







数据挖掘过程
制定数据挖掘问题:从目标到任务再到技术

一般数据挖掘的良性循环描述为一个业务流程,其中把数据挖掘划分为4个阶段:
(1) 识别问题
(2) 将数据转换为信息
(3) 采取行动
(4) 度量结果
本文的重点转向把数据挖掘作为技术过程,把识别业务问题转变为将业务问题转化为数据挖掘问题。同时,第二个阶段——把数据转换为信息,将扩展到几个主题,包括假设检验(hypothesis testing)、模型构建(model building)和模式发现(pattern discovery)。避免打破数据挖掘良性循环的最好方式是了解它可能会失败的方式,并采取预防措施。本文介绍了三个主要的数据挖掘类型,首先是简单的方法——通常通过使用特设查询检验假设,接着介绍更加复杂的活动,例如可用于评分的模型构建,以及使用无指导数据挖掘技术的模式发现。本文主题是从业务目标的明确说明,转移到为实现目标所需的对数据挖掘任务的明确理解,以及适合该任务的数据挖掘技术。
一 会出什么问题?
数据挖掘是一种从过往中学习以便在将来更好地做决定的方法。本章中描述的最佳实践旨在避免两个不可取的学习过程结果:
● 学习的东西不真实。
● 学习的东西为真,但是无用。
古代水手学会了如何避免为保护西西里和意大利大陆之间狭窄海峡的锡拉岩礁(Scylla)岩石和卡律布迪斯(Charybdis)漩涡。像学会避免这些威胁的古代水手们一样,数据挖掘人员也需要知道如何避免常见的危险。
二 数据挖掘类型
定义数据挖掘为“探索和分析大量数据以产生有意义的结果”。这是一个广泛的定义,足以包括许多不同的方法。主要有三种类型:
● 假设检验(Hypothesis testing)
● 有指导数据挖掘(Directed data mining)
● 无指导数据挖掘(Undirected data mining)
假设检验的目标是使用数据来回答问题或掌握知识。有指导数据挖掘的目标是构建一个模型,其能够解释或预测一个或多个特定的目标变量。无指导数据挖掘的目标是找到全部的模式,而不是绑定到一个特定的目标。在一个数据挖掘项目过程中,你可以采用这些类型中的任何一种类型或者所有类型,这取决于问题的性质和你对数据的熟悉程度。
虽然这三种类型的数据挖掘有一些技术性的差异,但是它们也有很多共同之处。
三 目标、任务和技术
一位数据挖掘顾问说,他生活在恐惧当中,害怕客户会阅读一篇提到一些特定数据挖掘技术名称的杂志文章。当营销副总裁开始询问神经网络与支持向量机时,可能就到了重置会话的时间。数据挖掘总是开始于一个业务目标,而数据挖掘人员的首要工作就是很好地理解这一目标。这一步骤需要在设定目标的上层管理人员以及负责将这些目标纳入数据挖掘任务的分析师之间进行良好的沟通。下一步工作是根据数据挖掘任务重申业务目标,直到此时才会选择特定的数据挖掘技术。
数据挖掘业务目标
数据挖掘应用提供了几个业务目标的好例子:
● 选择广告的最佳位置。
● 为分支或商店寻找最佳位置。
● 获取更多有利可图的客户。
● 降低暴露于违约的风险。
● 改进客户保留。
● 检测欺诈性索赔要求。
本书的其余部分还包含了许多数据挖掘的示例,它们用于解决现实世界中的实际问题。并非所有的业务目标本身都可直接作为数据挖掘的业务目标;有时候必须把它们转变成数据挖掘的业务目标。数据挖掘要想成功,业务目标应该明确,同时指向适于使用现有数据进行分析的特定努力。数据挖掘的业务目标通常可以表示成可测量的事物,如增量收益、响应率、订单大小或者等待时间等。
当然,实现这些目标需要的不只是数据挖掘,但是数据挖掘可以发挥重要的作用。第一步是为问题设计一个高级方法。为了获得更多有利可图的客户,你可以首先学习驱动已有客户的盈利因素,然后获取具有合适特征的新客户。降低信贷风险可能意味着预测哪些目前信誉良好的客户可能会变质,同时提前减少他们的信用额度。提高客户保留可能会聚焦于改进现有客户的体验,或者获取持续期预期会很长的新客户。高级方法提出特定的建模任务。
四 制定数据挖掘问题:从目标到任务再到技术
业务目标、数据挖掘任务和数据挖掘技术形成了一个阶梯,分别为从一般到具体和从非技术性到技术性。制定数据挖掘问题涉及从该阶梯上下降,每次一步;先从业务目标到数据挖掘任务,然后从数据挖掘任务到数据挖掘技术。通常,每个步骤都需要具有不同技能集的不同工作人员参与。设置目标及其优先次序是上层管理人员的责任。把这些目标转换成数据挖掘任务,并使用数据挖掘技术来完成它们是数据挖掘人员的责任。收集必要数据,并把它转化为合适的形式常常需要数据库管理员与信息技术组其他成员的合作。
1 选择广告的最佳位置
一家公司正试图得到新的有利可图客户。它应该去哪里做广告?Google AdWords?现实的电视烹调节目?杂志?如果是杂志,应选择哪一份?Architectural Digest?People en Español?还是Rolling Stone?
