






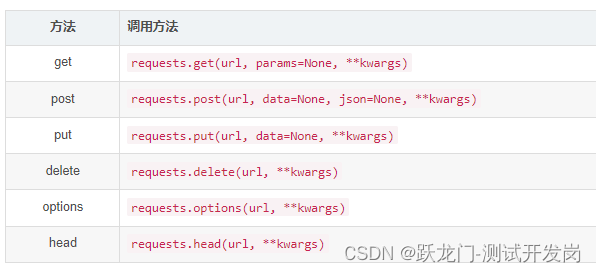
简介
requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库,使用方法比urllib更加方便。
安装
pip快速安装:pip install requests
使用说明
使用前,需要导入requests库:import requests
使用最多的方式是get和post,本章主要讲解这两种方式。
get方法
requests.get(url=url, headers=headers, params=params)
requests.get(url, params=None, **kwargs)中,除了必传的请求地址url外,还有1个默认参数params,这个参数会对url进行处理。
一般get方式请求,参数是通过url?key1=value1&key2=value2....进行拼接的。
(即 url接口路径通过?来连接,参数字段和值是=连接)。
如果url已经带有参数,则不用params参数。
如果url没有带参数,则requests.get()会将params的内容拼接到url后。
请求方式:GET
接口路径:http://httpbin.org/get
参数:name=gemey&age=22
响应报文:返回请求数据(上传的参数数据、请求头、url)和服务器地址
不带params参数和带params参数的实现方式
如下:
# -*- coding: utf-8 -*-
import requests
# url未携带参数数据
response1 = requests.get("http://httpbin.org/get?name=gemey&age=22")
print("----------url未携带参数数据----------")
print(response1.text) #返回结果的字符串形式
dict1 = response.json() #返回一个字典
print(dict1["name"]
#使用jsonpath
#jsonpath.jsonpath
#res = jsonpath(dict1, '$..userName') 通过jsonpath获取字典的内容
# url携带参数数据
r2 = requests.get("http://httpbin.org/get", params={"name": "gemev", "age": 22})
print("\n----------url携带参数数据----------")
print(r2.text)
# url携带参数数据中有列表
r3 = requests.get("http://httpbin.org/get", params={"name": "gemev", "age": [22, 45]})
print("\n----------url携带参数数据中有列表----------")
print(r3.text)
执行结果为
----------url未携带参数数据----------
{
"args": {
"age": "22",
"name": "gemey"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.28.1",
"X-Amzn-Trace-Id": "Root=1-6353a902-4a61a3c00ac22a2e68043720"
},
"origin": "113.117.59.233",
"url": "http://httpbin.org/get?name=gemey&age=22"
}
----------url携带参数数据----------
{
"args": {
"age": "22",
"name": "gemev"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.28.1",
"X-Amzn-Trace-Id": "Root=1-6353a903-3c89e1b00e5b6cd47ecdcc53"
},
"origin": "113.117.59.233",
"url": "http://httpbin.org/get?name=gemev&age=22"
}
----------url携带参数数据中有列表----------
{
"args": {
"age": [
"22",
"45"
],
"name": "gemev"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.28.1",
"X-Amzn-Trace-Id": "Root=1-6353a903-0dff9b3716a2a1c12b3aa474"
},
"origin": "113.117.59.233",
"url": "http://httpbin.org/get?name=gemev&age=22&age=45"
}
get方法不使用Content-Type请求头
'Content-Type': 'application/json' 是一个HTTP头部字段,用于指定请求的主体部分是JSON格式的数据。对于GET方法来说,这个字段通常用不到,因为GET方法通常不包含请求体,它们将参数附加在URL上。
post方法
requests.post(url=url, headers=headers, data=params,json=params)
如果想上传的数据较大,或者上传的数据对服务器方的数据库、文件等内容有修改,一般使用Post请求,post请求上传数据的方式有:表单、Json、文件等。
以下的post示例中,所使用的接口信息如下:
请求方式:POST
接口路径:http://httpbin.org/post
参数:可按照请求逻辑设置
响应报文:返回请求数据(上传的参数数据、请求头、url)和服务器地址
表单
post请求上传表单数据时,是通过data参数上传的,入参的数据是字典对象(dict)
# -*- coding: utf-8 -*-
import requests
url = 'http://httpbin.org/post'
data = {
'name': 'jack',
'age': 23
}
r = requests.post(url, data=data)
print(r.text)
执行结果为:
{
"args": {},
"data": "",
"files": {},
