







目录
目前,由大模型驱动的编程助手发展态势迅猛。国际上,GitHub Copilot 作为先驱成绩斐然,付费订阅用户已达 180万。Claude 3.5 Sonnet 编程能力大幅提升,OpenAI 的 o1 模型编程与数学能力突出。国内,众多大厂纷纷布局,阿里云通义灵码下载量超 200 万,百度 Comate 服务超 1 万家企业,腾讯云 AI 代码助手升级后为企业提供多种方案。整体上,大模型编程助手不断迭代优化,正处于高速发展中。
虽然国内外主流的大模型均提供在线编程助手功能,但这种方式在很多场合不适用,不少用户需要本地私有化大模型助手。
在本地部署大模型编程助手有数据安全与隐私保护、性能优化、自主可控等好处,以下是具体介绍:
(1)数据安全与隐私保护:所有与编程相关的数据,包括代码片段、项目文档以及与编程助手的交互记录等都存储在本地设备或服务器上,不会像使用在线编程助手那样将数据传输到远程服务器,从而降低了数据泄露的风险,尤其对于处理敏感信息或机密项目的企业和开发者至关重要。
(2)性能优化,低延迟响应:本地部署的编程助手与本地开发环境直接交互,无需通过网络发送请求和接收响应,大大减少了通信延迟,能够实现更快速的代码补全、语法检查和智能提示等功能,提高编程效率。
(3)自主可控:开发者可以自主决定何时以及是否更新编程助手的模型和软件版本,避免因在线服务的强制更新而可能带来的兼容性问题或功能变化对工作造成的影响。同时,也可以根据自身需求对本地部署的编程助手进行定制化开发和修改,以满足特定的编程需求和工作流程。
基于上述原因,本文将详细阐述在本地部署私有化大模型编程助手的完整流程。
一、简介
1.1 CodeGeeX4-ALL-9B大模型
