







一、举例的数据
假设我有个六列的dataframe:一列是销售员,一列是所属团队,其它四列分别是四个季度的销售额。
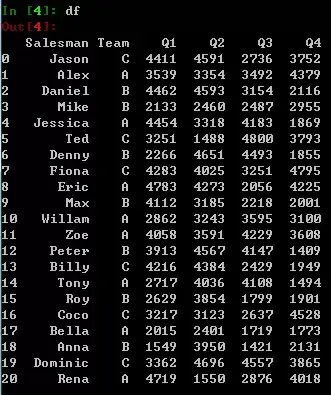
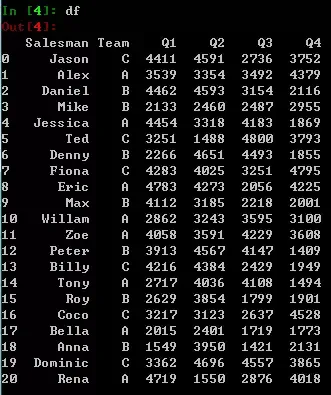
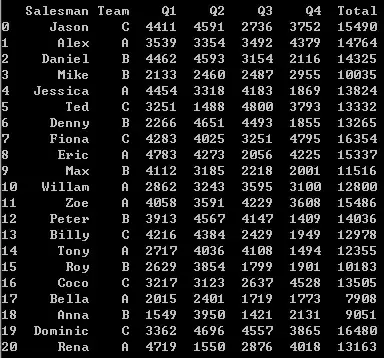
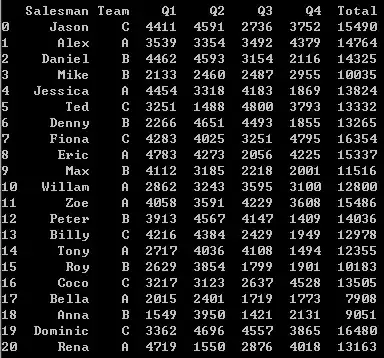
1新增列-基于原有列的全年销售额
首先df['Total ']确保了你在该df内新增了一个column,然后累加便可。
df['Total'] = df['Q1']+df['Q2']+df['Q3']+df['Q4']
你可能想使用诸如sum()的函数进行这步,很可惜,sum()方法只能对列进行求和,幸好它可以帮我们求出某季度的总销售额。df['Q1'].sum(),你就能得到一个Q1的总销售额,除此之外,其他的聚合函数,max,min,mean都是可行的。
2分组统计 - 团队竞赛
那么按团队进行统计呢?在mysql里是group by,Pandas里也不例外,你只需要df.groupby('Team').sum()就能看到期望的答案了。
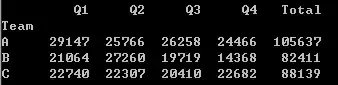
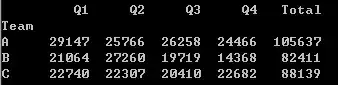
3排序 - 谁是销售冠军
如果你关心谁的全年销售额最多,那么就要求助于sort_values方法了,在excel内是右键筛选,SQL内是一个orderby。默认是顺序排列的,所以要人为设定为False,如果你只想看第一名,只需要在该语句末尾添加.head(1) 。
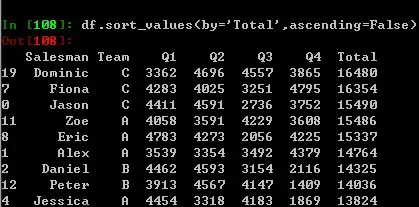
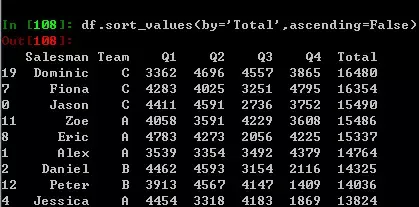
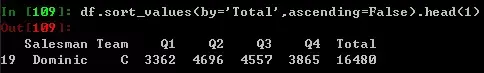
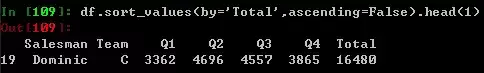
4切片-只给我看我关心的行
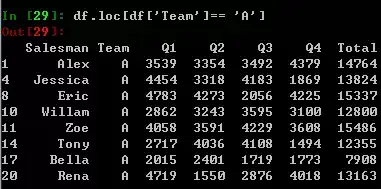
接下来就是涉及一些条件值的问题,例如我只关心Team为A的数据,在Excel里是筛选框操作,在SQL里写个where就能搞定,在Pandas里需要做切片。
查看Pandas文档时,你可能已经见过各种切片的函数了,有loc,iloc,ix,iy,这里不会像教科书一样所有都讲一通让读者搞混。这种根据列值选取行数据的查询操作,推荐使用loc方法。
df.loc[df['Team']== 'A',['Salesman', 'Team','Year']],这里用SQL语法理解更方便,loc内部逗号前面可以理解为where,逗号后可以理解为select的字段。
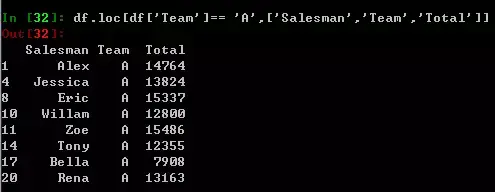