"form": {
"age": "23",
"name": "jack"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "16",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.31.0",
"X-Amzn-Trace-Id": "Root=1-65dbfa07-3a22e6411689df0253a21c00"
},
"json": null,
"origin": "183.199.52.170",
"url": "http://httpbin.org/post"
}从执行结果来看,form参数请求正常,请求的Content-Type字段会被设置为application/x-www-form-urlencoded。
Json
json也是post请求经常用到的数据上传格式,如果上传的数据是json格式,需要将python字典对象通过json参数传入,示例如下
# -*- coding: utf-8 -*-
import requests
url = 'http://httpbin.org/post'
data = {
'name': 'jack',
'age': 23
}
r = requests.post(url, json=data)
print(r.text)
执行结果如下:
{
"args": {},
"data": "{\"name\": \"jack\", \"age\": 23}",
"files": {},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "27",
"Content-Type": "application/json",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.31.0",
"X-Amzn-Trace-Id": "Root=1-65dbfa9f-7880f5d5458252a516606404"
},
"json": {
"age": 23,
"name": "jack"
},
"origin": "183.199.52.170",
"url": "http://httpbin.org/post"
}从执行结果来看,form参数为空,参数为data数据,配置为json传参时,请求的 Content-Type字段会设置为 "application/json"。
通过查看requests库中的post方法,也是有两种入参方式,如图

响应对象
requests.get()或post()请求后,得到一个Response对象,Response对象有很多属性和方法,常用如下:

如果需要校验 request 调用接口返回的字段,应该使用resp.json() 返回字典数据。
例如
# -*- coding: utf-8 -*-
import requests
url = 'http://httpbin.org/post'
data = {
'name': 'jack',
'age': 23
}
resp = requests.post(url, data=data)
result1 = resp.json()
print(type(result1)) # resp.json()返回的类型为字典:<class 'dict'>
result2 = resp.text
print(type(result2)) # resp.text返回的类型为字符串:<class 'str'>
print(result1['form']['age']) #取字典数据正常,结果为23结果为
<class 'dict'>
<class 'str'>
23上传类型
一般上传文件的请求,其请求头中的Content-Type字段值类似于
"Content-Type": "multipart/form-data; boundary=xxx",
且其请求报文中,有name、filename字段,
服务器端一般会检查name、filename、Content-Type这3个字段中某个或多个的字段值
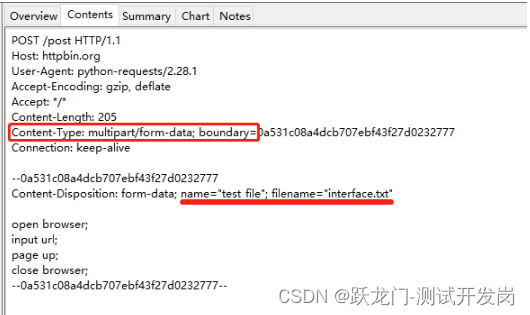
request()函数中有个files参数,用来处理文件上传,files参数需要指定name和filename(Content-Type会被默认指定值),格式为:
- {"name": ("filename", open("待上传文件完整路径", "rb"))}:指定了name和filename的值
- {"name": open("待上传文件完整路径", "rb")}:指定了name的值,filename的值默认为上传文件的文件名和后缀
示例:
# -*- coding: utf-8 -*-
import requests
url = 'http://httpbin.org/post'
r1 = requests.post(url,files={"test_file": open("D:\\test_code\\allure_demo\\interface.txt", "rb")})
print("----------filename默认为上传文件的文件名+后缀----------")
print(r1.text)
r2 = requests.post(url, files={"test_file": ("unbeleivable.txt", open("D:\\test_code\\allure_demo\\interface.txt", "rb"))})
print("----------指定filename----------")
print(r2.text)
打印响应报文的结果基本一致,Content-Type字段值均类似于"Content-Type": "multipart/form-data; boundary=xxx",
执行结果如下:
----------filename默认为上传文件的文件名+后缀----------
{
"args": {},
"data": "",
"files": {
"test_file": "open browser;\r\ninput url;\r\npage up;\r\nclose browser;"
},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "205",
