







1. 背景介绍
这是2017年Google Brain团队发表的一篇比较经典的论文, 可以做为MOE在大语言模型上应用的第一篇, MOE全称是混合专家(Mixture of Experts). 这里的每个Expert都是一个更小的神经网络, 比如最简单就是FC全连接网络, MOE整体不是一个完整的网络结构, 而是作为layer层嵌入到别的网络中.
首先介绍这篇论文的背景, 模型的学习能力强弱跟模型的参数量有关, 即模型越大参数量越多那么模型效果越好, 同时存在个问题就是按之前稠密模型的设计, 模型参数量越大计算量也越大, 计算越慢. 有没有一种方式既可以增大模型参数量又能使得计算量控制在一定范围内(对应有个名词叫条件计算conditional computation), 这就是这次论文讨论的重点. 本文中基于LSTM堆栈基础上应用了MOE结果使得参数量提升至137B大小, 相比之前模型容量提升了有1000倍, 但是计算量只增加了一少部分, 具体数据和效果看最后.
2. 网络介绍
一个完整的MoE由n个专家网络( $ E_1, …, E_n $, )和一个门控网络
G
G
G 组成. 每个专家网络定义为一样的前向网络结构, 参数不同, 接收相同大小的输入, 输出规模保持一致; 门控网络的输出是一个n维的向量, 用来表示选择对应的专家. 如图中所示, 分别以
G
(
x
)
G(x)
G(x) 与
E
i
(
x
)
E_i(x)
Ei(x) 做为门控网络的输出与第i个专家的输出,
x
x
x 是输入, 最终输出
y
=
∑
i
=
1
n
G
(
x
)
i
E
i
(
x
)
y = \sum^n_{i=1} G(x)_i E_i(x)
y=∑i=1nG(x)iEi(x) . 门控网络输出
G
(
x
)
G(x)
G(x) 是稀疏向量, 表示选择专家的权重,
G
(
x
)
i
=
0
G(x)_i=0
G(x)i=0 时, 就不用计算
E
i
(
x
)
E_i(x)
Ei(x) .
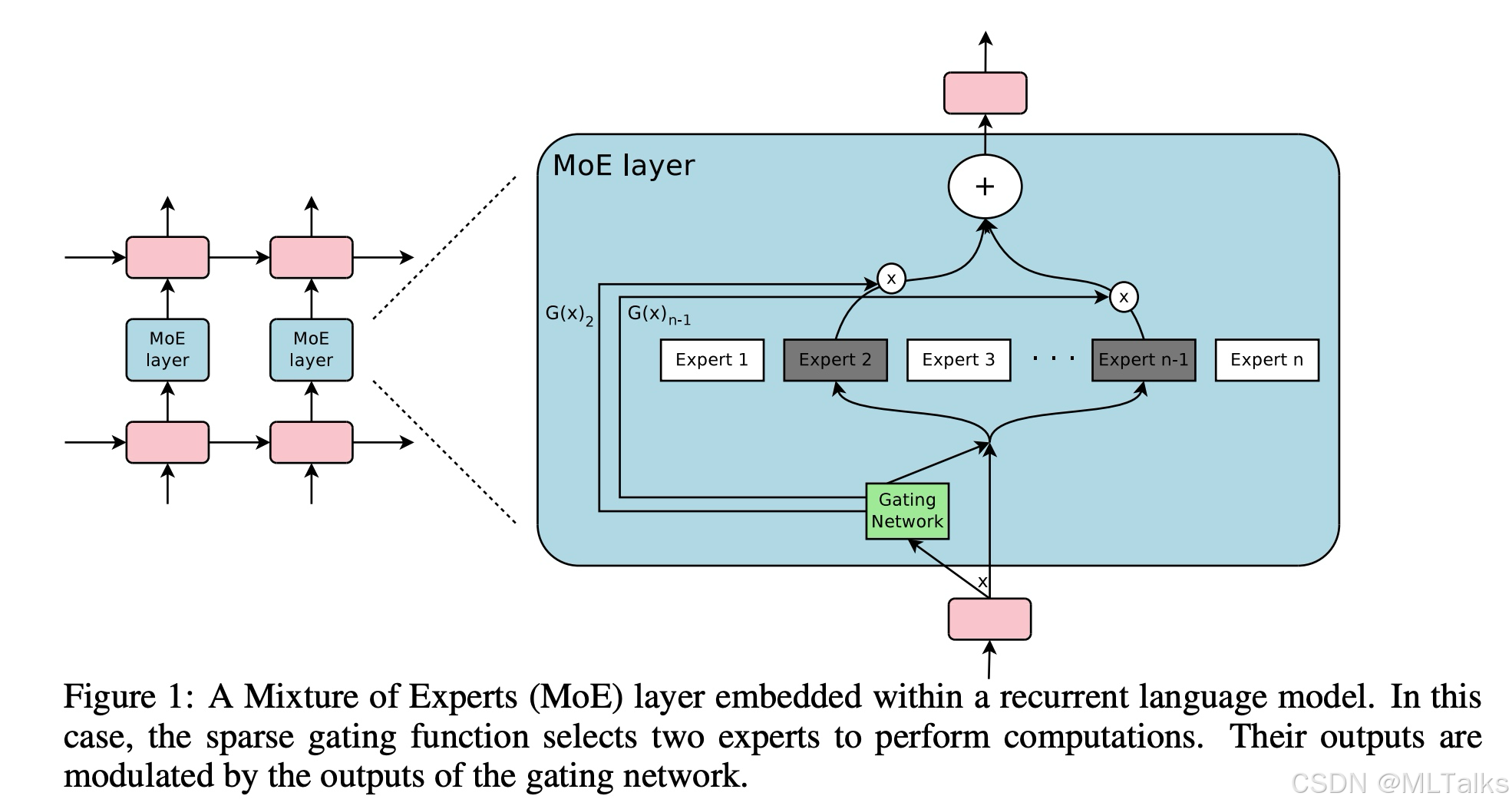
这里Expert个数有上千个, 虽然很多, 但是每次只用计算其中一部分; 如果Expert进一步增大, 可以考虑对Expert进行分组, 设计成两层结构的MoE(层次Moe, Hierarchical MoE), 第一次先通过门控网络选择某一个分组, 第二次再选择具体的Expert. 思想很简单, 下面具本看下对应的实现.
对于门控网络的设计对比了两种方式, 一种是1994年提出的非稀疏门控网络, 定义如下, x x x 是输入, W g W_g Wg 是可训练学习的参数.
G σ ( x ) = S o f t m a x ( x ⋅ W g ) \begin{gather} G_{\sigma}(x) = Softmax(x \cdot W_g) \end{gather} Gσ(x)=Softmax(x⋅Wg)
