







 本文探讨了混合专家模型(MoE)在神经网络中的应用,特别是稀疏门控版本,旨在在不增加计算负担的前提下大幅增加模型容量。作者介绍了MoE的工作原理,如何通过门控网络选择专家,以及如何通过软约束平衡专家利用率和负载。
本文探讨了混合专家模型(MoE)在神经网络中的应用,特别是稀疏门控版本,旨在在不增加计算负担的前提下大幅增加模型容量。作者介绍了MoE的工作原理,如何通过门控网络选择专家,以及如何通过软约束平衡专家利用率和负载。
几个月前看过MoE这篇文章,最近再看,发现只记得一个大致的概念,细节又都忘了。记忆不可靠,还是记录吧。最近,在看有关大脑的一些书籍,逐渐知道人的记忆有多不可靠,随着周围所遇所感,大脑在不断重塑着记忆,而大脑本身的运作机制,可能并不是为了记忆过去,而是为了预测未来以决策当下。
MoE,就是专家混合模型,这种模型可以认为是具有不同的子模型(或专家),每个子模型适用于不同的输入,每一层由门控网络控制,网络根据输入数据激活专家。
MoE是一种条件计算(Conditional Computation)的方法,主要解决的事情就是,模型参数容量太大的情况下可以显著降低计算量,或者反过来说,模型的容量可以在不增加计算量的情况下显著增加,具体就是针对不同的输入通过门控机制激活网络的不同部分来实现的。
MoE这种方法很容易想象,因为人的大脑有类似的机制。人的大脑针对不同的任务,只有部分的神经元集群激发进行工作,大脑的不同区域有不同的分工。最近读《人工智能未来简史――基于脑机接口的超人制造愿景》一书中,有这样一段描述,“向大脑输入信息后,将引发某些神经元集群的放电,并随即引发相应的意识和行为。但是,神经元集群放电也不能为所欲为,它必须遵守所谓的‘保存原则’,即神经元集群的放电,不仅有最大值的限制,而且整体集群的放电率也趋向于一个固定值。这种放电率之所以会在平均值周围徘徊,是因为各种补偿机制创建了一种比较稳定的平衡状态,实际上,大脑在某个时刻只会产生有限数量的动作电压来表征特定类型的信息。若某个或某些皮层神经元瞬间增大了它们的放电率,则集群中其他神经元将很快产生一个相等的镜像减量,于是大脑整体的能量消耗便能长期保持恒定。”这样看起来,MoE的方法对比人类的大脑,还是简单太多。

