







“ 但行好事,莫问前程”
目录
IpAdapter已经是基于stable diffusion的现象级应用模型,它可以将指定图的特征传递到生成图上。很多人对他的使用还只是停留在‘垫图’这一简单的应用,本文就来给大家讲解他的更多细节和使用技巧。
01
—
基础使用
IpAdapter基础使用方式如下所示:

此流程我使用了某知名黑人的脸部作为IpAdaper的特征图片输入,IpAdapter模型也是使用了针对的Face_plus模型版本,生成了他的宇航员图像。自己也可以在此流程上增加controlnet,蒙版重绘等精准控制图像内容和区域(比自己训练lora是不是容易一百倍呢😁)
使用controlnet:
使用蒙版:
插件名称:

注意:IpAdapter需要两种模型,一种是IPAdapter基础模型,放到models的Ipadapter文件夹下:
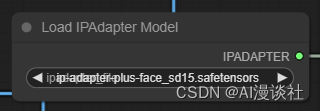
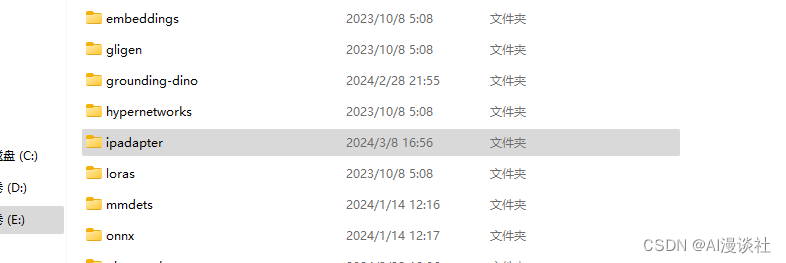
https://huggingface.co/h94/IP-Adapter-FaceID/tree/main
一种是图片视觉编码模型,放到models的clip_vision文件夹下。其中两种视觉编码模型【CLIP-ViT-H-14-laion2B-s32B-b79K and CLIP-ViT-bigG-14-laion2B-39B-b160k】下载下来的名字都是“model.safetensors” 自己注意改名
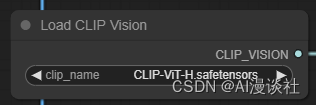

