







第1章 绪论
ps:为避免篇幅过长,书中比较简单、基础的一些定义,如“数据集”、“样本”等,在这里将不进行记载~
- 属性形成的空间称为“属性空间(attribute)”或“样本空间”
直观一点解释:如下图中三条轴表示一组样本的三种属性,若某样本对应三种属性的属性值为a,b,c,由此构成的向量V(a; b; c)也可代表这个样本,故样本又称“特征向量(featrue vector)”
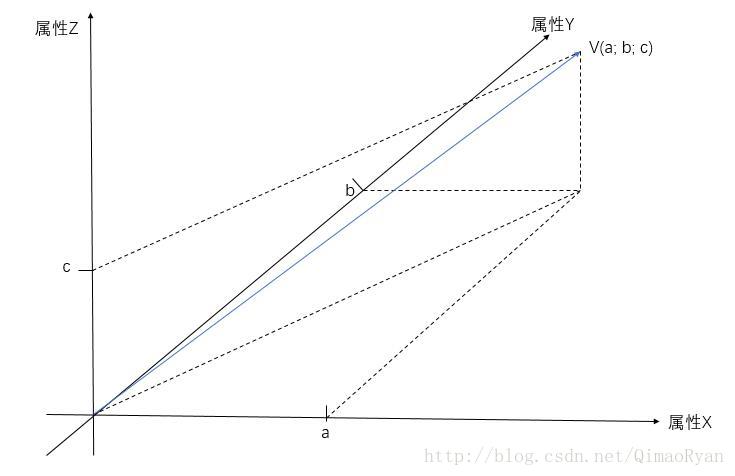
(阔怜的小博主木有啥画图软件,这个图是用PPT画出来的(吐血),所以可能轴不垂直啥的,欢迎强迫症患者大大们提供更好的图,蟹蟹!)
- 让机器“学习”的过程称为“训练(training)”或“学习”
- 用于训练的原始数据集称为“训练集”,训练集中的样本称为“训练样本(training sample)”
- 学习过程中用的算法称为“学习算法(learninng algorithm)”
- 机器通过使用学习算法对训练样本进行学习,进而得到的关于样本规律的总结,称为“假设(hypothesis)”或“模型”
- 得到假设后,并不意味着机器已经能较好地对未知样本进行判断,需要用另外的已知的样本对机器的假设进行验证,验证其是否达到我们的要求(即能较好地对未知样本进行判断),对假设进行验证的过程称为“测试(testing)“,测试所用的那些已知的样本称为“测试样本(testing sample)”
以上的一些定义我用容易理解的方式解释一下:
最初,机器就好比一个小婴儿,机器学习的过程(训练)就好比是我们引导婴儿学习新鲜事物的过程,例如我们引导婴儿学会分辨狮子和老虎(假设婴儿从未接触过狮子、老虎),我们给他一些狮子和老虎的图片(训练样本),教他脖子周围有鬃毛的是(雄)狮子,头上有“王”的是老虎(学习算法),之后婴儿大概就懂了狮子和老虎的不同特征(假设/模型)并能判断出自己认为正确的狮子和老虎。之后,我们再给婴儿另外一些狮子和老虎的图片(测试样本),让他自己分辨(测试)。
ps:我们想要达到的目的大概就是婴儿能以较高成功率地分辨狮子和老虎并告诉我们一张(组)新的图片上是狮子or老虎(之前的图片是我们看过并已经分辨出狮子和老虎的,新的图片则不需要我们分辨甚至不需要我们去看,而是直接给婴儿分辨告诉我们结果)
(可能这个例子不是百分百准确,但是建立对概念的理解还是没问题的哈~)
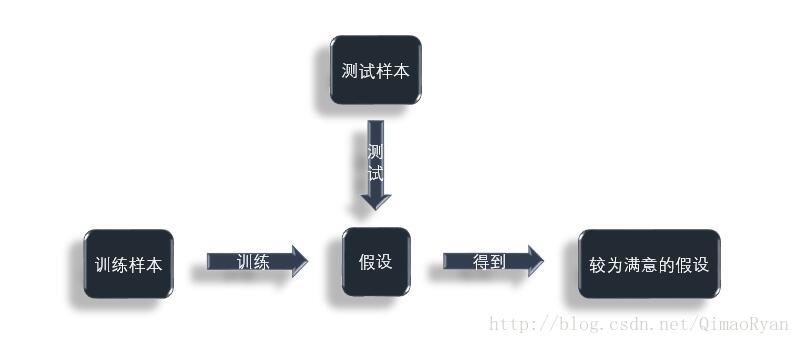
(同PPT绘制(逃))
关于样本的结果信息称为“标记(label)”,所有样本的标记的集合称为“标记空间”
ps:标记就相当于问题的答案,如上例中一张图片上的是狮子(or老虎)有标记的样本称为“样例(example)”
ps:样例 = 样本 + 标记 (这里的等号是“等于”的意思,不是赋值,hhh)样例可理解为一道已给出答案的题目(例题)
若预测的是离散值,此类学习任务称为“分类(classification)”
- 对只涉及两个类别的“二分类(binary classification)任务”,通常称其中一个类为“正类(positive class)“,另一个类为“反类(negative class)”
- 涉及多个类别时,则称为“多分类(multi-class classification)任务”
若预测的是连续值,此类学习任务称为“回归(regression)”
