






在人工智能(Artificial Intelligence, AI)的迅猛发展浪潮中,对计算能力的需求呈现出爆炸性增长,这一趋势迫切呼唤着更为强大的硬件解决方案。在这样的背景下,图形处理单元(Graphics Processing Units, GPUs)与张量处理单元(Tensor Processing Units, TPUs)异军突起,成为满足这些需求的关键技术力量。
最初,GPU的设计宗旨在于图形的渲染,但随着技术的进步,它们已经转变成能够高效执行AI任务的多功能处理器。这主要归功于它们卓越的并行处理能力。与GPU不同,TPUs是由Google特别针对AI计算优化开发的,它们为机器学习项目等AI密集型任务提供了无与伦比的性能。
在本文中,我们将深入探讨GPU与TPU的对比,并从性能、成本、生态系统等多个维度对这两种技术进行详尽的比较分析。此外,我们还将涉及它们的能源效率、对环境的影响,以及在企业级应用中的可扩展性。
GPU的内涵
GPU最初是为计算机和游戏机中的图像和图形渲染而设计的专用处理器。它们通过将复杂问题分解为多个并行处理的任务,而不是像中央处理单元(Central Processing Unit, CPU)那样顺序处理,从而实现了计算的革命。
得益于其并行处理的能力,GPU的应用已经远远超出了图形处理的范畴,成为AI模型开发等众多计算应用中的核心组件。
让我们回溯一下历史。GPU在20世纪80年代首次出现,作为加速图形渲染的专用硬件。NVIDIA和ATI(现属于AMD)等公司在GPU的发展中扮演了关键角色。然而,直到90年代末和21世纪初,随着可编程着色器的引入,GPU才真正开始在主流市场崭露头角,这使得开发者能够利用其并行处理能力来处理图形之外的任务。
进入21世纪,越来越多的研究开始探索GPU在图形之外的通用计算任务。NVIDIA推出的CUDA(Compute Unified Device Architecture)和AMD的Stream SDK,使得开发者能够利用GPU的强大处理能力进行科学模拟、数据分析等更广泛的应用。
随后,AI和深度学习的兴起为GPU带来了新的机遇。GPU以其处理大量数据和并行执行计算的能力,成为了训练和部署深度学习模型的关键工具。
诸如TensorFlow和PyTorch等深度学习框架,通过利用GPU加速,使得深度学习技术对全球的研究人员和开发人员变得更加可及。
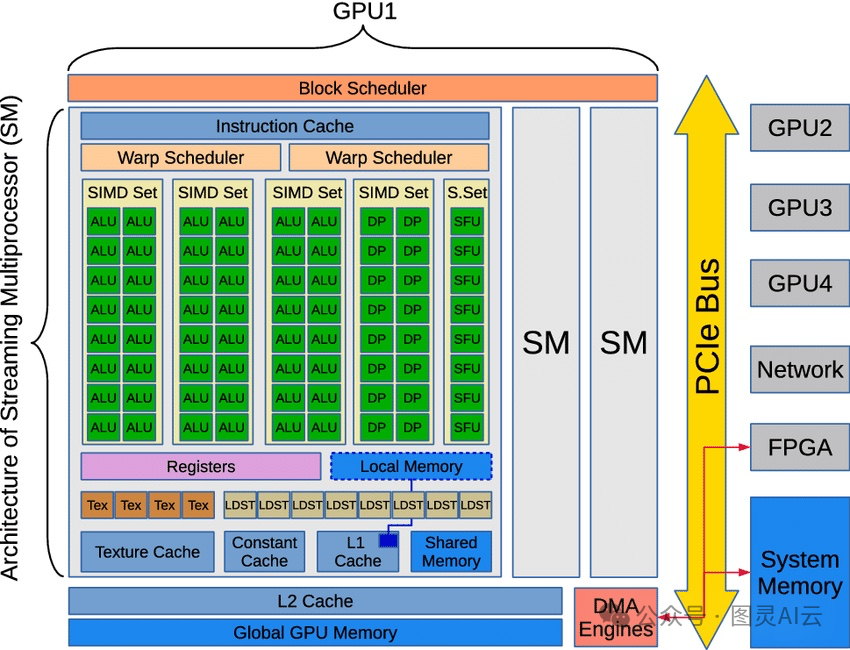
典型GPU架构
上图是GPU架构的通用方案。一个典型的GPU包括DMA引擎、全局GPU内存、L2缓存和多个流式多处理器(SM)。集成的DMA引擎主要用于通过PCIe总线在GPU和系统内存之间交换数据,但也可以用来与PCIe总线上的其他设备进行通信(右侧)。每个SM包括几种类型的缓存和计算单元(左侧)。
TPU的内涵