[ViT-H]https://huggingface.co/h94/IP-Adapter/resolve/main/models/image_encoder/model.safetensors [ViT-bigG]https://huggingface.co/h94/IP-Adapter/resolve/main/sdxl_models/image_encoder/model.safetensors
不方便下载的同学可以到我的公众号,回复“垫图”来获取百度网盘链接!
02
—
注意点和节点细节
注意点
一、如果运行报错如:
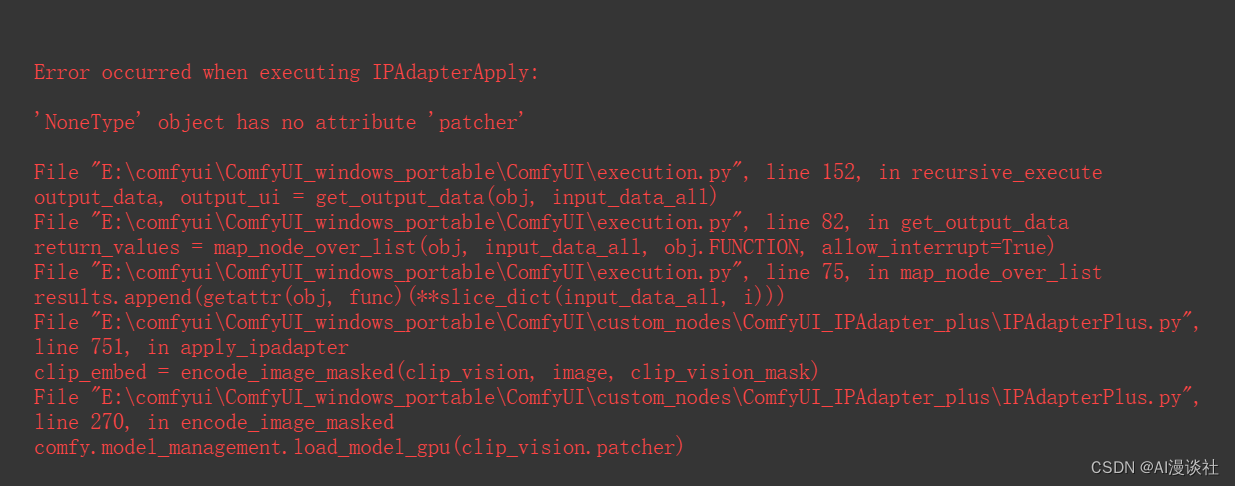
请按照如下流程检查
-
自己下载的模型是否正确,尤其是clip_version模型,可以尝试切换其他模型。
-
检查自己的主模型和ipAdapter模型是否匹配,如是否都是sd1.5或XL的模型
-
尝试更新comfyUI,包括不限于主体,插件,依赖
二、iPAdapter的特征图像在导入时总是截取中间部分!
iPAdapter编码器会将图像的大小调整为224×224,并将其裁剪到中心!
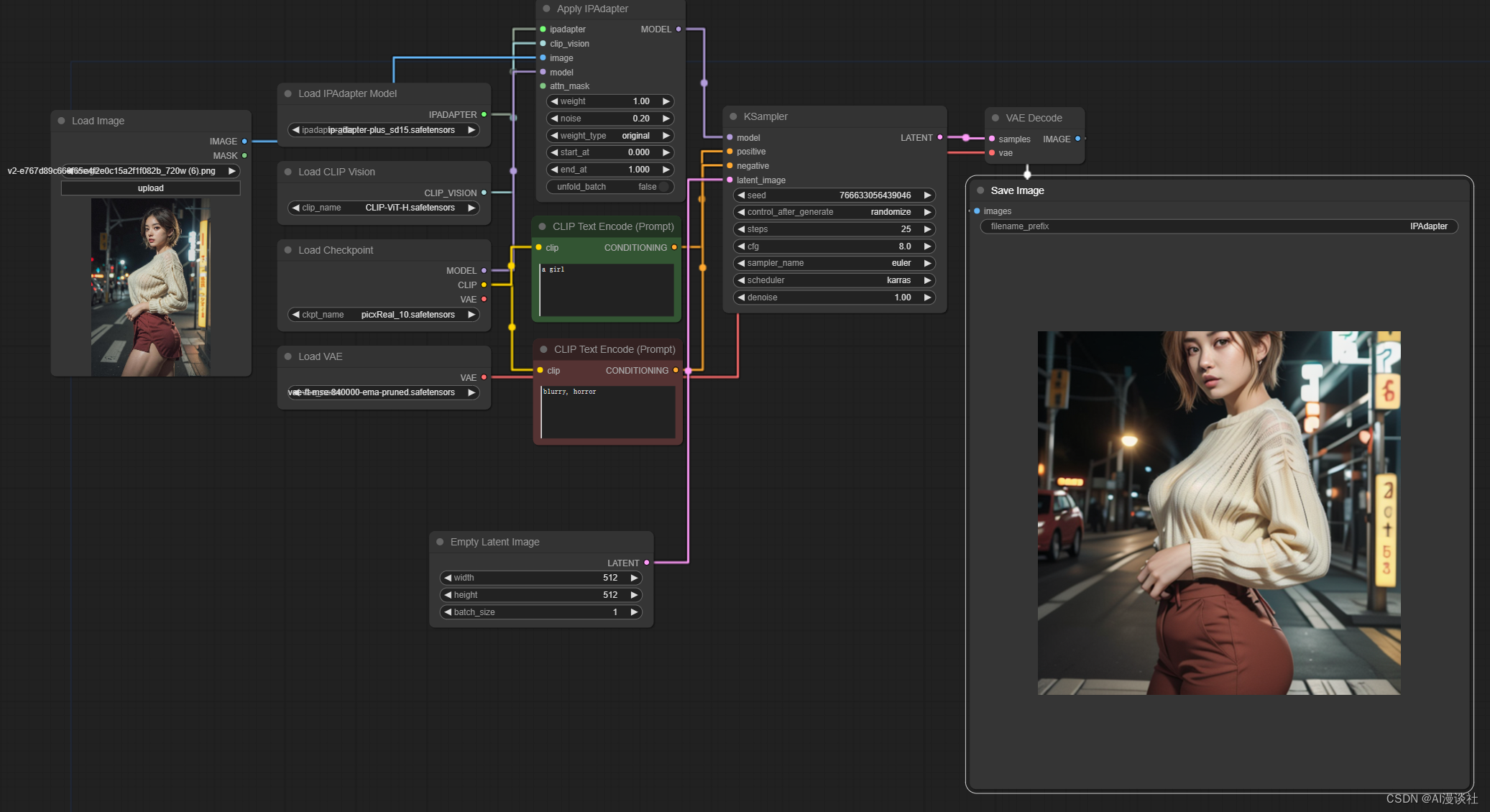
如上图所示,镜头和特征提取总是聚焦在中间位置,这种时候可以通过此【prepare image for clip vision】这个节点去控制镜头位置。

