










论文原文:
Wenzheng Chen, FangyinWei, Kiriakos N. Kutulakos, Szymon Rusinkiewicz, and Felix Heide. 2020. Learned Feature Embeddings for Non-Line-of-Sight Imaging and Recognition. ACM Trans. Graph. 39, 6, Article 230 (December 2020), 18 pages. https://doi.org/10.1145/3414685.3417825
基于嵌入特征学习的非视距成像与识别
目录
Impulsing NLOS sensing and Imaging
dulated and Coherent NLOS Imaging
NLOS Tracking and Classification
Learning Multiview Image Synthesis
3.2 transient rasterizaion 瞬态光栅化
4. Learned NLOS Scene Representations
4.1 Spatial-Temporal Feature Extraction
4.2 Latent Feature Propagation
6. Analysis and Synethetic Validation 合成数据上的结果
Abstract 摘要
研究对象:使用激光脉冲的主动非视距成像场景;
已有研究存在的问题:三次反射光衰减幅度大、信噪比低,有必要学习场景先验,故应使用监督学习方法;然而,当前没有合适的数据集,而且已有的网络结构重建效果不好;
本文的贡献:
- 提出的网络仍旧基于物理模型,学习了适用于重建和识别任务的场景特征表示;
- 提出的网络可以使用仿真数据(仿真数据使用一个可微的瞬时渲染器合成)进行训练,并在和训练数据不同的真实场景上进行测试;(如图1所示,第一行是仿真数据,第二行左侧是仿真数据的groundtruth,第二行右侧是在真实数据上的测试结果)