张量处理单元(TPUs)是谷歌为应对机器学习领域日益增长的计算需求而开创的一种特定于应用的集成电路(Application-Specific Integrated Circuit, ASIC)。与最初为图形处理任务设计、后来被改造以适应AI需求的GPU不同,TPU从一开始就是为了加速机器学习工作负载而设计的。
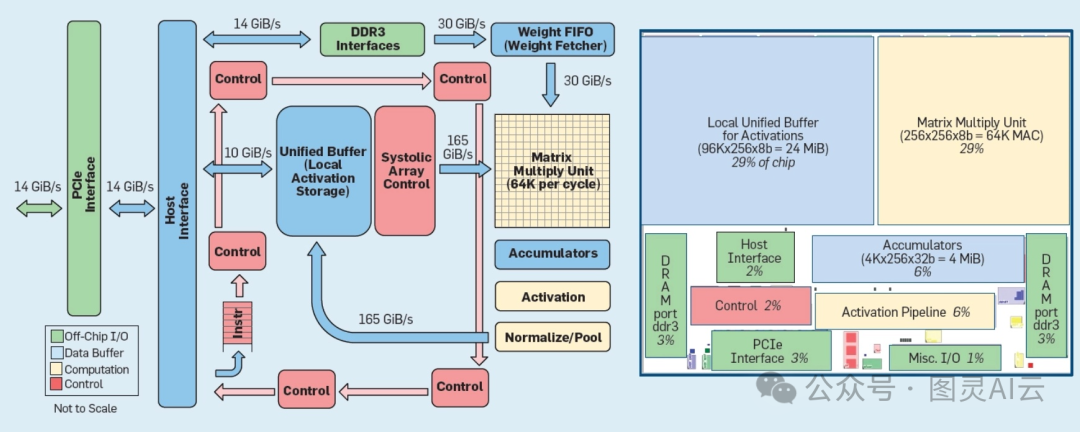
TPU架构图
如TPU架构图所示,主要的计算是黄色的矩阵乘法单元。它的输入是蓝色的权重FIFO(先进先出队列)和蓝色的统一缓冲区,输出是蓝色的累加器。黄色的激活单元执行非线性函数。右侧的芯片平面图显示,蓝色内存占35%,计算部分也占35%,绿色I/O占10%,红色控制仅占芯片的2%。谷歌表示,在CPU或GPU中,控制部分要大得多,设计起来也更加困难。
TPU的设计专注于张量操作,这是深度学习算法的基础。由于其定制架构针对矩阵乘法进行了优化——这是神经网络中的关键操作,TPU在处理大量数据和高效执行复杂神经网络方面表现出色,实现了快速的训练和推理时间。
这种专门的优化使得TPU在AI应用中变得不可或缺,它推动了机器学习研究和部署的进步。
TPU与GPU:性能的较量
TPU和GPU各自提供了独特的优势,并且针对不同的计算任务进行了优化。尽管两者都能够加速机器学习的工作负载,但它们的架构和优化导致了在特定任务上的性能差异。
计算架构的对比
GPU和TPU都是为提升AI任务性能而专门设计的硬件加速器,但它们在计算架构上的差异显著影响了它们处理特定类型计算的效率和效果。
GPU的架构
GPU由数千个小而高效的内核构成,这些内核专为并行处理而设计。这种架构使得GPU能够同时执行多个任务,特别适合于可以并行化的任务,如图形渲染和深度学习。
GPU在矩阵操作方面尤为出色,这在神经网络计算中非常常见。它们能够处理大量数据并并行执行计算,这使得GPU非常适合处理大型数据集和执行复杂数学运算的AI任务。
TPU的架构
与GPU相比,TPU更注重张量操作,这使得它们能够高效地执行计算。尽管TPU可能没有GPU那么多的内核,但它们的专门架构使它们在某些类型的AI任务中能够超越GPU,尤其是那些严重依赖张量操作的任务。
尽管如此,GPU在从AI到图形渲染和科学模拟等各种计算任务中都表现出色。另一方面,TPU针对张量处理进行了优化,使它们在涉及矩阵操作的深度学习任务中非常高效。根据AI工作负载的具体要求,GPU或TPU可能提供更好的性能和效率。
性能的展现:速度与效率
GPU以其处理各种AI任务的多功能性而闻名,包括训练深度学习模型和执行推理操作。这是因为依赖于并行处理的GPU架构,在众多AI模型的训练和推理速度上显著提升。例如,在V100 GPU上处理128个序列的BERT模型需要3.8毫秒,而在TPU v3上只需要1.7毫秒。
相反,TPU为快速高效的张量操作进行了微调,这是神经网络的关键组成部分。这种专业化通常允许TPU在特定深度学习任务中胜过GPU,尤其是那些由谷歌优化的任务,如广泛的神经网络训练和复杂的机器学习模型。