此节点三个输入分别是截图算法,截取位置,和图像锐化处理(锐化处理对出图的线条细节会有提升)
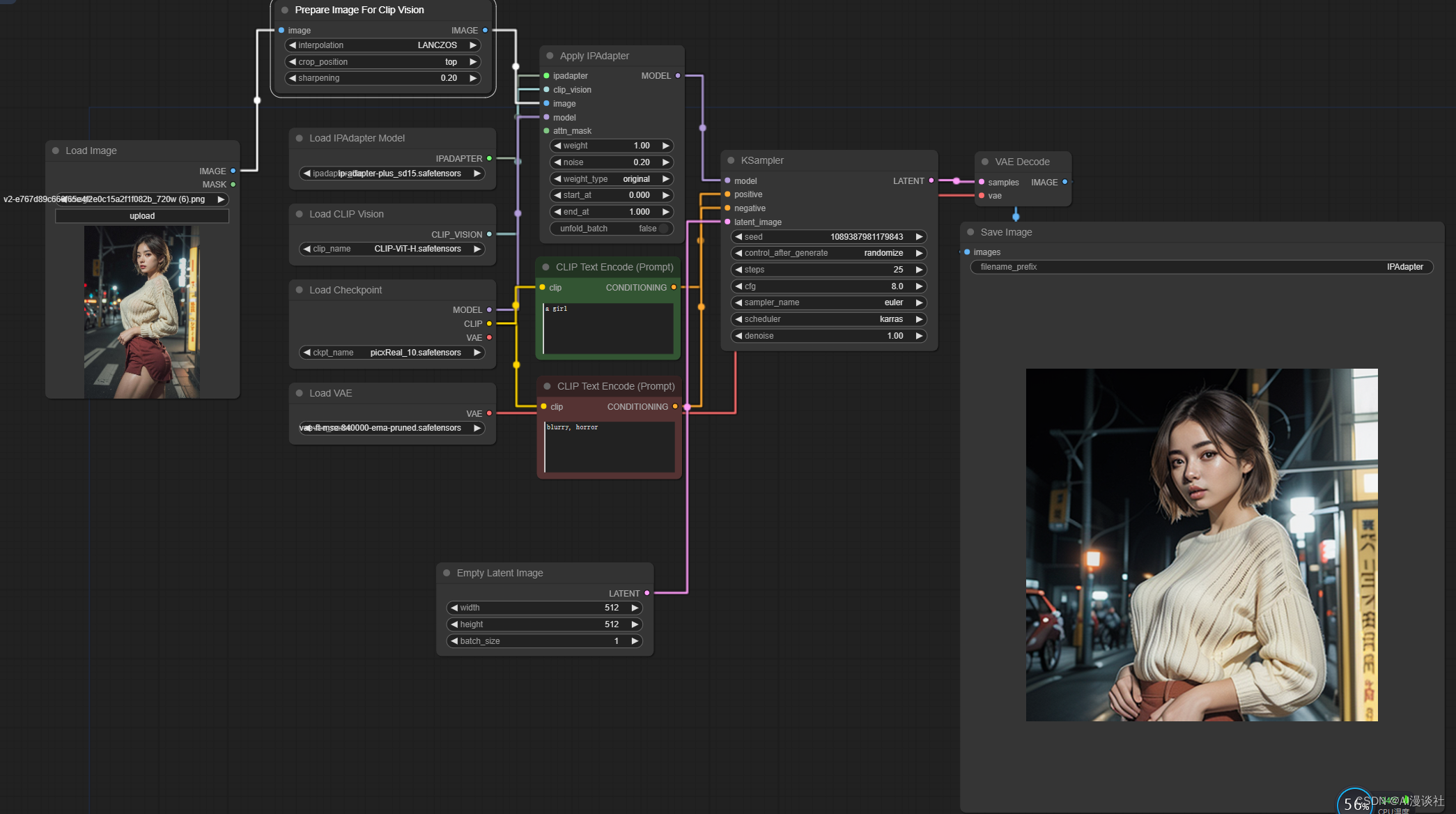
效果如图
三、Apply IpAdapter(应用节点设置)