- 提出的方法能够端到端地完成不同地非视距成像任务,如图像重建,分类和物体识别;
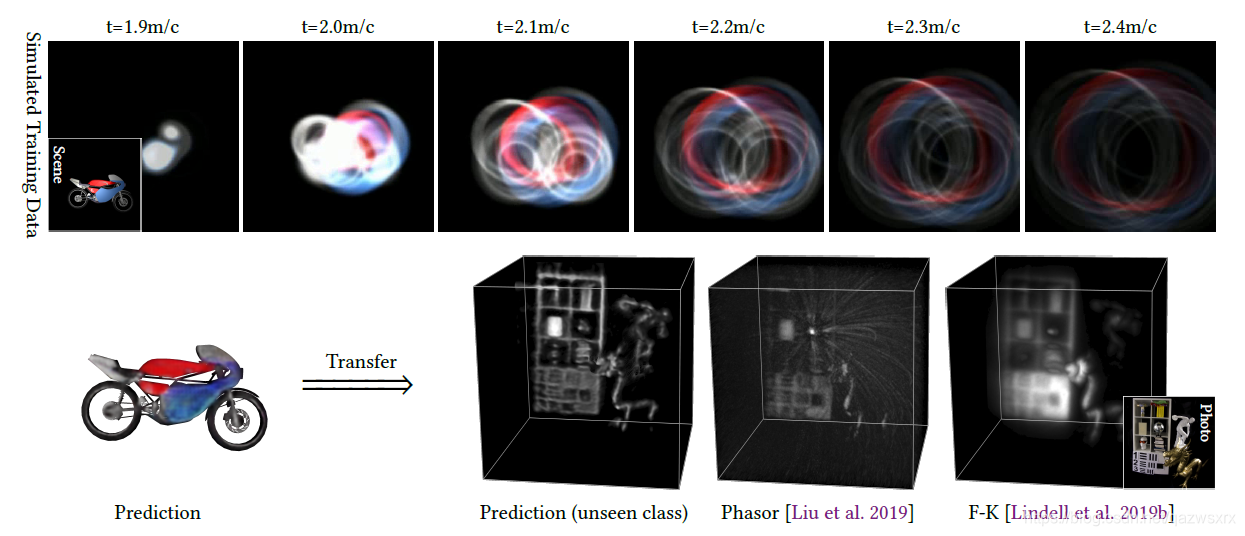
Introduction 引言
注:由于这篇文章的所述方法均针对使用激光脉冲的主动非视距成像设置(而不是passive等),所以本笔记中所有的非视距是激光脉冲主动非视距成像设置下的非视距。
第一段介绍非视距成像的含义和意义;
第二段说非视距成像存在两个限制:角度模糊和三次反射衰减导致low-signal。目前主流方法使用了transient imaging的高时间分辨方法,缓解了角度模糊的问题。因此,low-signal问题就是当前非视距重建算法面临的主要限制。
第三段继续分析low-signal的解决:先表示要解决low-signal问题就要考虑场景先验,然而现有的大多数方法是传统方法,没有考虑场景先验;考虑场景先验的一些深度学习方法也囿于没有大规模数据集和合适的网络结构而无法取得好的结果/泛化能力差。
后面几段说文章的工作和贡献:
- 构建了一个基于深度学习的模型,该模型先将合成的transient images映射到一个特征空间中,之后再将特征空间中的特征图重建为隐藏场景/ 进行识别。
- 训练数据集:由ShapeNet渲染得到;
- 测试数据集:经过了在真实数据上的测试,效果良好(如图1)。说明尽管训练用的是合成数据,但泛化能力良好。
所提方法的不足:
- 该方法需要大量的数据集才能取得更好的效果。但即便是合成数据集,训练集的大小也受制于shapeNet,因此没办法应用到足够多的场景中。
Related Work
Transient Imaging
介绍瞬态成像。之后分别介绍瞬态成像的两种获取方式:基于脉冲 和 基于干涉法
Impulsing NLOS sensing and Imaging