CodeGeeX4-ALL-9B 是由智谱 AI 在 2024 年世界人工智能大会上发布的第 4 代 CodeGeeX 代码大模型。以下是对它的介绍:
(1)技术基础:基于 GLM-4-9B 框架构建,内置 94 亿参数。
(2)功能特性:是全能代码助手,单一模型支持代码补全和生成、代码解释器、联网搜索、工具调用、仓库级长代码问答及生成等功能,全面覆盖软件开发全生命周期。支持超过 300 种编程语言,能跨越语言界限。支持 128k 上下文,可处理长代码文件及项目代码,在 “大海捞针” 评估中实现 100% 检索准确度。是目前唯一实现 Function Call 的代码大模型。
(3)性能表现:在 BigCodeBench 和 NaturalCodeBench 等权威测试中,以少胜多,在百亿参数量级以下性能最强,超越数倍规模通用模型,完美平衡推理速度与模型效能。
要安装和使用CodeGeeX4-ALL-9B大模型,一种简单办法就是使用Ollama框架。
1.2 Ollama
Ollama是一个用于运行和管理大型语言模型(LLMs)的开源框架,以下是关于它的简单介绍:
特点:
(1)易于使用:Ollama 提供了简单的命令行界面(CLI)和直观的 API,方便用户快速启动和与各种 LLMs 进行交互,即使是没有深厚技术背景的用户也能轻松上手。
(2)模型管理便捷:支持在本地轻松下载、安装和管理多种不同的 LLMs,用户可以根据自己的需求快速切换使用不同的模型,而无需复杂的配置过程。
(3)高性能:经过优化,能高效利用系统资源,在运行 LLMs 时实现快速的响应和推理,有助于提升模型的应用效率,降低延迟。
