






摘要:本文主要介绍了朴素贝叶斯分类的基本原理以及两个实现,实现包括文本的分类和图像的分类
- 原理
- 实现
1.模型概述
朴素贝叶斯
朴素:特征独立
贝叶斯:基于贝叶斯定理
根据贝叶斯定理,对一个分类问题,给定样本特征x,样本属于类别y的概率是
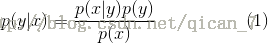
在这里,x是一个特征向量,将设x维度为M。因为朴素的假设,即特征条件独立,根据全概率公式展开,公式(1)
可以表达为
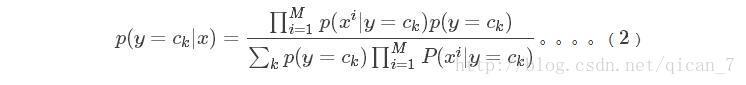
这里,只要分别估计出,特征
xi
在每一类的条件概率就可以了。类别y的先验概率可以通过训练集算出,同样通过
训练集上的统计,可以得出对应每一类上的,条件独立的特征对应的条件概率向量。 由于分母中为全概率
可视为常数,
实际可不计算。
2.拉普拉斯平滑
如果从样本中算出的概率值为0该怎么办呢?下面介绍一种简单方法,给学习步骤中的两个概率计算公式,分子和
分母都分别加上一个常数,就可以避免这个问题。更新过后的公式如下:
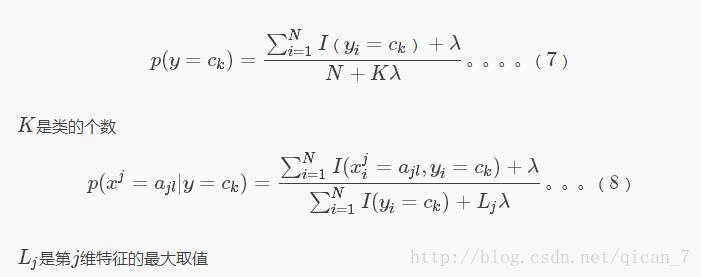