基于脉冲的非视距成像,特别和2020 CVPR中的Deep NLOS Reconstruction进行了对比,并表示Deep NLOS Reconstruction基于已有的encoder-decoder网络,泛化能力太差,没法用于真实数据。这篇文章则通过学习特征嵌入来弥补了domain gap.
dulated and Coherent NLOS Imaging
介绍基于干涉法的NLOS成像
NLOS Tracking and Classification
介绍非视距探测/分类任务
Learning Multiview Image Synthesis
多角度3D重建:输入为多个角度的照片,输出为三维形状;
本文:输入为多个transient images,输出为三维形状。
本文通过引入一个逆向模型来克服了过拟合,拥有良好的泛化能力。
3. Observation Model
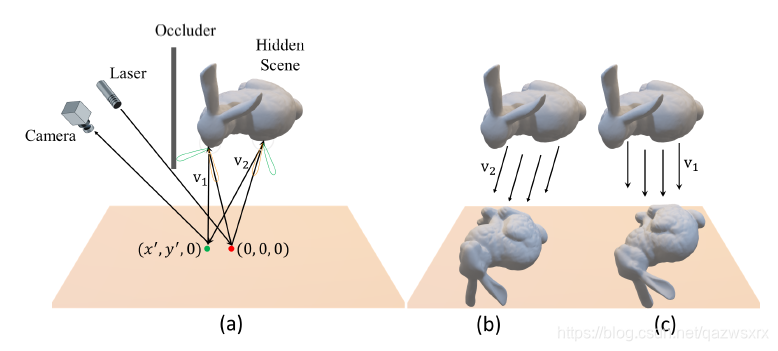
首先说明主动非视距成像的3次漫反射的含义,并给出了基本示意图:
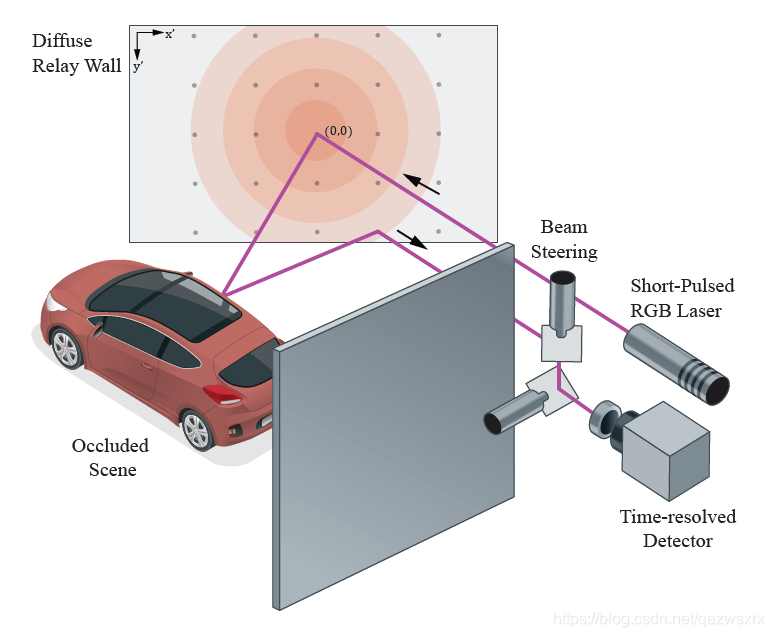
下面推导成像模型:当relay wall的形状和位置已知时,直接反射可以无视,因此,成像模型为:
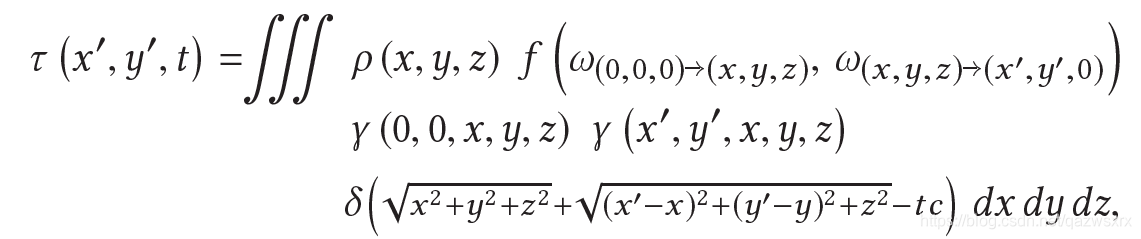
该模型和LCT等文章中的成像模型一致,其中γ表示相互的visibility,式中的v表示[0,1]的可见性,对于部分遮挡v为连续变量:
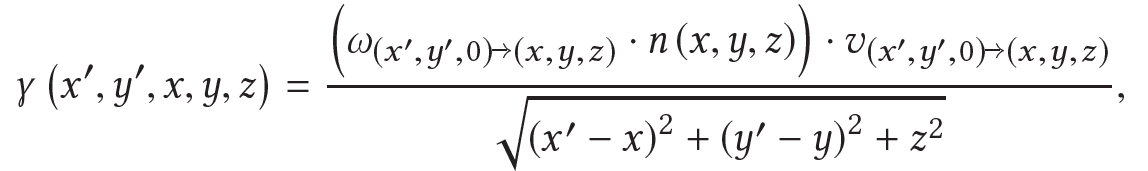
f为双向反射分布函数BRDF:
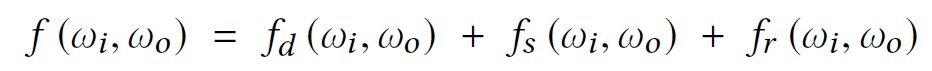
其中,fd为漫反射香;fs为镜面反射项;fr为逆向反射项。对于普通的墙,fd占主导.
注意:上述成像模型中唯一的假设是 三次反射光在隐藏场景内部只进行了1次散射。