(4)支持多种模型:涵盖了包括 Llama 2、Mistral 等多种主流的 LLMs,为用户提供了丰富的选择,满足不同任务和领域对语言模型的特定要求。
需要说明的是,无论是CodeGeeX4-ALL-9B还是Ollama均是开源项目。CodeGeeX4-ALL-9B遵循Apache-2.0 license,Ollama遵循MIT License。
CodeGeeX4-ALL-9B在开源后不到24小时就获得了Ollama的支持,目前通过Ollama下载已经超过了6000次+。
二、安装
2.1 安装Ollama
首先前往Ollama官网下载相应的版本。本文选择Linux版本进行下载(本文基于Ubuntu操作系统进行演示),如下图所示。
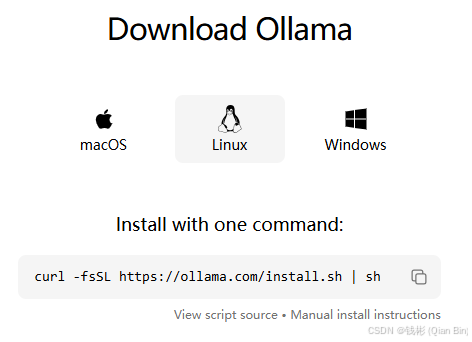
按照官网提示命令进行下载即可。经过实际测试,在国内网络环境下安装 Ollama 可能会遇到下载缓慢或失败的问题,如下图所示:
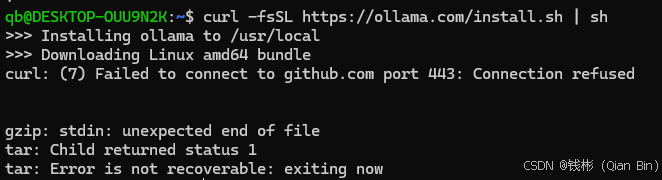
具体解决方案如下:
(1)下载并修改安装脚本
curl -fsSL https://ollama.com/install.sh -o ollama_install.sh然后,给脚本添加执行权限:
chmod +x ollama_install.sh(2)修改下载源
Releases · ollama/ollama · GitHub
打开 ollama_install.sh,找到以下四个下载地址:
https://ollama.com/download/ollama-linux-${ARCH}.tgz${VER_PARAM}