1. noise(噪声)最好设置成0以上,至少0.0.1
虽然过多的噪声会导致图像有更多额外的细节出现,但是如果一点噪声都不给,会导致图像非常“干”如下图所示。
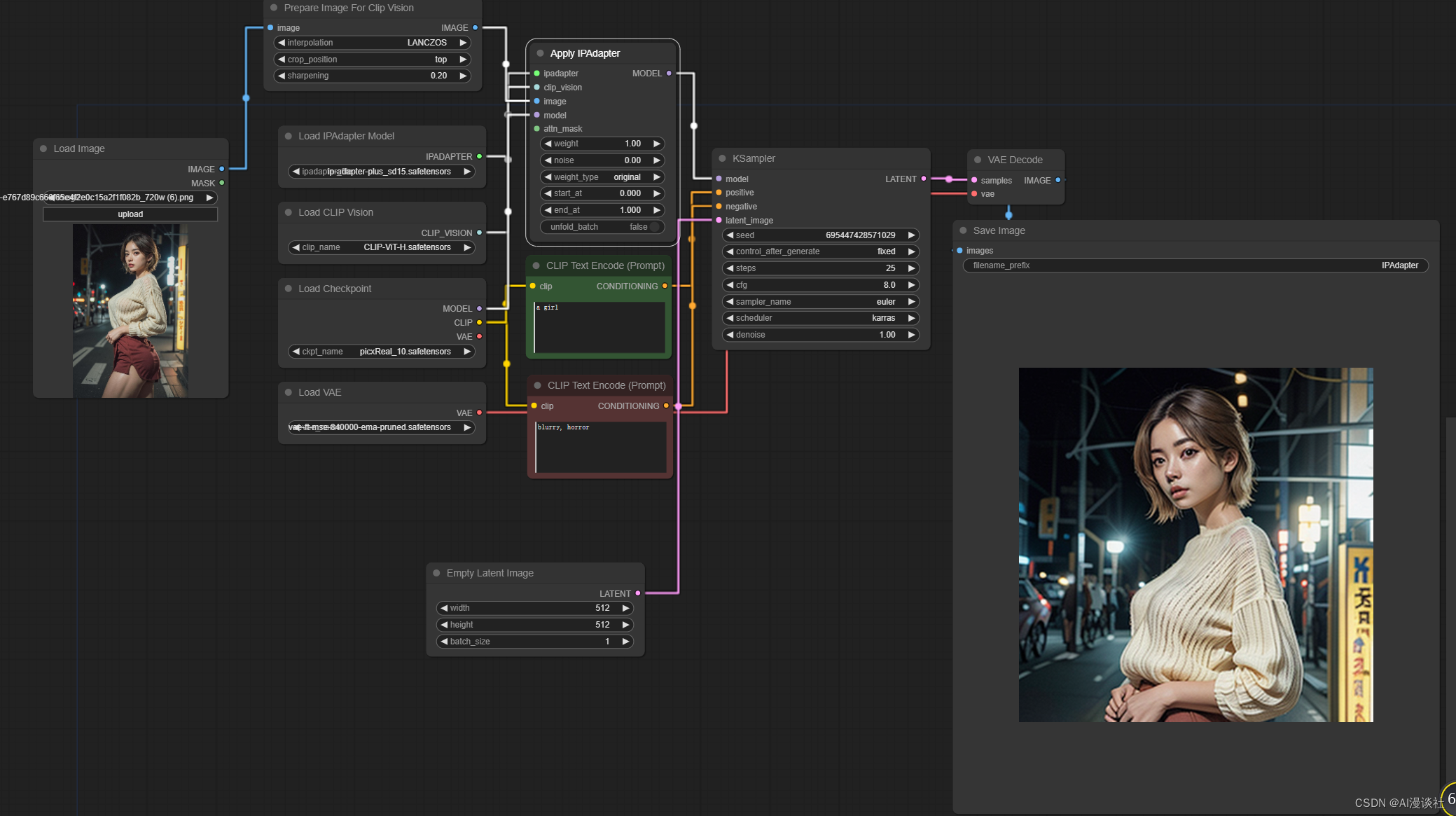