下面是detector model和transient rasterizaion
3.1 Detector Model
首先说明了这里的detector model是指三次漫反射光经过三次漫反射后,又经过SPAD探测器时的噪声模型。
该模型参考了文章
Q. Hernandez et al. (2017) “A Computational Model of a Single-Photon Avalanche Diode Sensor for Transient Imaging,” arXiv
模型如下:
在具体实现的过程中,忽略了串扰和寄生脉冲。(crosstalk and afterpulsing)
3.2 transient rasterizaion 瞬态光栅化
除了噪声模型外,还需要一个瞬态图片的渲染模型。
渲染模型如下
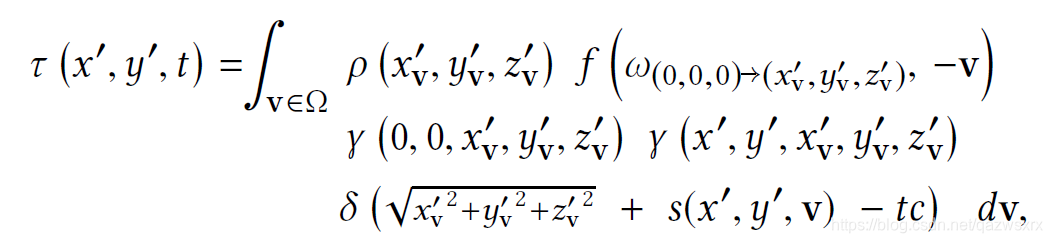
上述噪声模型和渲染模型生成数据的结果如图3下所示(图3上为真实数据)

文章所采用的光栅化瞬时图像渲染原理如图4所示,其中(a)示出了反射由三个部分组成,分别是镜面、漫和逆向反射;(b)和(c)表示不同的投影方向会在中继面得到不同的投影
光栅化的结果如图5所示:
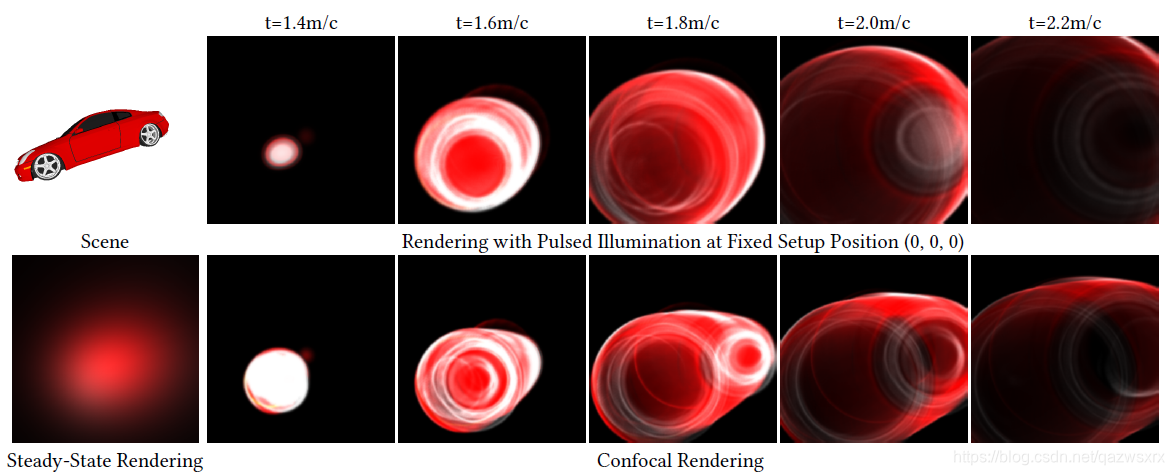
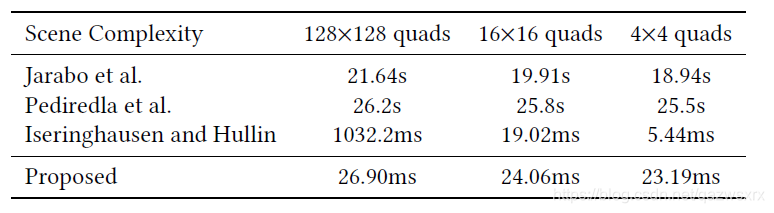
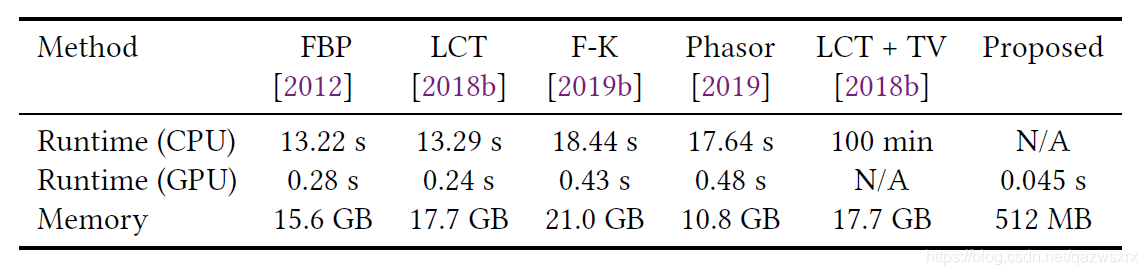
表1则示出了论文提出的渲染方法在时间上相对于其他方法的优势:
4. Learned NLOS Scene Representations
提出的网络结构如图6所示,它的核心是提取体素特征。
这里还用了一个完全倒装句(lies at): At the core of the algorithm lies a learned volumetric feature representation of the 3D object.