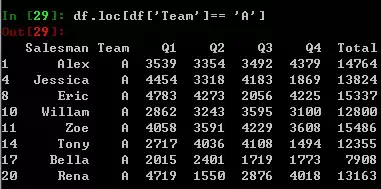
如果想全选出,那么只需将逗号连带后面的东西删除作为缺省,即可达到select *的效果。
5切片 - 多条件筛选
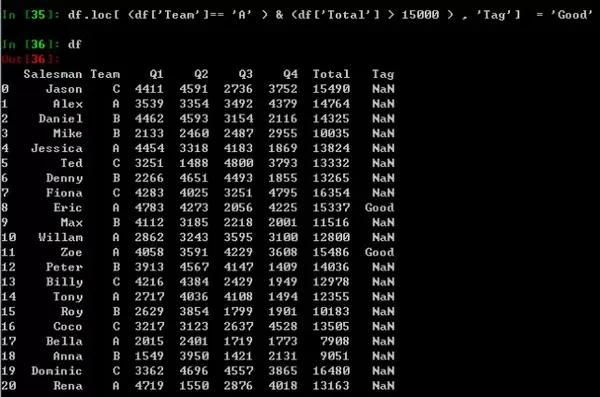
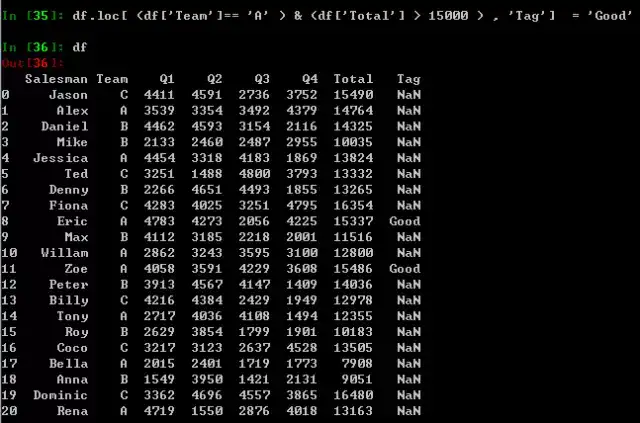
在Pandas中多条件切片的写法会有些繁琐,df.loc[ (df['Team']== 'A' ) & (df['Total'] > 15000 ) ],添加括号与条件