文章标题为《OUTRAGEOUSLY LARGE NEURAL NETWORKS: THE SPARSELY-GATED MIXTURE-OF-EXPERTS LAYER》,由Noam Shazeer等人撰写,发表在2017年的ICLR会议上。
摘要:
神经网络的信息吸收能力受到其参数数量的限制。理论上,条件计算(其中网络的各个部分根据每个示例进行激活)作为一种在不增加计算量的情况下显著提高模型容量的方法被提出。然而,在实践中,还存在显著的算法和性能挑战。在这项工作中,我们解决了这些挑战,最终实现了条件计算的承诺,在现代 GPU 集群上仅在计算效率方面略有损失,就实现了模型容量的超过 1000 倍的提高。我们引入了一种稀疏门控混合专家层(MoE),由多达数千个前馈子网络组成。一个可训练的门控网络确定用于每个示例的这些专家的稀疏组合。我们将 MoE 应用于语言建模和机器翻译任务,其中模型容量对于吸收训练语料库中大量知识至关重要。我们在堆叠的 LSTM 层之间应用卷积的 MoE,其中 MoE 具有多达 1370 亿个参数。在大型语言建模和机器翻译基准测试中,这些模型在较低计算成本下取得了比最先进技术明显更好的结果。
主要方法
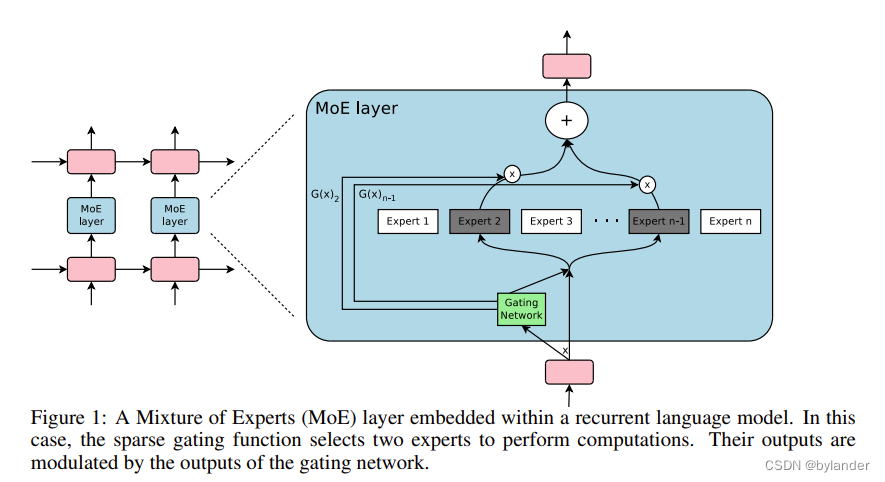
文章的主要方法见图1,通过稀疏门控函数选择专家子模型(图示中是两个专家)来执行计算,输出由门控网络的输出控制。
输出用下面的公式表示:
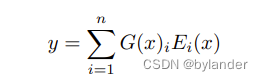
门控网络,一个比较简单方式可以使用Softmax门控,将输入乘以可训练的权重矩阵Wg,然后应用Softmax 函数。
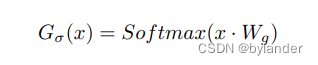
但是这样还是有大量专家模型被激活,所以在Softmax门控网络添加了两个组件:稀疏性和噪声。在使用softmax函数之前,添加可调高斯噪声,然后只保留前k个值,将其余值设置为-∞(这会导致相应的门值等于0)。稀疏性用于节省计算,按照文章描述,虽然这种形式的稀疏性在选通函数的输出中产生了一些理论上可怕的不连续性,但尚未在实践中观察到这是一个问题。噪声项是用于负载平衡,每个组件的噪声量由第二个可训练权重矩阵Wnoise控制。

在训练门控网络时,使用简单的反向传播训练门控网络和模型的其余部分。如果选择 k> 1,则前k 个专家的门值相对于门控网络的权重具有非零导数。梯度也通过门控网络进行反向传播一直到其输入。
平衡专家的利用率
但是这个门控网络还需要改进。文章指出,门控网络倾向于收敛到一种状态,即它总是为同几个专家产生较大的权重。这种不平衡是自我强化的,因为受到青睐的专家被更快速地训练,因此被门控网络更多地选择。Eigen等人(2013)描述了同样的现象,并在训练开始时使用硬约束来避免这种局部最小值。Bengio等人(2015)在批量门控的平均值上包含了一个软约束。
文章采取软约束的方法,定义对于一个批次训练样本的专家重要度(the importance of an expert),即该专家在一个批次训练样本的门控输出值的和。定义了新的损失函数 Limportance,添加到模型的总体损失函数中。这个损失等于专家重要度集合的变异系数的平方,乘以一个手动调整的缩放因子 wimportance。这个额外的损失鼓励所有专家具有相等的重要性。
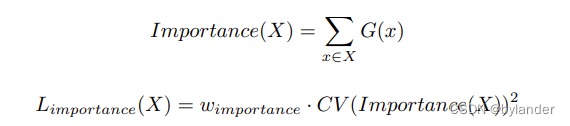
公式中的CV,通过kimi来了解一下:

虽然这个损失函数可以确保重要性的平等,但专家模型可能仍然接收到非常不同数量的输入。可能导致分布式硬件上的内存和性能问题。为了解决这个问题,文章还引入了第二个损失函数 Lload,确保了负载的平衡。
(欢迎关注微信公众号:老无谈藏书票)


















 1445
1445

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