基准测试
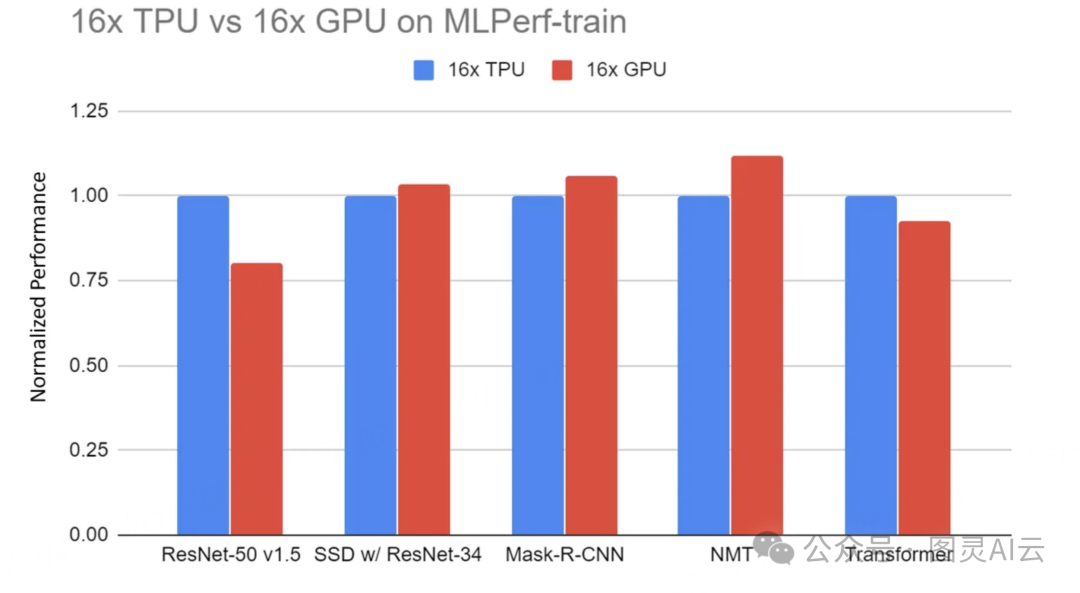
16x GPU服务器(DGX-2H)与16x TPU v3服务器在MLPerf-train基准测试中的归一化性能。所有TPU结果都使用TensorFlow。所有GPU结果都使用PyTorch,除了ResNet使用MxNet。
在AI领域的任务执行上,TPU与GPU的性能对比往往揭示了TPU在为其定制化架构量身打造的任务中的优势,它们提供了更迅捷的训练周期和更优的处理效率。
以一个具体的例子来说明,当利用NVIDIA Tesla V100 GPU在CIFAR-10数据集上对ResNet-50模型进行10个周期的训练时,整个过程大约需要40分钟,平均每个周期耗时4分钟。而如果使用谷歌云上的TPU v3,同样的训练任务可以缩短至15分钟,每个周期平均仅需1.5分钟。
尽管GPU在广泛的应用场景中因其出色的适应性和社区贡献的大量优化而保持竞争力,但在特定任务上,TPU的性能优势不容忽视。
GPU与TPU:成本效益与可获取性分析
在预算、计算需求和资源可获取性的考量下,GPU和TPU的选择呈现出不同的优势。以下是对这两种硬件在成本和市场可获取性方面的深入比较。
硬件成本考量
相较于TPU,GPU在成本上展现出更大的灵活性。TPU并不单独出售,而是通过云服务提供商如Google Cloud Platform (GCP)提供。相对地,GPU则可以被单独购买。
NVIDIA Tesla V100 GPU的大致成本介于8,000至10,000美元之间,而NVIDIA A100 GPU的价格则在10,000至15,000美元的区间。除了直接购买,GPU还提供了基于需求的云服务计费模式。
在云服务计费方面,使用NVIDIA Tesla V100 GPU进行深度学习模型训练的成本大约是每小时2.48美元,而NVIDIA A100则约为每小时2.93美元。相比之下,谷歌云TPU V3的费用大约是每小时4.50美元,而TPU V4则大约需要8.00美元每小时。
换言之,虽然TPU在按需云计算方面的小时成本通常高于GPU,但它们提供的高性能可以减少大规模机器学习任务所需的总计算时间,这可能在总体上实现成本节约,即便小时费率较高。
市场可获取性探讨
TPU和GPU在市场上的可获取性存在显著差异,这影响了它们在不同行业和地区的普及程度。
由谷歌开发的TPU主要通过GCP提供,用于基于云的AI任务。这使得TPU在依赖GCP进行计算需求的人群中更受欢迎,尤其是在云计算领域,如技术中心或互联网连接发达的地区。
与此同时,GPU由NVIDIA、AMD和Intel等公司制造,为市场提供了广泛的选择。这种广泛的可获取性使得GPU成为包括游戏、科学、金融、医疗保健和制造业在内的多个行业的热门选择。GPU既可以在现场部署,也可以在云环境中使用,为用户提供了在计算设置上的灵活性。