https://ollama.com/download/ollama-linux-${ARCH}-jetpack6.tgz${VER_PARAM}
https://ollama.com/download/ollama-linux-${ARCH}-jetpack5.tgz${VER_PARAM}
https://ollama.com/download/ollama-linux-${ARCH}-rocm.tgz${VER_PARAM}这四个下载地址需要进行替换。首先进入Releases · ollama/ollama · GitHub然后找到对应文件的下载路径,将网址替换掉即可。如下所示:
https://github.com/ollama/ollama/releases/download/v0.5.7/ollama-linux-amd64.tgz
https://github.com/ollama/ollama/releases/download/v0.5.7/ollama-linux-arm64-jetpack6.tgz
https://github.com/ollama/ollama/releases/download/v0.5.7/ollama-linux-arm64-jetpack5.tgz
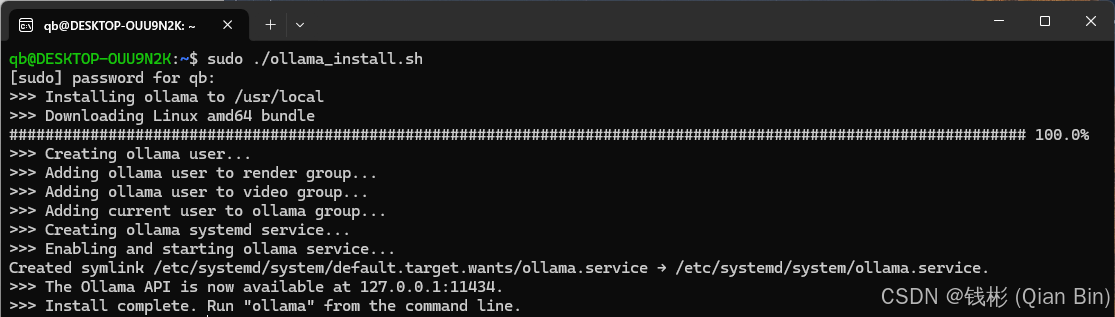
https://github.com/ollama/ollama/releases/download/v0.5.7/ollama-linux-amd64-rocm.tgz修改完成后,运行下述命令完成安装:
sudo ./ollama_install.sh如下图所示:
2.2 安装CodeGeeX4-ALL-9B
