







最近在学习pytorch的模型训练过程,注意到了module模块中train和eval两个函数。train函数用在模型训练之前,表示进入训练模式,如果模型中有BN层和Dropout层,则启动;eval用在模型测试和验证时,表示评估模式,不启动模型中的BN层和Dropout层。这两个函数还是比较好理解的,Dropout层我们也比较熟悉,但在NLP领域中BN(Batch Normalization)层不是很常见,通常我们使用layer nomalization,所以就学习了一下。
Batch Normalization
BN本质上来说是一个归一化层,归一化层在神经网络中应用广泛,为什么需要有归一化层呢?首先在训练前,每个batch的数据分布可能有很大差别,如果模型按照每个模型的真实数据分布进行学习和迭代,那么可能会大大降低收敛速度。而且训练数据和测试数据的分布也可能不同,所以数据在训练前经过归一化预处理可以提高模型的训练速度和泛化能力。其次在训练过程中,数据经过神经网络前几层可能会发现一些细微的变化,而这个变化经过后面多层的传播,可能会越来越发散,训练数据的分布一直在变化的话,模型的每一层都要重新学习和迭代,这样也会影响到模型训练速度,这个现象就叫漂移。
BN层的作用就是在神经网络中的每层之前插入归一化层,对输入的数据进行归一化处理,对每一个batch都进行操作。例如现在有一个batch的数据,包含了两个特征(身高、体重),共10条数据。那么BN会对这个batch的身高特征进行缩放,算出身高的均值和方差,然后对10个身高数据进行缩放,体重同理,相当于对batch的每列数据分别进行缩放。
但是由于BN层按列缩放特点,使其不适应NLP领域,在NLP中,每个batch的数据格式大致为:(batch_size,seq_len,dim),如果按列缩放,也就成了对每个句子里第一个字的数据进行缩放,或者对其他固定位置的数据进行缩放,这样不符合自然语言的规律,自然语言习惯了以一行句子作为一个单元,在这里Layer Normalization就体现出他的优势了。
Layer Normalization
LN与BN不同的是,BN按列进行缩放,而LN是按行进行缩放。比如在上面那个batch的数据中,BN会对所有身高数据进行缩放,而LN是对每行(身高,体重)数据进行缩放,这样由于数据量纲不同,LN的结果就完全错了,但是LN按行进行缩放非常适合NLP领域问题。在NLP的一个batch中,数据按(batch_size,seq_len,dim)进行排列,LN会对第三维进行缩放,也就是字向量或者词向量,在这一维度,各个字或词的量纲相同,缩放没有任何问题。如下图所示:
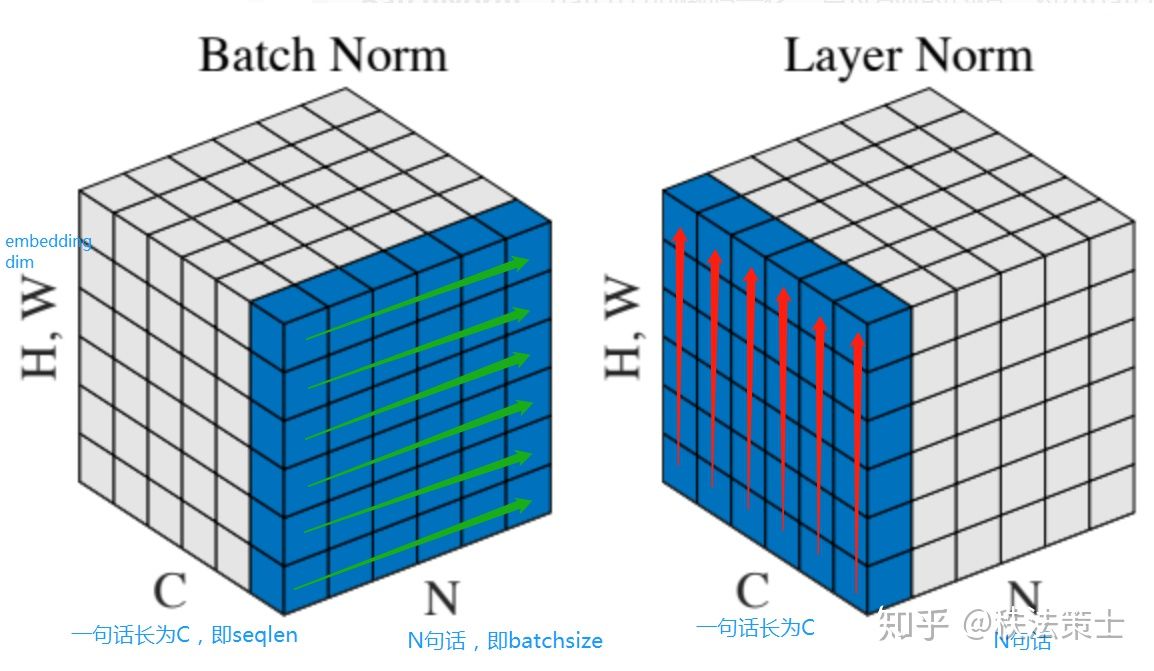
每个立方体就是一个batch的数据,高(H)是词向量的维度,C是每句话的长度,N是句子总数。
BN:选取每个句子的第一个位置的数据,每次取一条绿色箭头方向数据进行缩放。也就是将所有数据的第一个字进行缩放。
LN:选取一个句子每个位置的数据,每次取一条红色箭头方向的数据进行缩放,也就是将一个句子的所有位置的数据进行缩放。
更新:
最近重新看了一些BN和LN的知识,发现上面说的有些问题,BN用在NLP中并不是对每句话的第一个字进行归一化,而是对每句话的所有字向量上第一个维度的数做归一化。















 6989
6989











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