因此,无论技术基础设施或计算需求如何,GPU都有可能在不同的行业和地区得到应用。总的来说,TPU和GPU的市场可获取性对它们的普及有着显著的影响。TPU在以云为中心的领域和部门(例如机器学习)更为常见,而GPU则在各个领域和地区都有广泛的应用。
生态系统与开发工具的深度融合
软件和库的整合
谷歌的TPU与TensorFlow紧密集成,后者是其领先的开源机器学习框架。JAX作为另一个高性能数值计算库,同样支持TPU,使得机器学习和科学计算更为高效。
TPU与TensorFlow生态系统的无缝集成,使得TensorFlow用户能够轻松地利用TPU的强大功能。例如,TensorFlow提供了TensorFlow XLA(加速线性代数)编译器等工具,为TPU优化了计算性能。
本质上,TPU的设计旨在加速TensorFlow的操作,为训练和推理提供了优化的性能。它们还支持TensorFlow的高级API,使得模型迁移和优化以在TPU上执行变得更加容易。
与此相比,GPU在多个行业和研究领域得到了广泛应用,成为多样化机器学习应用的热门选择。这意味着GPU拥有比TPU更广泛的集成,并得到了包括TensorFlow、PyTorch、Keras、MXNet和Caffe在内的广泛深度学习框架的支持。
GPU还受益于CUDA、cuDNN和RAPIDS等广泛的库和工具,这些进一步增强了它们的多功能性,并易于集成到各种机器学习和数据科学工作流程中。
社区支持与资源的丰富性
在社区支持方面,GPU拥有一个更广泛的生态系统,提供来自NVIDIA、AMD和社区驱动平台的广泛论坛、教程和文档。开发人员可以访问活跃的在线社区、论坛和用户组,以寻求帮助、分享知识和合作项目。此外,还有许多教程、课程和文档资源覆盖了GPU编程、深度学习框架和优化技术。
TPU的社区支持则更集中在谷歌的生态系统周围,资源主要通过GCP文档、论坛和支持渠道获得。尽管谷歌为使用TensorFlow的TPU提供了全面且量身定制的文档和教程,但社区支持可能比更广泛的GPU生态系统更为有限。然而,谷歌的官方支持渠道和开发人员资源仍然为使用TPU进行AI工作负载的开发人员提供了宝贵的帮助。
能效与环境影响的考量
功耗的比较
GPU和TPU的能效根据它们的架构和预期应用而异。通常,TPU比GPU更节能,尤其是谷歌云TPU v3,其功耗比高端NVIDIA GPU显著更低。
为了提供更多背景信息:
-
NVIDIA Tesla V100:每张卡消耗约250瓦特。
-
NVIDIA A100:每张卡消耗约400瓦特。
-
谷歌云TPU v3:每个芯片消耗约120-150瓦特。
-
谷歌云TPU v4:每个芯片消耗约200-250瓦特。
TPU的低功耗可以带来更低的运营成本和更高的能效,特别是在大规模机器学习部署中。
针对AI任务的优化
TPU和GPU都采用了特定的优化措施来提高执行大规模AI操作时的能效。
