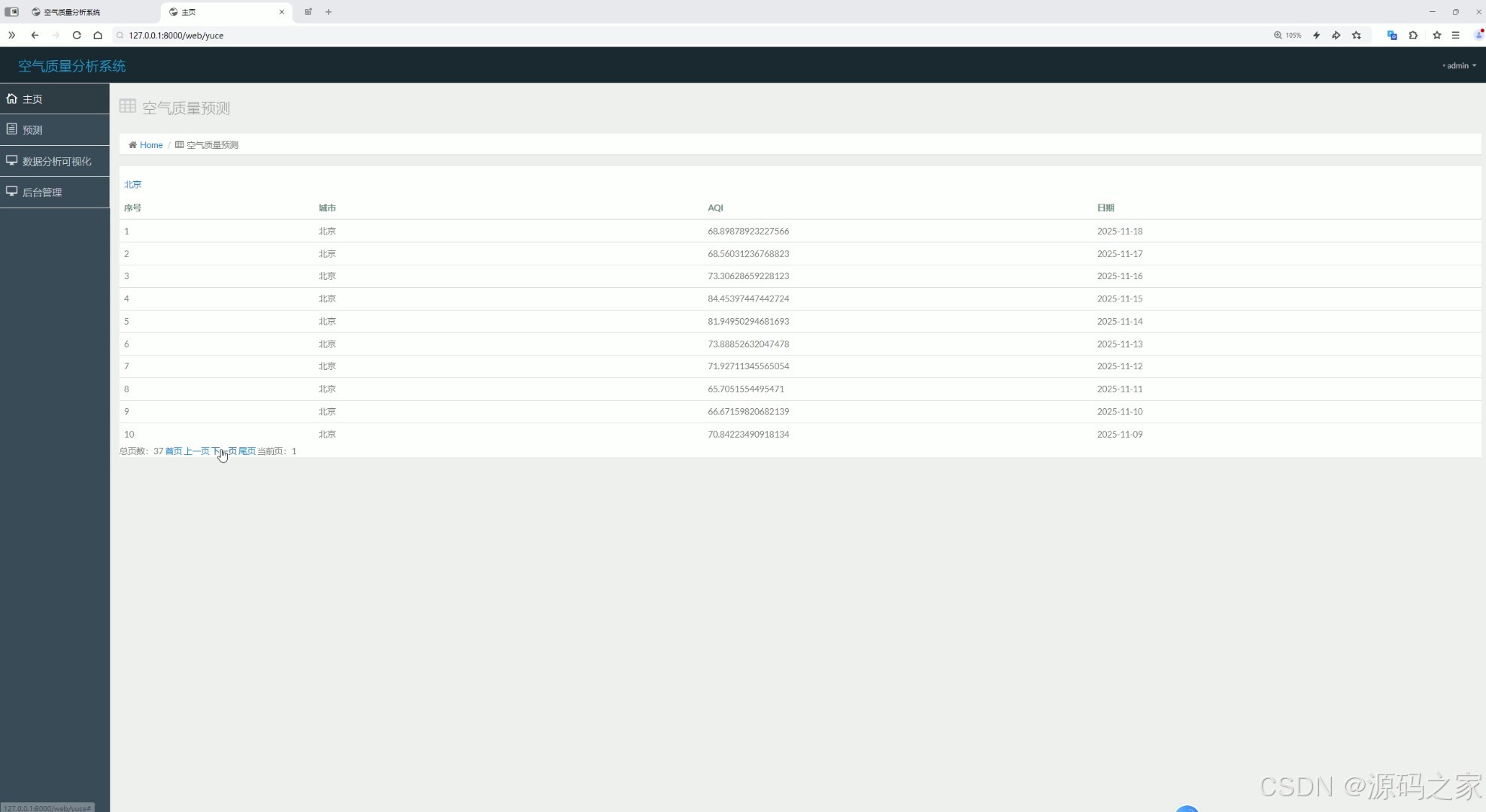
(3)空气质量预测
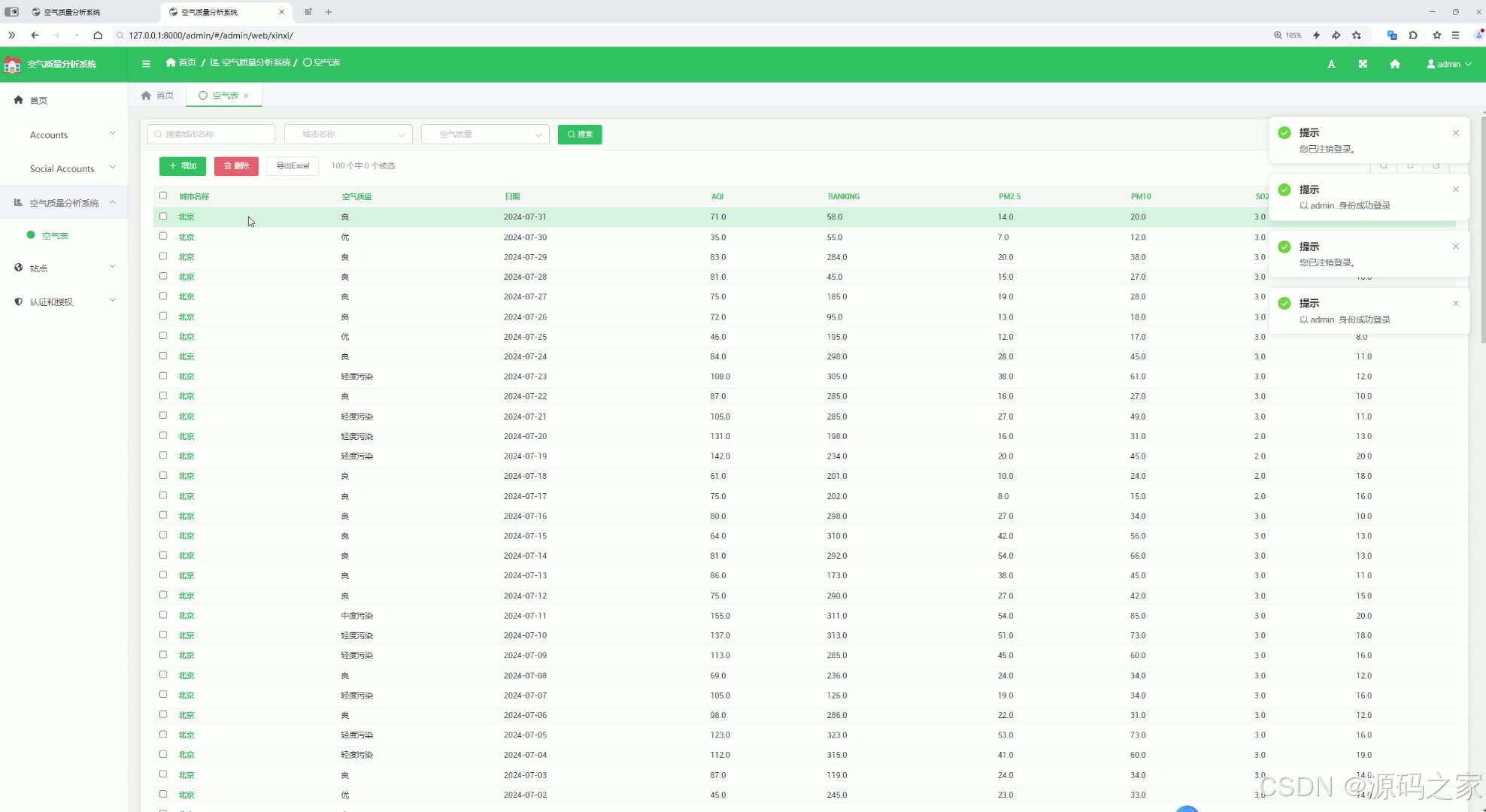
(4)后台管理
(5)注册登录
(6)数据采集
3、项目说明
1. 数据分析可视化
数据分析可视化模块是系统的核心功能之一,通过ECharts可视化技术,将空气质量数据以直观的图表形式呈现出来。
功能
- 空气质量指标展示:展示不同时间段(如小时、日、月)的空气质量指标(如PM2.5、PM10、SO₂、NO₂、O₃等)的变化趋势。
- 区域对比分析:通过地图或柱状图展示不同城市或区域的空气质量对比。
- 数据趋势分析:通过折线图或柱状图展示空气质量指标的长期变化趋势,帮助用户了解空气质量的改善或恶化情况。
- 实时数据展示:展示当前时刻的空气质量数据,方便用户实时了解空气质量状况。
实现方式
- 后端数据处理:使用Django框架从数据库中提取空气质量数据,并进行必要的数据处理。
- 前端可视化:使用ECharts结合HTML构建可视化界面,展示各种图表。
2. 数据中心
数据中心是数据存储和管理的核心模块,用户可以在这里查看、筛选、导出空气质量相关的数据。
功能
- 数据查询:提供数据的查询、筛选功能,用户可以根据日期、城市、指标等条件查询空气质量数据。
- 数据导出:支持将查询结果导出为CSV、Excel等格式,方便用户进行进一步分析。
- 数据统计:提供简单的统计功能,如平均值、最大值、最小值等。
实现方式
- 后端实现:通过Django框架连接数据库,提供数据查询和导出接口。
- 前端实现:使用HTML构建用户界面,展示数据查询结果。
3. 空气质量预测
空气质量预测模块结合Prophet时间序列算法模型,对未来的空气质量进行预测。
功能
- 预测功能:用户可以选择城市和时间范围,系统利用Prophet模型预测未来的空气质量指标。
- 预测结果展示:通过折线图或柱状图展示预测结果,并与历史数据进行对比。
- 预警功能:根据预测结果,系统可以提供空气质量预警,提醒用户注意污染天气。
实现方式
- 数据处理:从数据库中提取历史空气质量数据,作为Prophet模型的输入。
- 模型训练与预测:使用Python的Prophet库训练时间序列模型,并进行预测。
- 前端交互:通过Django和HTML实现用户界面,展示预测结果和预警信息。
4. 后台管理
后台管理模块是系统管理员使用的功能,用于管理空气质量数据和其他系统数据。
功能
- 数据管理:添加、删除、修改空气质量监测数据。
- 用户管理:管理用户账号、权限分配、用户行为日志等。
- 系统配置:配置系统参数,如数据更新频率、预警阈值等。
实现方式
- 后端实现:通过Django Admin或自定义的后台管理界面,管理员可以对数据库中的数据进行操作。