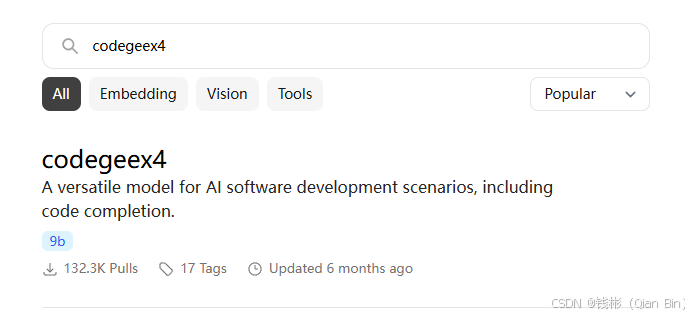
接下来打开Ollama的官网,搜索codegeex4,如下图所示:
打开进入详情页面,就可以看到CodeGeeX4-ALL-9B模型的相关介绍和使用命令了,如下图所示:
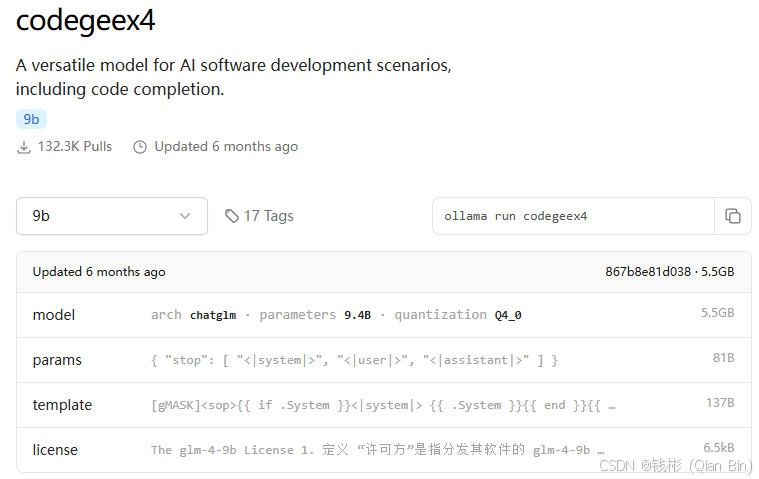
复制运行命令即可:
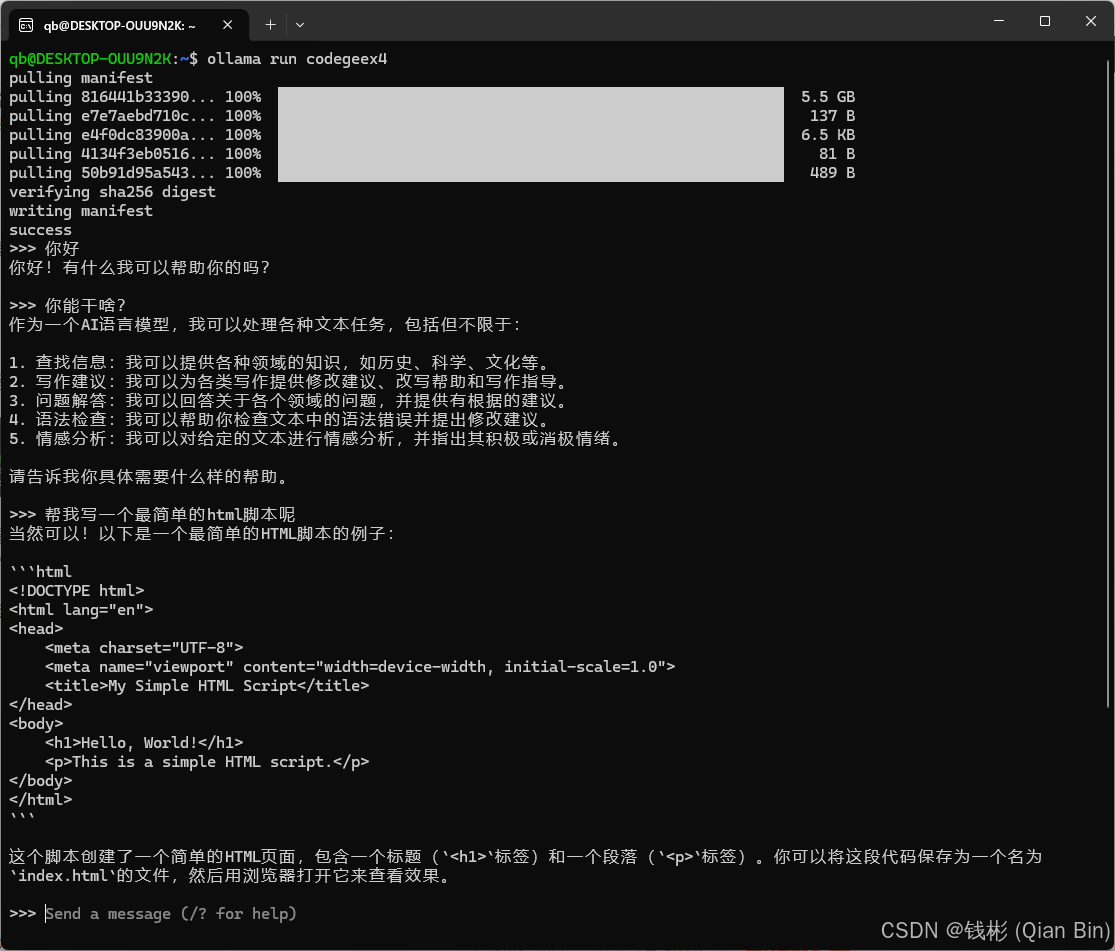
ollama run codegeex4运行后如下图所示:

看到终端命令行提示的“Send a message”就说明CodeGeeX4-ALL-9B已经成功安装在本地电脑上了。
接下来可以直接在这里输入问题和CodeGeeX4-ALL-9B进行对话,如下图所示:
三、在JetBrains中使用
本文的最终目标是在本地部署编程大模型助手,让局域网内的其他机器能够访问,提升Java编程效率。假设局域网内其他客户机为Windows,最终需要访问局域网络GPU服务器中Ubuntu系统上的大模型编程服务。
具体的,客户机操作系统为Windows 10,Java版本为JDK1.8,IDE为 IntelliJ IDEA。下面讲解具体使用方法。
3.1 离线安装CodeGeeX插件
首先下载CodeGeeX插件到本地。下载下来的是一个zip压缩文件。
下载后打开IntelliJ IDEA,然后选择从磁盘安装插件,如下图所示:
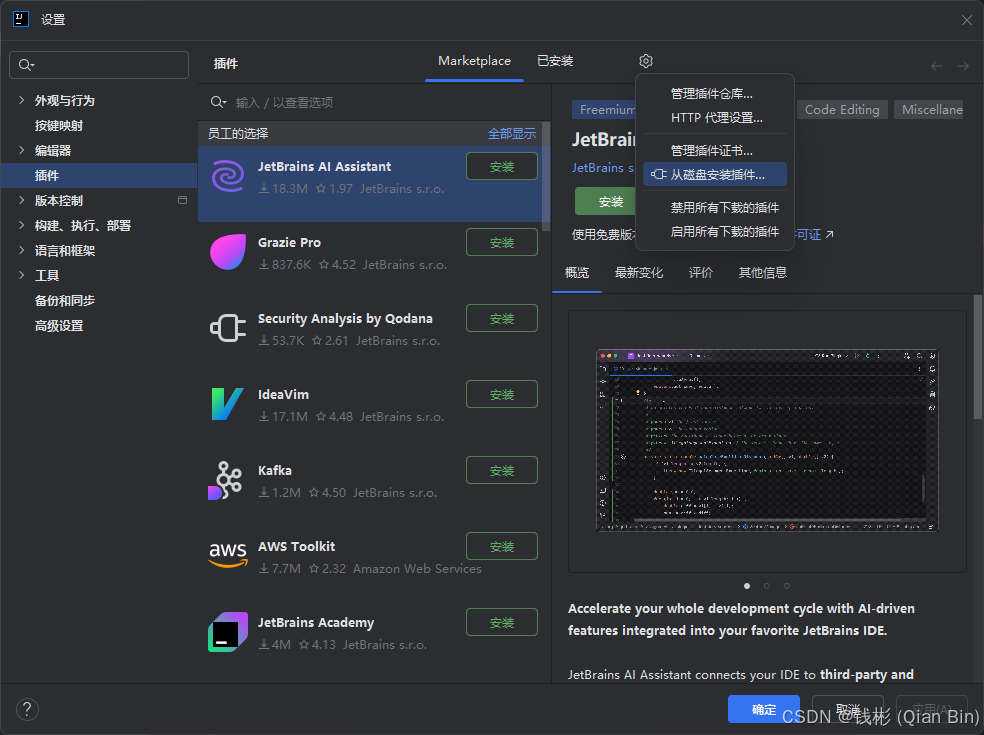
3.2 启动大模型服务
在GPU服务器上,首先使用下面的命令解除跨域限制:
export OLLAMA_ORIGINS="*"注意上述命令是临时生效的,一旦服务器重启后该命令就不生效了。如果需要永久解除跨域限制,需要在bashrc文件中修改。