如前文所述,TPU架构旨在优先考虑在神经网络中常用的张量操作,允许以最小的能耗高效执行AI任务。TPU还具有针对AI计算优化的定制内存层次结构,减少内存访问延迟和能源开销。
它们利用量化和稀疏性等技术优化算术操作,最大限度地减少功耗,而不牺牲准确性。这些因素使TPU能够在节省能源的同时提供高性能。
同样,GPU实施节能优化以提高AI操作的性能。现代GPU架构包括功率门控和动态电压频率缩放(DVFS)等功能,以根据工作负载需求调整功耗。它们还利用并行处理技术将计算任务分配给多个内核,最大限度地提高吞吐量,同时最小化每操作的能源消耗。
GPU制造商开发节能内存架构和缓存层次结构,优化内存访问模式,减少数据传输期间的能源消耗。这些优化,结合内核融合和循环展开等软件技术,进一步提高了GPU加速AI工作负载的能效。
企业级应用的可扩展性
在企业级应用中扩展人工智能项目是实现技术进步的关键。GPU和TPU均提供了强大的可扩展性,以适应大型AI项目的需求,尽管它们在实现这一目标的途径上存在差异。
TPU的云集成可扩展性
TPU与云基础设施的紧密结合,尤其是通过 GCP,为用户提供了一种可扩展的资源,以应对AI工作负载。这种架构允许用户根据需求灵活地扩展TPU资源,这对于处理大规模AI项目至关重要。谷歌提供的托管服务和预配置环境进一步简化了将AI模型部署到TPU的过程,使得集成到云基础设施变得更加高效。
GPU的灵活可扩展性
另一方面,GPU在可扩展性方面展现了其灵活性,无论是在本地部署还是在亚马逊 AWS和微软Azure等云环境中。GPU的并行处理能力和高内存带宽使其在处理大型数据集和模型训练方面表现出色,这对于大型AI项目的成功至关重要。
GPU与TPU概览
以下是GPU和TPU在关键特性上的对比概览:
| 特性 | GPUs | TPUs |
|---|---|---|
| 计算架构 | 成千上万个小而高效的内核,专为并行处理设计 | 专注于张量操作,具有专门优化的架构 |
| 性能 | 多功能性,擅长执行包括深度学习和推理在内的各种AI任务 | 针对张量操作优化,通常在特定深度学习任务上超越GPU |
| 速度和效率 | 例如,使用BERT模型处理128个序列:在V100 GPU上需3.8毫秒 | 例如,使用BERT模型处理128个序列:在TPU v3上只需1.7毫秒 |
| 基准测试 | 在CIFAR-10上,ResNet-50进行10个周期:在Tesla V100 GPU上需40分钟(每个周期4分钟) | 在CIFAR-10上,ResNet-50进行10个周期:在Google Cloud TPU v3上需15分钟(每个周期1.5分钟) |
| 成本 | NVIDIA Tesla V100:10,000/单元,小时;:10,000 - 单元,2.93/小时 | Google Cloud TPU v3:小时;:8.00/小时 |