- 前端实现:使用HTML构建后台管理界面。
5. 注册登录
注册登录模块是用户进入系统的入口,用户可以通过注册账号并登录来使用系统提供的各种功能模块。
功能
- 用户注册:用户可以创建账号,设置用户名和密码。
- 用户登录:用户可以通过用户名和密码登录系统。
- 密码找回:提供密码找回功能,确保用户可以恢复账号。
实现方式
- 后端实现:使用Django框架的用户认证系统。
- 前端实现:使用HTML构建用户界面。
6. 数据采集
数据采集模块是系统获取空气质量数据的入口,通过爬虫技术从外部数据源获取数据。
功能
- 数据爬取:定期从指定的空气质量监测网站或API爬取数据。
- 数据存储:将爬取的数据存储到MySQL数据库中。
- 数据更新:定期更新数据库中的数据,确保数据的时效性。
实现方式
- 爬虫实现:使用Python的爬虫框架(如Scrapy、Requests)从外部数据源获取数据。
- 数据存储:将爬取的数据存储到MySQL数据库中。
- 任务调度:使用定时任务(如Celery)定期运行爬虫,更新数据。
4、核心代码
from django.shortcuts import render, get_object_or_404, reverse, redirect
from django.http import HttpResponse, HttpResponseRedirect
from django.contrib.auth.decorators import login_required
# Create your views here.
from . import models
from prophet import Prophet
import pandas as pd
import datetime
@login_required
def index(request):
if request.method == 'GET':
# 默认查询所有数据,并按日期从大到小排序
results = models.XinXi.objects.all().order_by('-datetiems') # 降序排序
# 获取搜索关键词
Search = request.GET.get('Search', '')
if Search:
# 如果有搜索关键词,按城市名称模糊搜索,并保持日期降序排序
results = models.XinXi.objects.filter(city__icontains=Search).order_by('-datetiems')
return render(request, 'fenxi/table.html', locals())
@login_required
def fenxi(request):