0噪声效果
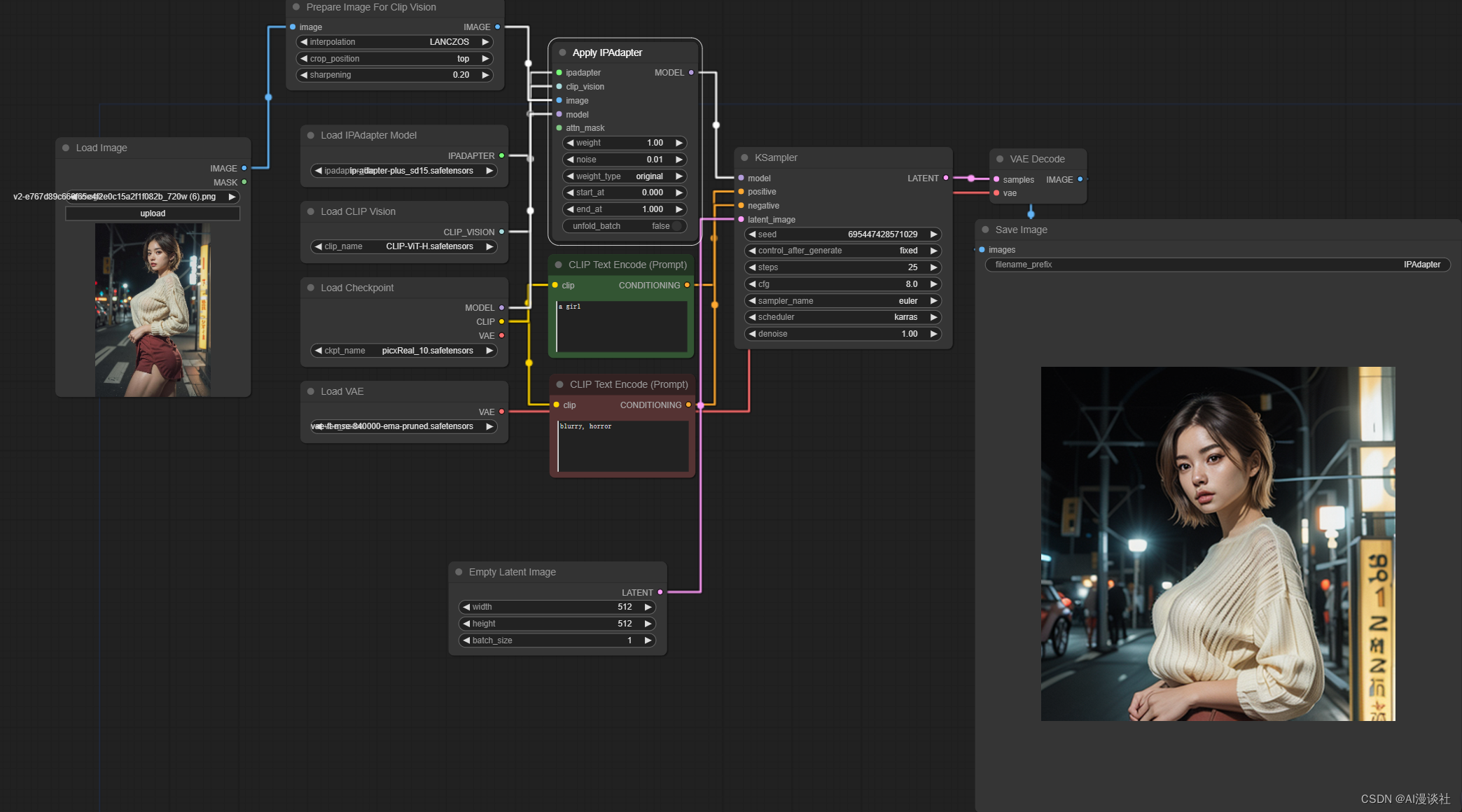

0.0.1噪声效果
2. 三种(weight)权重的效果差别
据官网说法和我自己测试:
-
original: 效果较为均衡,在值大于1或者小于1时效果都还可以
-
linear: 在值大于一时效果较强
-
channel penalty: 测试类型(我实验效果相对在各方面都最好)图像会偏锐利一些。
送上官网对比图:

3. 影响时间控制:
在“应用IPAdapter”节点中,可以设置起点和终点。IPAdapter将仅在该生成时间段内应用模型。用这个来控制特征图片的强度比noise好多了。
效果直接上官网图:

可以看到基本上开始时间是否从起点开始更加影响模型效果。
下一篇我将讲解IpAdapter的进阶应用:
-
更大的特征图片?
-
放大模型
-
代替lora?
-
如何精准控制
查看我的公众号,还有更多教程分享!
——因为热爱的AI漫谈社

















 5525
5525

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