接下来重启ollama服务,先停止ollama服务再重新启动:
sudo systemctl stop ollama
ollama serve启动后,再开一个终端输入下述命令即可完成编程助手服务的启动:
ollama run codegeex4这里注意,此时会重新下载codegeex4模型,因为此时是通过ollama serve服务来访问本地大模型的,这里的本地大模型路径跟之前的已经不一致了,因此会重新下载。模型一旦下载完以后,后续每次先启动ollama serve,再启动ollama run codegeex4就不需要再下载模型了。
3.3 配置CodeGeeX插件
在客户机上,重启IDEA,在右侧面板中可以找到安装的CodeGeeX插件,按照下图所示打开该插件的本地模式。
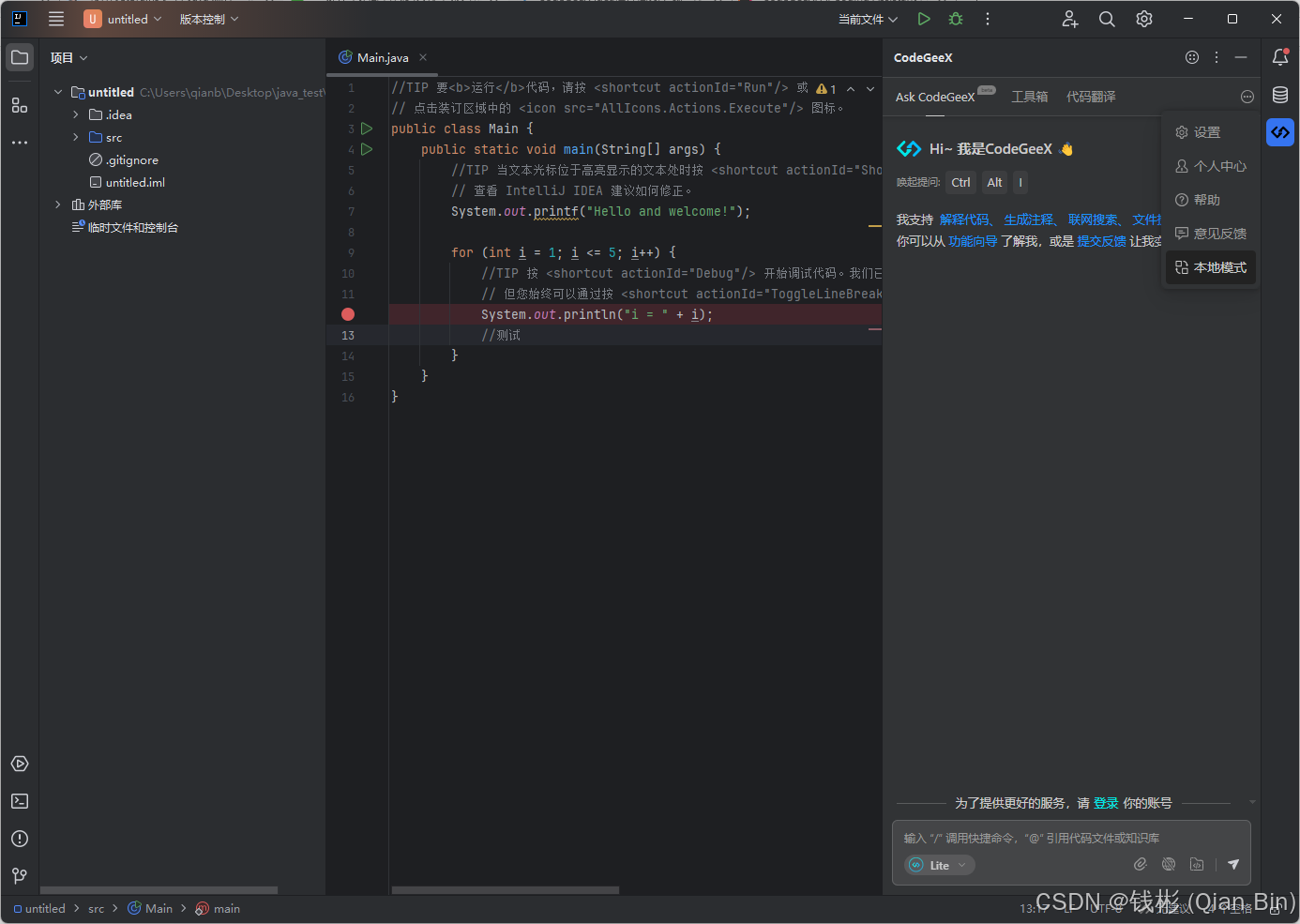
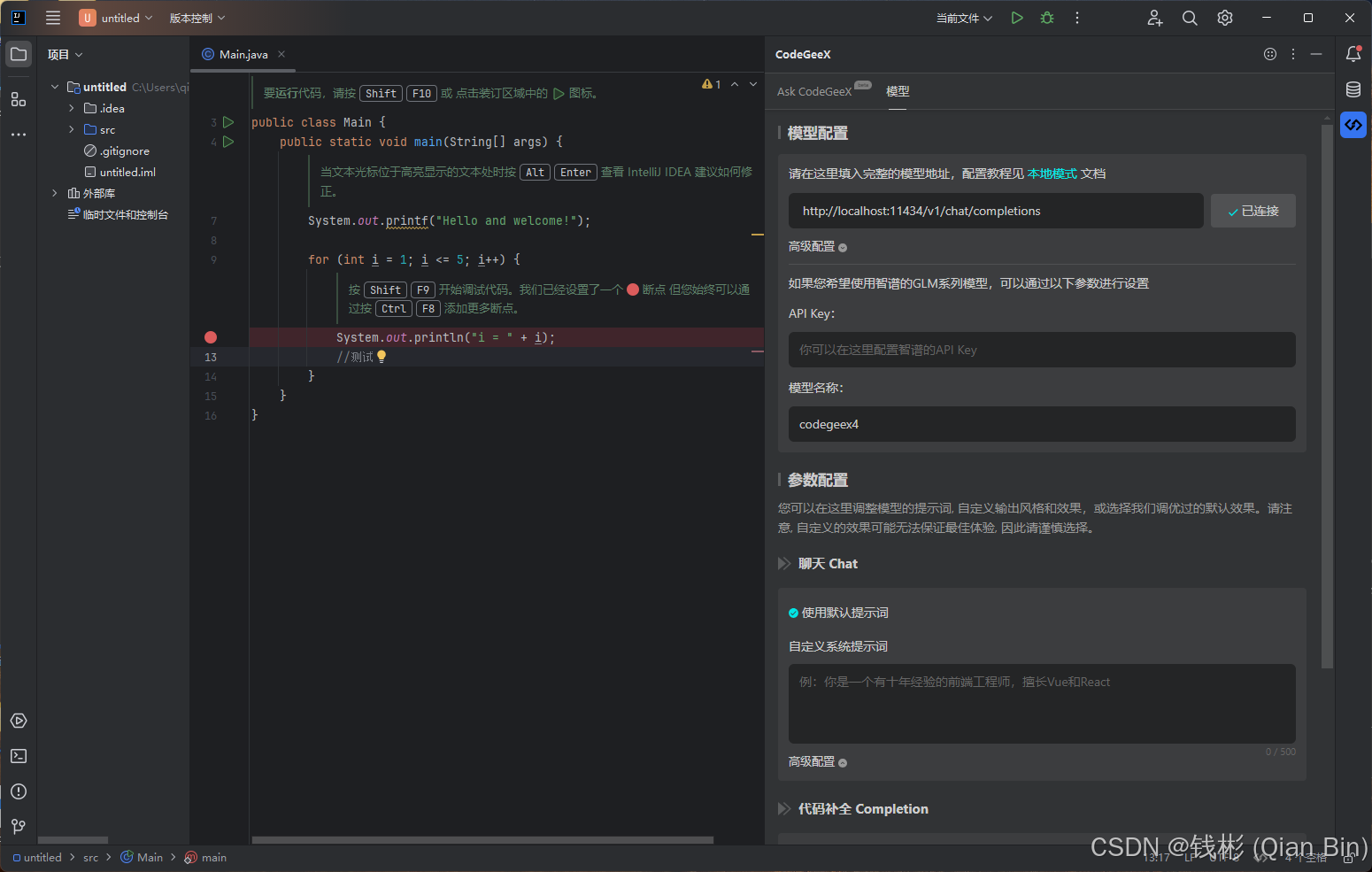
在CodeGeeX插件的本地模式设置中,输入模型地址:
http://localhost:11434/v1/chat/completions上述路径需要根据实际GPU服务器IP地址修改localhost。
打开模型配置的高级模式,在模型名称栏填写:
codegeex4单击“连接”按钮,显示已连接即可,如下图所示:
此时,即使关闭客户机的互联网连接,也是可以辅助编程了。


















 551
551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