- 训练样本内部之间可能存在某种潜在的概念划分,故可根据这种划分将样本分为多个组,每个组称为“簇”(cluster),形成簇的过程称为“聚类”(clustering),聚类所用的训练样本通常不拥有标记信息
- 监督学习(supervised learning):训练数据有标记信息
- 分类和回归是监督学习的代表
- 无监督学习(unsupervised learning):训练数据无标记信息
- 聚类是无监督学习的代表
- 机器学习的目标是使学得的模型能更好地适用于新样本,学得模型适用于新样本的能力称为“泛化(generalization)”能力
ps:泛化可理解为:婴儿(没错,又是那个娃)能分辨出他从未看过的新图片上的狮子or老虎,而不是对我们原来给他看过的图片分辨,即能“举一反三”
通常假设样本空间中全体样本服从一个未知“分布”,获得的每个样本都是独立地从这个分布上采样获得的,即“独立同分布(independent and identically distributed,简称 i.i.d.)”
- 归纳(induction):从特殊到一般的”泛化(generalization)“过程
- 具体事例到一般性规律
演绎(deduction):从一般到特殊的”特化(specialization)“过程
- 基础原理到具体情况
“从样例中学习”是一个归纳的过程,因此也称为“归纳学习(inductive learning)”
广义的归纳学习:大体相当于从样例中学习
狭义的归纳学习:从训练数据中学得“概念”,亦称为“概念学习”
ps:要学得泛化性能好且语义明确的概念较为困难,现实常用的技术大多是产生“黑箱”,狭义的归纳学习适用范围太小
我们可以把学习过程看作一个在所有假设(hypothesis)组成的空间中进行搜索的过程,搜索目标是找到与训练集“匹配”(fit)的假设,即能够将训练集中的瓜判断正确的假设。
由于实际训练集是有限的,因此可能有多个假设与训练集相一致,即存在着一个与训练集一致的“假设集合”,这个假设集合被称为“版本空间”(version space)”
ps:备选的所有假设的集合机器学习算法在学习过程中存在着对某种类型假设的偏好,称为“归纳偏好”(inductive bias),简称为“偏好”
ps:非人为控制,是机器自身的某种选择
任何一个有效的机器学习算法必有其归纳偏好,否则它将被假设空间中看似在训练集上“等效”的假设所迷惑,而无法产生确定的学习结果
“没有免费的午餐”定理(No Free Lunch Theorem) 证明了不论算法有多么“精妙”,它们产生误差的期望性能是相同的,但NFL定理的前提,即所有“问题”出现的机会相同、或所有问题同等重要,在实际解决问题的过程中是不存在的
NFC定理最重要的寓意,是让我们清楚地认识到,脱离具体问题,空谈地讨论“什么学习算法更好”毫无意义,因为若考虑所有潜在的问题,则所有学习算法都一样好。要谈论算法的优劣,必须要针对具体的学习问题;在某些问题上表现好的学习算法,在另一些问题上却可能不尽如人意,学习算法自身的归纳偏好与问题是否相配,往往会起到决定性的作用。
正文就此结束啦~
目前还处于学习的最初级阶段,欢迎大家讨论、指正错误,蟹蟹!














 2301
2301











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