另外一种是带噪声的Top-K门控(Noisy Top-K Gating), 在非稀疏门控网络基础上加上了稀疏化和噪声, 稀疏化用于只保存选择前
K
K
K 个专家, 噪声用于使得专家的调用能够负载均衡, 定义如下. 在训练门控网络过程中还是使用反向传播, 当
k
>
1
k>1
k>1 时, 对应top-K专家的门控网络进行求导.
KaTeX parse error: Undefined control sequence: \mbox at position 184: …ray}{cl} v_i & \̲m̲b̲o̲x̲{if } v_i \mbox…
3. 性能挑战
3.1 batch大小缩减问题
batch越大对应的训练效率越高, 但对于门控网络来说, 每一个样本的处理时都会从 n n n 个专家中选出来 k k k 个专家, 假设一个batch中有 b b b 条样本, 那么每个专家会收到样本数约为 $ \frac{kb}{n} \ll b $ , 远小于原来batch中的 b b b 条样本. 当MoE中的专家数更多时, 处理的样本数就会更不足, 一个解决办法是增大batch中的样本数, 但一旦增大后, 训练前反向时的activation中间结果大小会增大, 显存可能会OOM. 提出了以下几种办法来进行处理:
- 混合数据并行和模型并行: 在一般分布式数据并行时, 模型会copy好几份, 每一份模型会分别处理不同的batch数据. 改动点是在数据并行时标准的网络层和门控网络还是按之前数据并行来处理(复制多份), 但只会保存一份专家的复本(专家按模型并行来进行拆分, 每个设备上会分配一部分专家), 每个专家都会收到数据并行中全量的输入数据. 比如模型并行按 d d d 个设备(device/卡)来进行拆分, 每个device上会处理 b b b 条样本, 最终每个专家会处理 k b d n \frac{kbd}{n} nkbd 条样本, 这样相比最早处理的量提升了 d d d 倍.
- 充分利用卷积性(Taking Advantage of Convolutionality): 这里提到的卷积性,指的是在处理时间序列数据时,模型能够利用时间上的局部性和重复性,以高效地处理输入。对于每一时刻的layer都应用相同的MoE, 这样可以变相提升MoE的输入的batch大小, 比如像RNN结构按时间展开有
m个step, 那么输入的batch数量相当于提升了m倍 - 增大递归MoE网络中的batch大小: 像LSTM和RNN网络中的weight权重可以替换为MoE网络, 借助论文<Memory-efficient backpropagation through time>, 可以减少中间activation结果的显存占用, 从而对应增加batch大小.