3.实现1(朴素贝叶斯下的文本分类)(参http://blog.csdn.net/tanhongguang1/article/details/45016421)
朴素贝叶斯最典型的应用就是文本分类,训练集中包括侮辱性/非侮辱性两类,将句子中的单词视为特征,单个
词语有极性表征,整个句子所包含的单词的极性表征就是句子的极性。算法步骤如下:
实现代码参考
http://blog.csdn.net/tanhongguang1/article/details/45016421
,经测试有效,由于训练数据较少,代码运行速度很快,基本分类正确。
,经测试有效,由于训练数据较少,代码运行速度很快,基本分类正确。
# -*- coding:utf-8 -*-
# __author__ = 'Administrator'
import numpy as np
def loadDataSet():#数据格式
postingList = []
for line in open("data.txt"):
postingList.append(line.split())
print(postingList)
'''postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]'''
classVec = [0,1,0,1,0,1]#1 侮辱性文字 , 0 代表正常言论
return postingList,classVec
def createVocabList(dataSet):#创建词汇表
vocabSet = set([])
for document in dataSet:
vocabSet = vocabSet | set(document) #创建并集
return list(vocabSet)
def bagOfWord2VecMN(vocabList,inputSet):#根据词汇表,讲句子转化为向量
returnVec = [0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] += 1
return returnVec
def trainNB0(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix) #向量的个数
numWords = len(trainMatrix[0]) #总共32个词
pAbusive = sum(trainCategory)/float(numTrainDocs) #Category = 1 所占比例(先验概率)
p0Num = np.ones(numWords); p1Num = np.ones(numWords)#计算频数初始化为1
p0Denom = 2.0; p1Denom = 2.0 #即拉普拉斯平滑
for i in range(numTrainDocs):
if trainCategory[i] == 1:
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else:
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = np.log(p1Num/p1Denom)#注意 计算单词出现的概率 分母是这一类所有词的个数
p0Vect = np.log(p0Num/p0Denom)#注意
return p0Vect,p1Vect,pAbusive#返回各类对应特征的条件概率向量
#和各类的先验概率
def classifyNB(vec2Classify,p0Vec,p1Vec,pClass1):
p1 = sum(vec2Classify * p1Vec) + np.log(pClass1)#注意
p0 = sum(vec2Classify * p0Vec) + np.log(1-pClass1)#注意
if p1 > p0:
return 1
else:
return 0
def testingNB():#流程展示
listOPosts,listClasses = loadDataSet()#加载数据
myVocabList = createVocabList(listOPosts)#建立词汇表
trainMat = []
for postinDoc in listOPosts:
trainMat.append(bagOfWord2VecMN(myVocabList,postinDoc))
p0V,p1V,pAb = trainNB0(trainMat,listClasses)#训练
#测试
#testEntry = ['love','my','dalmation','dog','stupid']
testEntry = ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid']
thisDoc = bagOfWord2VecMN(myVocabList,testEntry)
print( testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb))
testingNB() data.txt
my dog has flea problems help please
maybe not take him to dog park stupid
my dalmation is so cute I love him
stop posting stupid worthless garbage
mr licks ate my steak how to stop him
quit buying worthless dog food stupid
data.txtmy dog has flea problems help please
maybe not take him to dog park stupid
my dalmation is so cute I love him
stop posting stupid worthless garbage
mr licks ate my steak how to stop him
quit buying worthless dog food stupid4.实现2(朴素贝叶斯下的图像分类)
将朴素贝叶斯应用到图像分类,以图像灰度化后的像素灰度值作为特征进行训练,统计图像灰度化后的灰度值,存储到1*256
的数组中,最终实现效果并不是很好,经常会有分类错误的情况,出现这一结果的可能原因有两方面。其一,图像灰度化后的像素值并不能很好的表征图像的特征,容易受背景 的干扰,图像本身比较复杂,统计值容易模糊图像的特征,另一方面,仅仅是灰度值这一特征过于单一,如果要达到更好的效果,可以提取更多有效的特征。
# -*- coding:utf-8 -*-
# __author__ = 'Administrator'
import matplotlib.pyplot as plt # plt 用于显示图片
import matplotlib.image as mpimg # mpimg 用于读取图片
import numpy as np
from scipy import misc
from PIL import Image
def rgb2gray(rgb): #彩色图像灰度化
return np.dot(rgb[...,:3], [0.299, 0.587, 0.114])
for i in range(1,100):
img1 = Image.open('cat/' + str(i) + '.jpg')
img2 = Image.open('dog/' + str(i) + '.jpg')
img3 = Image.open('beautyGril/' + str(i) + '.jpg')
img1 = img1.resize((100, 100)) # 缩放为30*30
img2 = img2.resize((100, 100)) # 缩放为30*30
img3 = img3.resize((100, 100)) # 缩放为30*30
img1 = np.array(img1)
img2 = np.array(img2)
img3 = np.array(img3)
if img1.ndim == 3:
img1 = rgb2gray(img1)
if img2.ndim == 3:
img2 = rgb2gray(img2)
if img3.ndim == 3:
img3 = rgb2gray(img3)
Vec1 = np.ones(256)
Vec2 = np.ones(256)
Vec3 = np.ones(256)
p1Denom = 2
p2Denom = 2
p3Denom = 2
for i in range(0,99):
for j in range(0,99):
Vec1[int(img1[i, j])] += 1
Vec2[int(img2[i, j])] += 1
Vec3[int(img3[i, j])] += 1
p1Denom += 1
p2Denom += 1
p3Denom += 1
p1Vect = np.log(Vec1/p1Denom)
p2Vect = np.log(Vec2/p2Denom)
p3Vect = np.log(Vec3/p3Denom)
pAbusive1 = 1/3
pAbusive2 = 1/3
pAbusive3 = 1/3
testImg = Image.open('dog/' + str(2) + '.jpg')
# testImg = Image.open('beautyGril/' + str(2) + '.jpg')
testImg = testImg.resize((100,100)) # 缩放为30*30
testImg = np.array(testImg)
if testImg.ndim == 3:
testImg = rgb2gray(testImg)
testVec = np.ones(256)
for i in range(0,99):
for j in range(0,99):
testVec[int(testImg[i, j])] += 1
p0 = sum(testVec * p1Vect) + np.log(pAbusive1)#注意
p1 = sum(testVec * p2Vect) + np.log(pAbusive2)#注意
p2 = sum(testVec * p3Vect) + np.log(pAbusive3)#注意
print('p0:',p0, 'p1:',p1, 'p2:',p2, )
if p0 >= p1 and p0 >= p2:
print('cat')
elif p1 >= p0 and p1 >= p2:
print('dog')
elif p2 >= p0 and p2 >= p1:
print('beautyGril')















 2596
2596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