if request.method == 'GET':
citys = list(set([i.city for i in models.XinXi.objects.all()]))
citys.sort()
city = request.GET.get('city')
if not city:
city = '北京'
# 按日期从小到大排序
datas1 = models.XinXi.objects.filter(city=city).order_by('datetiems')
# 质量折线图
count_AQI = []
count_name = []
for resu in datas1:
count_name.append(resu.datetiems)
count_AQI.append(resu.AQI)
# 各地区最新AQI
datas2 = datas1.order_by('-datetiems')[:1] # 获取最新的记录
zuijia_name = []
zuijia_shuju = []
for resu in datas2:
zuijia_name.append('AQI')
zuijia_shuju.append(resu.AQI)
zuijia_name.append('ranking')
zuijia_shuju.append(resu.ranking)
zuijia_name.append('PM2_5')
zuijia_shuju.append(resu.PM2_5)
zuijia_name.append('PM10')
zuijia_shuju.append(resu.PM10)
zuijia_name.append('So2')
zuijia_shuju.append(resu.So2)
zuijia_name.append('No2')
zuijia_shuju.append(resu.No2)
zuijia_name.append('Co')
zuijia_shuju.append(resu.Co)
zuijia_name.append('_O3')
zuijia_shuju.append(resu._O3)
return render(request, 'fenxi/fenxi.html', locals())
@login_required
def yuce(request):
if request.method == 'GET':
citys = list(set([i.city for i in models.XinXi.objects.all()]))
citys.sort()
city = request.GET.get('city')
if not city:
city = '北京'