3.2 网络带宽
另外一个影响性能的因素是网络带宽, MoE中专家数量是固定的, 同时gating参数不大, 主要的通信用于发送和接收expert的计算输入与输出. 为了保持计算高效, 专家的计算量与其输入和输出的大小之比必须超过设备的计算能力与网络带宽的比率。对于GPU,这个比率可能高达千比一(thousands to one),这意味着计算量要远远大于网络传输量。
在实验中,专家通常具有一个隐藏层,里面包含数千个激活单元(RELU激活函数)。这样的设计使得每个专家在处理输入时能够进行大量的计算。专家的权重矩阵大小为 input_size × hidden_size 和 hidden_size × output_size,这意味着计算量与隐藏层的大小直接相关。换句话说,隐藏层越大,计算量就越大。为了提高计算效率,可以通过增加隐藏层的大小或者增加隐藏层的数量来实现。这种方法可以有效地提升专家的计算能力,从而改善整个系统的性能。
4. 均衡专家使用率(Balancing Expert Utilization)
在训练过程中参与训练越多的专家越有可能被再次选择, 这样专家的调用会很不均衡. 为了解决这个问题, 定义了一个新的loss值名为 L i m p o r t a n c e L_{importance} Limportance , 这个loss会加到总的loss中, 用于让所有expert具有相同的机会被选择上. 具体说明如下:
- loss
L
i
m
p
o
r
t
a
n
c
e
L_{importance}
Limportance 中用到了一个
Importance(X)的概念, 定义是一个batch中所有样本的 G ( x ) G(x) G(x) 的和. -
L
i
m
p
o
r
t
a
n
c
e
L_{importance}
Limportance 定义等于
i
m
p
o
r
t
a
n
c
e
importance
importance 的变异系数(
Coefficient of variation) 的平方, 同时乘上一个 w i m p o r t a n c e w_{importance} wimportance 的权重.
I m p o r t a n c e ( X ) = ∑ x ∈ X G ( x ) L i m p o r t a n c e = w i m p o r t a n c e ⋅ C V ( I m p o r t a n c e ( X ) ) 2 \begin{align*} &Importance(X) = \sum_{x \in X} G(x) \\ &L_{importance} = w_{importance} \cdot CV(Importance(X))^2 \\ \end{align*} Importance(X)=x∈X∑G(x)Limportance=wimportance⋅CV(Importance(X))2
这里的变异系数(简称 C V CV CV )定义参考 Coefficient of variation. 定义为标准差除以均值. 如果一个tensor中的值的差距越大, 那么这个tensor的CV值越大.
C V = σ μ w h e r e σ = s t a n d a r d d e v i a t i o n μ = m e a n \begin{align*} &CV = \frac{\sigma}{\mu} \\ &where \\ &\sigma = standard\ deviation \\ &\mu = mean \end{align*} CV=μσwhereσ=standard deviationμ=mean
pytorch示例如下:
import torch
def cv(x):
eps = 1e-10
return x.float().std() / (x.float().mean()**2 + eps)
x = torch.tensor([0.5, 0.5])
print(f"{x=} {cv(x)=}")
x = torch.tensor([0.1, 0.9])
print(f"{x=} {cv(x)=}")
结果:
x=tensor([0.5000, 0.5000]) cv(x)=tensor(0.)
x=tensor([0.1000, 0.9000]) cv(x)=tensor(2.2627)
5. 效果
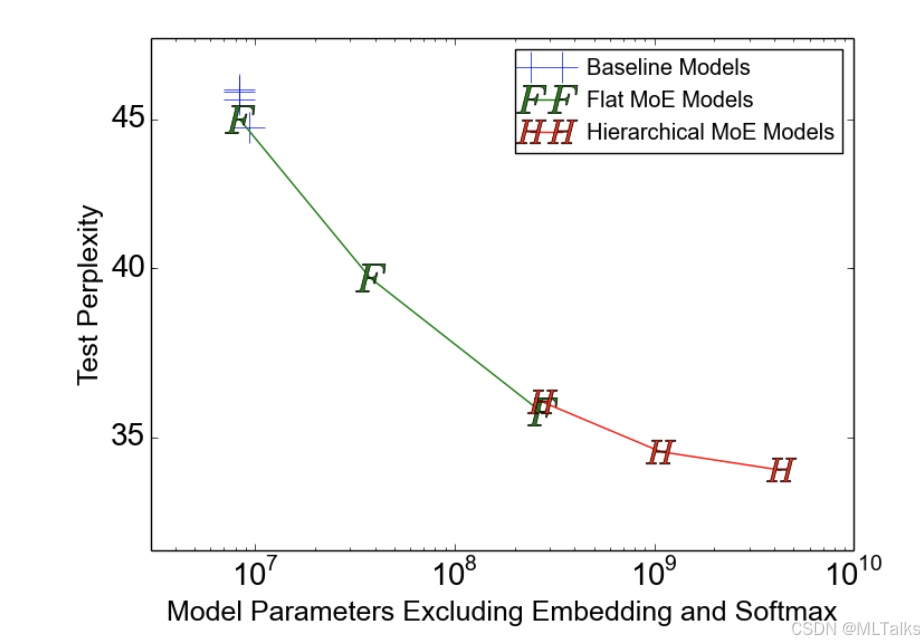
- 以两层LSTM结合MoE训练了包含4, 32, 256个专家的flat MoE(对应层次MoE) , 以及包含256, 1024, 4096个专家的层次MoE(hierarchical MoE), 以
test perplexity作为模型容量的指标, 结果如下, 参数量越大,perplexity越低, 容量越大. 4096个专家的网络达到了24%的perplexity值.