这里有一个有意思的小应用,如果你想给符合某些条件的员工打上优秀的标签,你就可以结合上述新增列和切片两点,进行条件赋值操作。
df.loc[ (df['Team']== 'A' ) & (df['Total'] > 15000 ) , 'Tag'] = 'Good'
6删除列 - 和查询无关,但是很有用
当然这里只是个举例,这时候我想删除Tag列,可以del df['Tag'],又回到了之前。
二、连接
接下来要讲join了,现在有每小时销售员的职位对应表pos,分为Junior和Senior,要将他们按对应关系查到df中。
这里需要认识一下新朋友,merge方法,将两张表作为前两个输入,再定义连接方式和对应键。对应到Excel中是Vlookup,SQL中就是join。在pandas里的连接十分简单。
df = pd.merge(df, pos, how='inner', on='Salesman')
注意,这个时候其实我们是得到了新的df,如果不想覆盖掉原有的df,你可以在等号左边对结果重新命名。
这时候有了两组标签列(对应数值列),就可以进行多重groupby了。
当然这样的结果并不能公平地反应出哪一组更好,因为每组的组员人数不同,可能有平均数的参与会显得更合理,并且我们只想依据全年综合来评价。
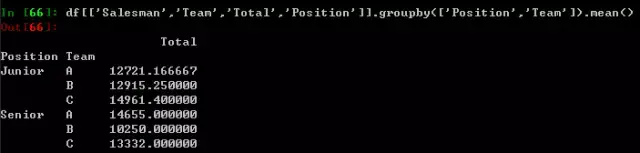

这里的数据是捏造的,不过也一目了然了。
三、合并操作
最后以最简单的一个合并操作收尾。
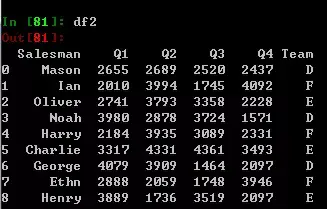
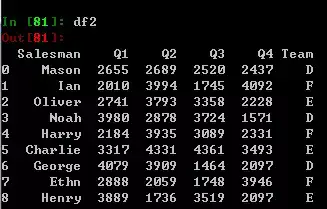
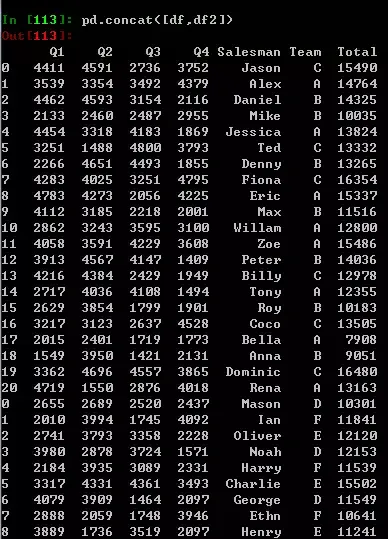
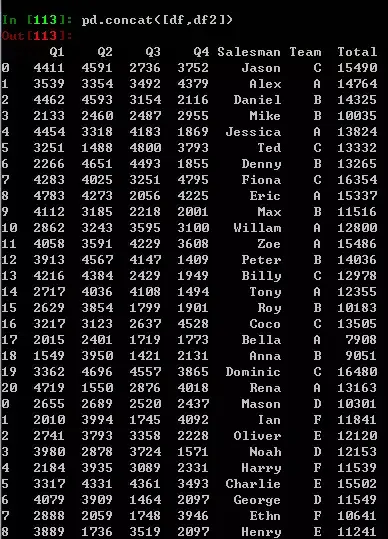
如果我又有一批数据df2,需要将两部分数据合并。只需要使用concat方法,然后传一个列表作为参数即可。不过前提是必须要保证他们具有相同类型的列,即使他们结构可能不同(df2的Team列在末尾,也不会影响concat结果,因为pandas具有自动对齐的功能)。
pd.concat([df,df2])
转自: https://www.zhihu.com/question/56310477/answer/277000149















 6527
6527

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