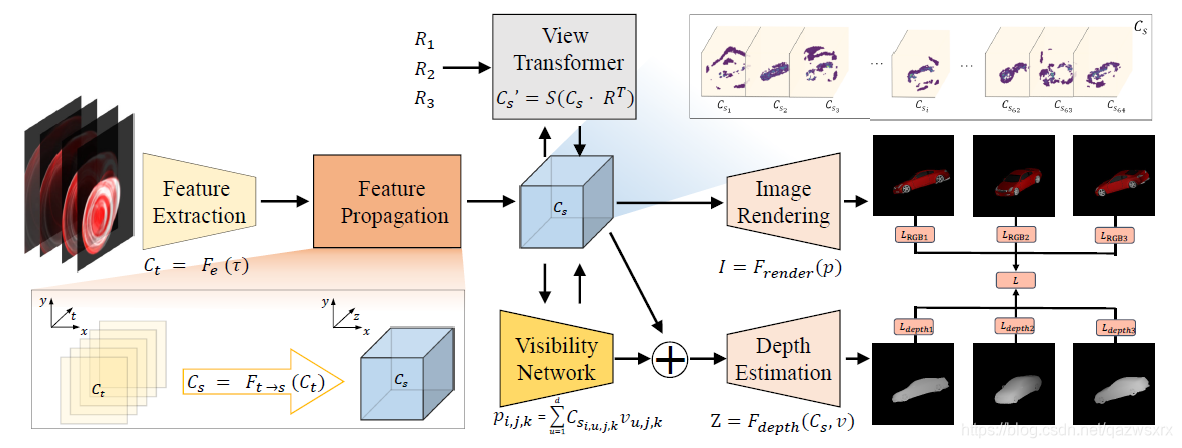
(因为使用了深度学习,)这里的特征并仅仅是对体素-反照率信息的编码,而是同时对形状、遮挡、法线、语义等很多信息的编码。
获取这个特征嵌入的过程分为两步:
- step1: 使用卷积网络提取transient images中得时空特征;这样做的动机是transient image是稀疏的:
(transient images) are sparse with large areas of low entropy. Instead of propagating all intensity values to a hidden volume, e.g., as in backprojection methods [Velten et al. 2012], we reason only on features that are critical for reconstruction, e.g., spherical wavefront shapes of scene objects instead of measurement noise or ambient background.
从而使提取的特征smaller;
- step2: 解码(feature propagation). 即将提取到的特征propagate至目标特征空间(也就是隐藏场景的空间形状特征空间),这一过程可以使用基于深度学习的方法,也可以使用传统方法,如反向投影。
上述两步可以formulated为:
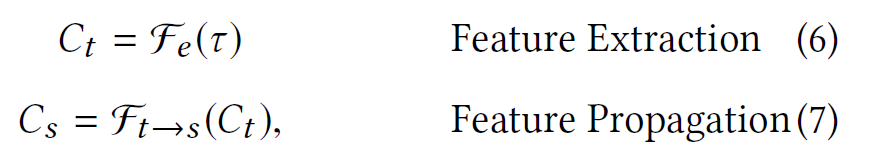
4.1 Spatial-Temporal Feature Extraction
描述了上面step1所需要使用的网络结构;
4.2 Latent Feature Propagation
这一步完成的是将采集数据得时空信息 映射到 隐藏场景空间domian. 因此,在整个网络中是重要得一步。
这一步最重要的是提取全局特征,而这也是目前善于提取局部特征的神经网络相关研究所不擅长的。
本文的解决方案是将深度学习与传统算法相结合。但根据论文,所谓相结合的意思好像只是说可以从传统方法的角度(如BP,LCT等)来理解本步骤所完成的从采集数据得时空信息 到 隐藏场景空间的映射。
4.3 Feature Abstraction
最后还进行了一个特征提取步骤,以得到最终的embedding features.