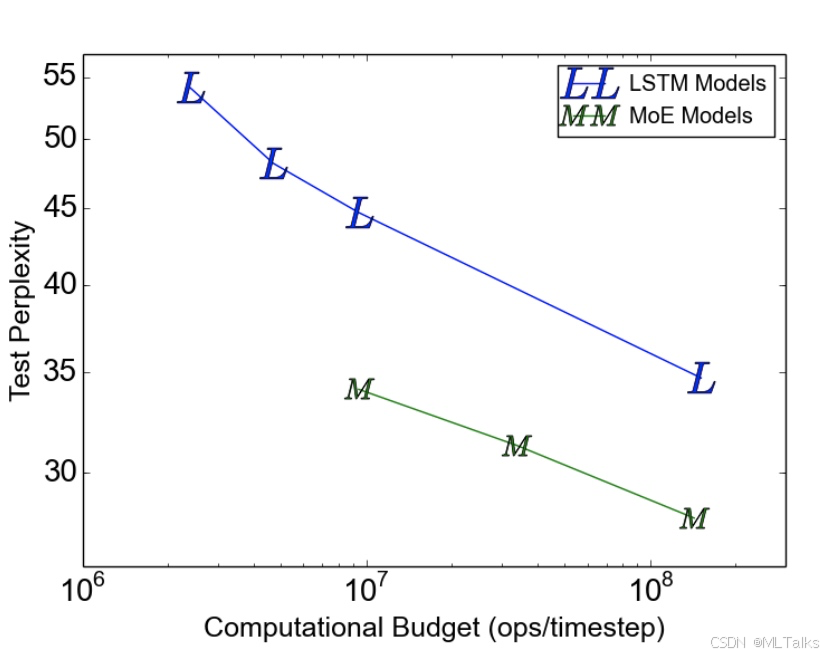
- 分别比较了在同等计算量情况下(约8-million-ops-per-timestep, 这里的ops对应的是MAC乘加计算), 支持不同规模的MoE网络的训练
test perplexity值. 可以看出在最大的 1 0 8 10^8 108 计算量下, 支持4371 million参数的训练, 达到了最低的28.0的test perplexity值
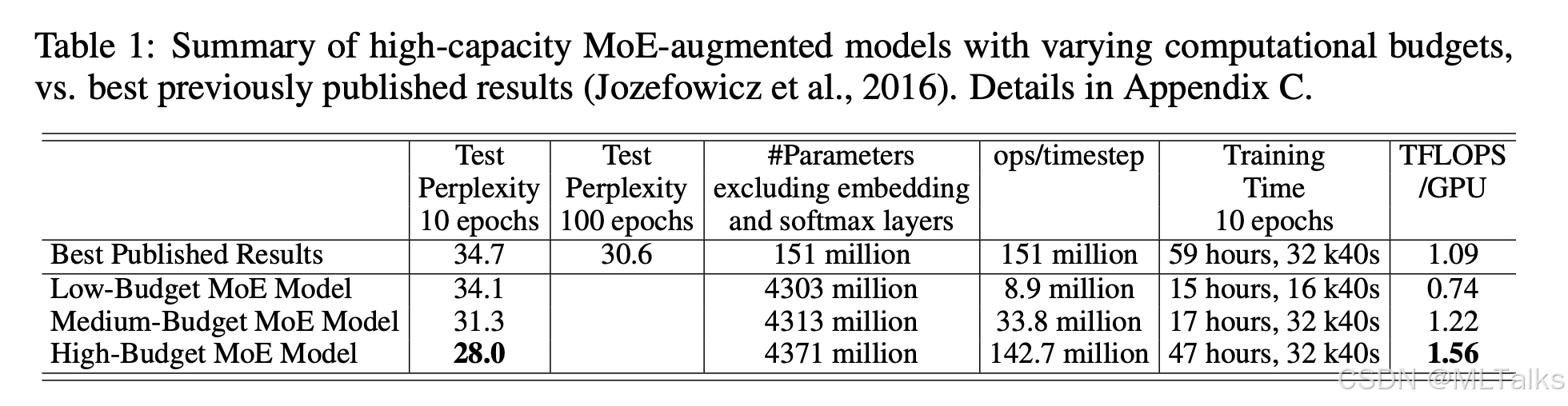


















 651
651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