"Content-Type": "multipart/form-data; boundary=058d0628e3374c5f598f2bd6127971d8",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.28.1",
"X-Amzn-Trace-Id": "Root=1-6353e473-6cc609d66d687c517ce92282"
},
"json": null,
"origin": "113.117.59.233",
"url": "http://httpbin.org/post"
}
----------指定filename----------
{
"args": {},
"data": "",
"files": {
"test_file": "open browser;\r\ninput url;\r\npage up;\r\nclose browser;"
},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "208",
"Content-Type": "multipart/form-data; boundary=6b5675bf94e865759e8e3f959089fc33",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.28.1",
"X-Amzn-Trace-Id": "Root=1-6353e474-0ee3811b7a4305332066840f"
},
"json": null,
"origin": "113.117.59.233",
"url": "http://httpbin.org/post"
}
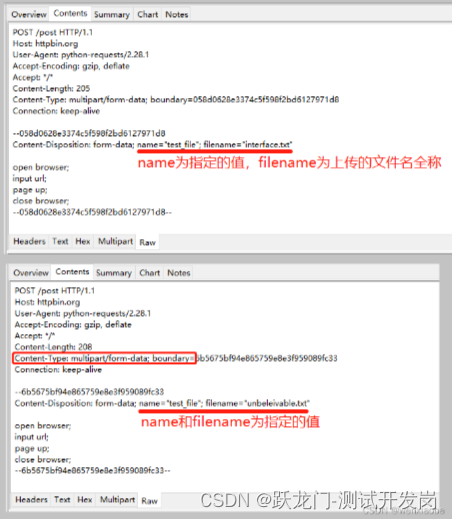
对请求数据进行抓包,可以看到name和filename字段值:
其它数据类型
Post请求不止上传文件、发送form、json数据
还支持html、xml等数据,这些数据一般通过data参数传入,
但是需要在请求头的Content-Type字段申明数据类型。
以下以xml数据示例:
# -*- coding: utf-8 -*-
import requests
xml_data = """<?xml version="1.0" encoding="UTF-8"?>
<site>
<name>RUNOOB</name>
<url>https://www.runoob.com</url>
<logo>runoob-logo.png</logo>
<desc>coding study website</desc>
</site>
"""
url = 'http://httpbin.org/post'
# 指定请求头的Content-Type字段值为对应的数据类型
headers = {"Content-Type": "application/xml"}
# 需要传入url、data、headers参数
r1 = requests.post(url, data=xml_data, headers=headers)
print(r1.text)
执行结果如下:
{
"args": {},
"data": "<?xml version=\"1.0\" encoding=\"UTF-8\"?>\n<site>\n <name>RUNOOB</name>\n <url>https://www.runoob.com</url>\n <logo>runoob-logo.png</logo>\n <desc>coding study website</desc>\n</site>\n",
"files": {},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "179",
"Content-Type": "application/xml",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.28.1",
"X-Amzn-Trace-Id": "Root=1-6353e801-32d1699104c479d37decbad3"
},
"json": null,
"origin": "113.117.59.233",
"url": "http://httpbin.org/post"
}
补充
python中的requests,response.text与response.content及其编码
import requests
response=requests.get("http://www.baidu.com/")
print(response) # <Response [200]>
print(type(response)) # <class 'requests.models.Response'>
1. response.status_code
http请求的返回状态,2XX 表示连接成功,3XX 表示跳转 , 4XX 客户端错误 , 500 服务器错误
2. response.text
http响应内容的 字符串(str) 形式,请求url对应的页面内容
打印出的内容含有乱码时,处理
修改如下, 改变下载得到的页面的编码,就可以正常打印出"友好的"文本了:
response.encoding="utf-8"
print(response.text) # 打印文本中没有乱码
3. response.content
HTTP响应内容的 二进制(bytes) 形式
小结:更改编码使用 response.content.deocde(“utf8”)
更推荐使用response.content.deocde()的方式获取响应的html页面.
4. response.encoding
从HTTP header中猜测的响应内容编码方式
5. response.apparent_encoding
从内容分析出的响应内容的编码方式(备选编码方式)
6. response.headers
http响应内容的头部内容
补充:
- json.loads()将str类型的数据转换为dict类型
- json.dumps()将dict类型的数据转成str
参考:python中的requests,response.text与response.content及其编码-CSDN博客

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









