







1. Layer Normalization
μ = E ( X ) ← 1 H ∑ i = 1 n x i σ ← Var ( x ) = 1 H ∑ i = 1 H ( x i − μ ) 2 + ϵ y = x − E ( x ) Var ( X ) + ϵ ⋅ γ + β \begin{gathered}\mu=E(X) \leftarrow \frac{1}{H} \sum_{i=1}^n x_i \\ \sigma \leftarrow \operatorname{Var}(x)=\sqrt{\frac{1}{H} \sum_{i=1}^H\left(x_i-\mu\right)^2+\epsilon} \\ y=\frac{x-E(x)}{\sqrt{\operatorname{Var}(X)+\epsilon}} \cdot \gamma+\beta\end{gathered} μ=E(X)←H1i=1∑nxiσ←Var(x)=H1i=1∑H(xi−μ)2+ϵy=Var(X)+ϵx−E(x)⋅γ+β
γ
\gamma
γ:可训练再缩放参数
β
\beta
β:可训练偏移
2. RMS Norm
R M S ( x ) = 1 H ∑ i = 1 H x i 2 x = x R M S ( x ) ⋅ γ \begin{array}{r}R M S(x)=\sqrt{\frac{1}{H} \sum_{i=1}^H x_i^2} \\ x=\frac{x}{R M S(x)} \cdot \gamma\end{array} RMS(x)=H1∑i=1Hxi2x=RMS(x)x⋅γ
RMS Norm 简化了 Layer Norm ,去除掉计算均值进行平移的部分。
对比LN,RMS Norm的计算速度更快。效果基本相当,甚至略有提升。
3. Deep Norm
Deep Norm方法在执行Layer Norm之前,
up-scale了残差连接 (alpha>1);另外,
在初始化阶段down-scale了模型参数(beta<1)。
4 不同Ln模式
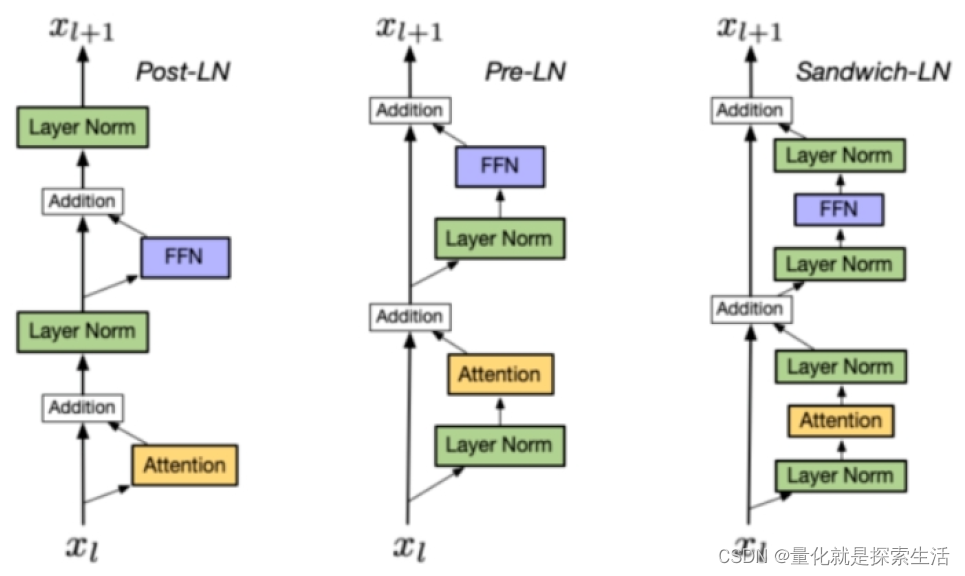
4.1. Post LN:
- 位置:layer norm在残差链接之后
- 缺点:Post LN 在深层的梯度范式逐渐增大,导致使用post-LN的深层transformer容易出现训练不稳定的问题
- 举例:Transformer原生,ChatGLM6B(Deep),ChatGLM6B(RMS)
4.2. Pre LN:
- 位置:layer norm在残差链接中
- 优点:相比于Post-LN,Pre LN 在深层的梯度范式近似相等,所以使用Pre-LN的深层transformer训练更稳定,可以缓解训练不稳定问题
- 缺点:相比于Post-LN,Pre-LN的模型效果略差
- 举例:GPT3, LLaMA(RMS),baichuan(RMS),Bloom(layer),Falcon(layer)
4.3. Sandwich-LN:
Sandwich-LN:
- 位置:在pre-LN的基础上,额外插入了一个layer norm
- 优点:Cogview用来避免值爆炸的问题
- 缺点:训练不稳定,可能会导致训练崩溃。
















 3434
3434











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