| 可用性 | 广泛可从多个供应商(NVIDIA, AMD, Intel)获得,适用于消费者和企业 | 主要通过Google Cloud Platform (GCP)获得 |
| 生态系统和开发工具 | 支持多个框架(TensorFlow, PyTorch, Keras, MXNet, Caffe),拥有广泛的库(CUDA, cuDNN, RAPIDS) | 与TensorFlow紧密集成,支持JAX,由TensorFlow XLA编译器优化 |
| 社区支持和资源 | 拥有广泛的生态系统,包括来自NVIDIA, AMD和社区的论坛、教程和文档 | 围绕Google的生态系统,提供GCP文档、论坛和支持渠道 |
| 能效 | NVIDIA Tesla V100:250瓦特;NVIDIA A100:400瓦特 | Google Cloud TPU v3:120-150瓦特;TPU v4:200-250瓦特 |
| AI任务优化 | 采用节能优化技术(电源门控,DVFS,并行处理,内核融合) | 定制内存层次结构,量化和稀疏性,以实现高效的AI计算 |
| 企业应用中的可扩展性 | 适用于大型AI项目,可在现场或云环境(AWS, Azure)中扩展,具有高内存带宽和并行处理能力 | 与云基础设施(GCP)紧密集成,提供按需可扩展性,以及用于部署AI模型的管理服务 |
推荐选择
选择GPU的情况包括:
-
项目需要TensorFlow之外的广泛框架支持,如PyTorch、MXNet或Keras。
-
需要包括机器学习、科学计算和图形渲染在内的多功能计算能力。
-
倾向于具有高度可定制优化选项和对性能调整的详细控制。
-
在本地、数据中心和云环境之间的部署灵活性至关重要。
选择TPU的情况包括:
-
项目主要基于TensorFlow,并且能够从与TensorFlow紧密集成的优化性能中受益。
-
高吞吐量的训练和快速的推理时间至关重要,例如在大规模深度学习模型训练或实时应用中。
-
能效和降低功耗是重要的考虑因素,特别是在大规模部署中。
-
倾向于一个管理良好的云服务,具有无缝的可扩展性,并且可以轻松访问Google Cloud中的TPU资源。
结论
GPU和TPU作为AI应用的专用硬件加速器,各自具有独特的优势。GPU最初为图形渲染而开发,现已成为并行处理的佼佼者,适用于多种行业的AI任务。而TPU则是谷歌为AI工作负载特别定制的,它们在处理神经网络中常见的张量操作方面表现出色。
本文通过性能、成本和可用性、生态系统和开发工具、能效和环境影响以及AI应用中的可扩展性等多个维度,对GPU和TPU技术进行了全面的比较。这种比较有助于用户根据自身的需求和偏好,做出更合适的技术选择。


















 950
950

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