5. End-to-end NLOS Networks
如图6所示,这篇文章根据功能不同共设计了如下端到端网络:
- 二维图像重建;
- RGB-D结果重建;
- 识别与估计;
而使用到的网络模块主要有4个:
- a view transformer: 基于相机位置在空间上转换3D特征图;
- a visibility network: 在体素嵌入的基础上预测visibility;
- a differentiable render: 在隐藏图片2D特征的基础上渲染得到高质量的RGB图片;
- a depth estimator: 在给定3D表示喝对应的visibility map的基础上估计深度。
5.1 2D Rendering 二维渲染
View Transformer
输入:前一节得到的3D特征Cs: (c,d,w,h),其中c为每一个位置的特征向量长度;d,w,h分别为深度宽度高度;
操作:
其中,R为旋转矩阵;S为用于计算最终离散空间中取值的算子。
Visibility Network
输入:前一节得到的3D特征Cs: (c,d,w,h),
输出:Cs的一个平面表示p: (c,h,w)
Image Renedering Network
输入:p
输出:高质量RGB图I
Depth Rendering Network
输入:可见性map--v ; 和 特征图--p
输出:深度图Z
![]()
5.2 RGB-D Reconstruction
训练过程:
输入的瞬时图片经过特征提取、映射和进一步提取,得到嵌入特征图(第四节);
之后,由View Transformer得到典型视角;再使用visibility network得到visibility map;