shujus = models.XinXi.objects.filter(city=city)
dicts = {
'ds': [],
'y': [],
'cap': [],
'floor': []
}
for resu in shujus:
a = datetime.datetime.strptime(resu.datetiems, '%Y-%m-%d')
# a = datetime.datetime.strptime(resu.datetiems, '%Y/%m/%d')
dicts['ds'].append(a.strftime('%Y-%m-%d'))
dicts['y'].append(resu.AQI),
dicts['cap'].append(500)
dicts['floor'].append(0)
print(dicts)
df = pd.DataFrame.from_dict(dicts)
# 拟合模型
m = Prophet(growth='logistic')
m.fit(df)
# 构建待预测日期数据框,periods = 365 代表除历史数据的日期外再往后推 365 天
future = m.make_future_dataframe(periods=265)
future['cap'] = 500
future['floor'] = 0
# 预测数据集
forecast = m.predict(future)
data = forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']]
dicts = data.to_dict(orient="list")
datas = []
for i in range(len(dicts['ds'])):
dicts1 = {}
dicts1['yhat'] = dicts['yhat'][i]
dicts1['yhat_lower'] = dicts['yhat_lower'][i]
dicts1['yhat_upper'] = dicts['yhat_upper'][i]
dicts1['ds'] = dicts['ds'][i].strftime("%Y-%m-%d")
datas.append(dicts1)
datas = datas[-365:][::-1]
print(datas)
return render(request, 'fenxi/yuce.html', locals())
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻

















 8559
8559

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