最后,得到渲染二维图片和RGB-D的重建结果;
上述过程中的总损失函数为:
除此之外,文章还添加了多视角监督。即训练过程中使用了不同的非标准视角,进行监督学习:
其中,m表示不同视角的个数。
5.3 Classification 分类
直接将第四节得到的embedding feature输入一个分类网络,得到分类结果。损失函数为softmax,如下:
5.4 检测
边界框为(xmin, xmax,ymin,ymax, zmin)
检测损失函数为:
6. Analysis and Synethetic Validation 合成数据上的结果
合成数据集由ShapeNet得到;
数据集包括两个部分:摩托车数据集和汽车数据集。
其中汽车有2244个样本;摩托车有6925个样本;
并通过旋转和平移进行了数据增强;
除此之外,也合成了多分类的数据集,包括ShapeNet中的13个类别,每个类别包括了446-500个transient images. 训练:验证:测试=8:1:1
对成像模型、噪声模型和渲染模型均设定了参数,从而进行仿真。
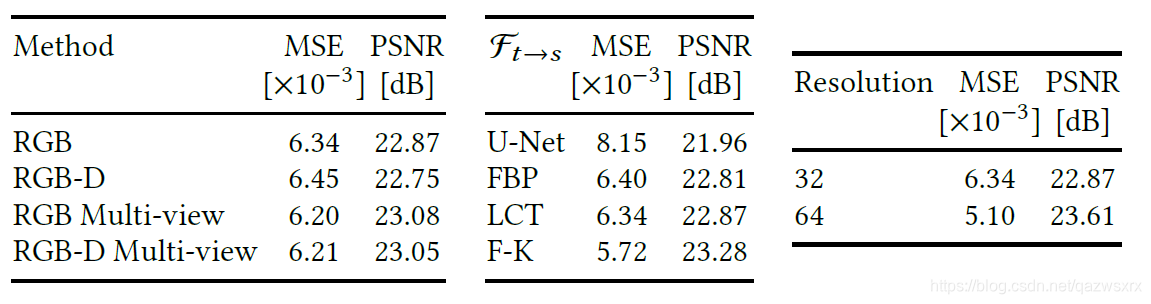
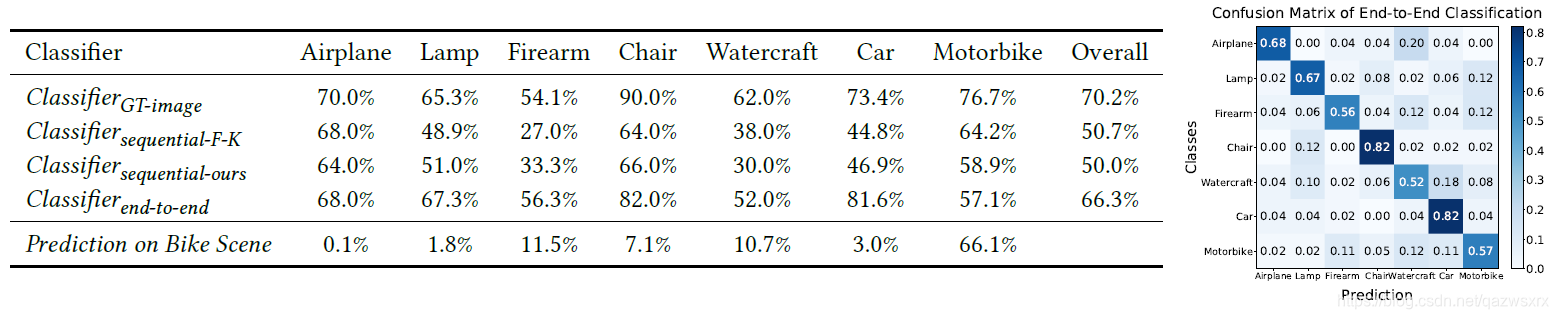
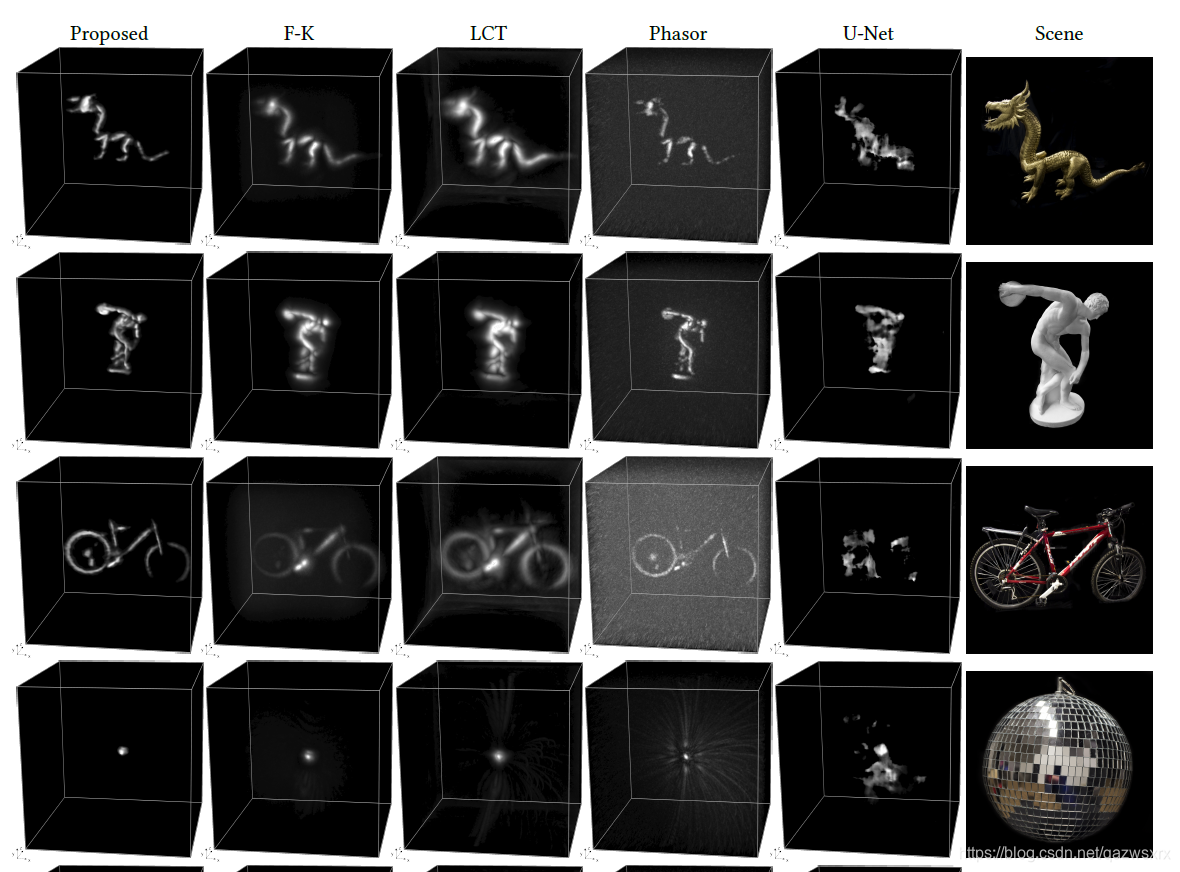
在合成数据上结果如下:
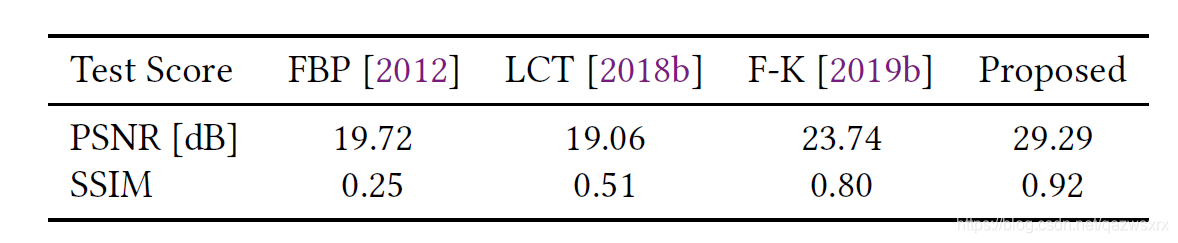


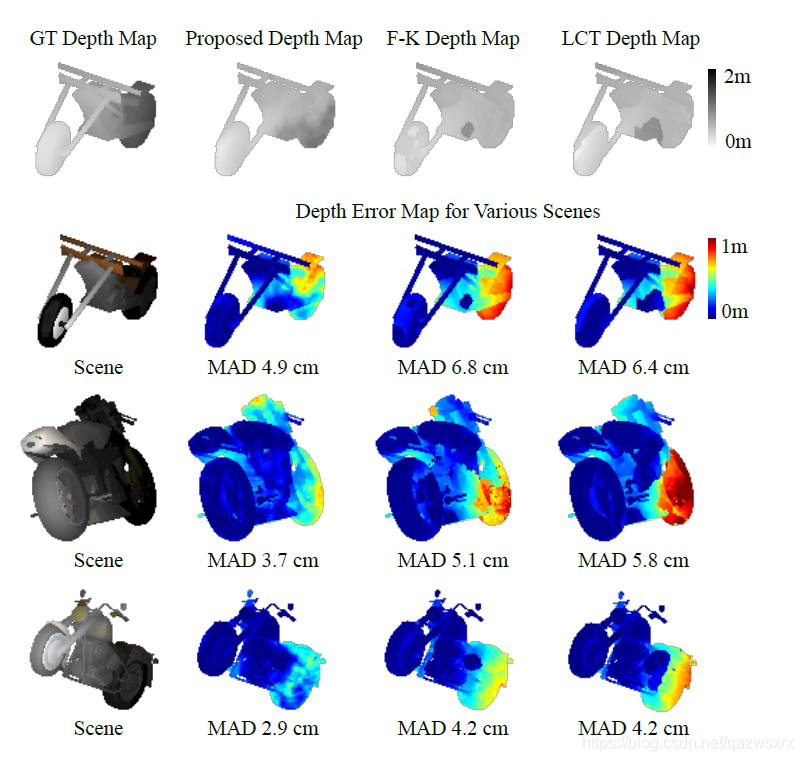

7. 真实实验数据上的测试结果
下面是真实数据上的测试结果,这决定了该项研究是否真的有意义
可见,本文的结果要好于2020 CVPR上Deep NLOS Reconstruction的结果。
总结
相对于其他的深度学习主动非视距成像研究,此研究将网络中的重要一步与传统方法相结合,取得了很好的效果。
======================================================================================================
本文为阅读笔记,阅读的论文是:
Wenzheng Chen, FangyinWei, Kiriakos N. Kutulakos, Szymon Rusinkiewicz, and Felix Heide. 2020. Learned Feature Embeddings for Non-Line-of-Sight Imaging and Recognition. ACM Trans. Graph. 39, 6, Article 230 (December 2020), 18 pages. https://doi.org/10.1145/3414685.3417825
本阅读笔记原载于 我的博客
如有错误,请联系 rxnlos@126.com
======================================================================================================



















 7051
7051

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