许多因素会影响决策,包括总体成本,每个效果的费用,以及每次转换的费用。通过匹配广告媒介的人口统计信息与最佳客户的人口统计信息,数据挖掘可以为决策提供输入。有利可图客户的行为数据没有作用,因为广告只是基于人口统计数据。
一种可能的方法是:
(1) 使用人口统计和地理特征剖析现有的有利可图客户,诸如年龄、性别、职业、婚姻状况和社区特征等。使用这个剖析定义有利可图客户的原型。
(2) 使用用于剖析有利可图客户的相同变量,定义每个潜在广告媒介的受众。
(3) 估计每个广告渠道到有利可图客户原型的距离。这个距离是广告渠道的相似得分,正如打高尔夫一样,越小会越好。
(4) 在得分最低的场地做广告。
这是一个相似度模型(similarity model)的示例,将在第6章对其进行介绍。
2 确定向客户提供的最佳产品
下一个向客户提供的最佳优惠是什么?这个问题是在许多行业都会发生的交叉销售的一个例子。
针对这个问题有几种可能的办法,在许多因素中它们主要取决于可供选择的产品数量。如果可管理的产品数量比较少,那么一个好办法是为每款产品建立一个单独的模型,从而可以对每个客户给定每款产品的得分,如图1所示。客户的最佳优惠是他具有最高分数的产品(可能已经排除了客户已有的产品)。
(1) 对于每款产品,构建一个二元响应模型来估计客户对该产品的倾向。
(2) 对于已经有一个产品的客户,设置其倾向得分为0。
(3) 使用这些倾向得分,设计为每个客户指定最佳产品的决策过程,该过程将基于类似最高倾向或最高期望利润之类的度量。
步骤(1)中的自然选择包括决策树、人工神经网络和逻辑回归。
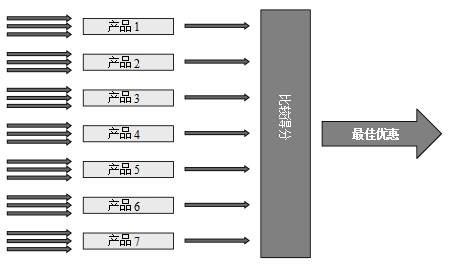
图1 对比每款产品的个人得分倾向以确定最佳优惠
二元响应模型并非计算倾向得分的唯一方法。另一种方法是使用输入变量对数据进行聚类,查看每个群集中哪些产品占主导地位。可以把一款给定产品在群集中的比例指定为倾向的得分。该方法可以使用K-Means聚类或另一种聚类技术。
3 发现分支或商店的最佳位置
新商店的最佳位置应该在哪里?在这个场景中,现有商店的绩效数据与服务区(每个商店服务客户的自然市场区域)的数据相连。其思想是要找到一组解释变量能够预测一家商店的良好绩效。
以下建模任务是解决该问题的一种方法:
(1) 建立一个模型来估计某个商店绩效指标,该指标是基于该服务区的可用解释变量。
(2) 把该模型应用到候选位置,从而可以选择得分最高的位置。
这基本上是一种估计模型,可以使用各种技术,如神经网络、回归或MBR等。
一种替代方法是把商店分类为好或者坏,然后构建模型来预测这些组。通常,这么做的一种好办法是采取排除中间的做法:每个商店的利润分成三个级别——高、中、低。去掉位于“中间的”商店,并构建一个模型来区分高和低:
(1) 把现有的商店分类为好或坏,同时建立一个能够区分这两个类的模型。
(2) 把该模型应用到候选位置,从而可以选择好的候选者。
可能的解释变量包括驾驶距离内的人口、驾驶距离内竞争对手的数量以及人口因素。这是一个剖析模型,因为目标是把当前绩效与当前环境相连。建模的技术是那些用于分类的技术,如逻辑回归分析、决策树以及MBR等。
4 根据未来利润划分客户
我们已经建立了一种定义利润的方法,如客户在一年中产生的总收益或净收益。现在的目标是基于客户在下一年的预期盈利能力对他们进行划分。
有许多方法可用来计算盈利能力。这种方法省略了一些更为困难的主题,如预测一个客户在多长时间内仍将是客户(并因此决定将来的折扣率),以及如何定义客户的网络效应(network effect)。
对于这种方法,把时钟往回拨一年,为每个当时活跃的客户生成一个快照。然后,度量下一年期间的总收益。以下就是该模型:
(1) 为建模准备数据,把时钟往回拨一年,为每个当时活跃的客户生成一个快照。然后,度量下一年期间的总收益。这将创建一个预测模型集。
(2) 使用此模式集估计某个人在下一年将会产生多少收益。
(3) 将预期收入分为三个级别,分别是得到高、中、低的预期收益。
第(2)步需要建立一种估算模型,利用诸如神经网络、MBR或回归等技术。
对这种方法进行轻微改变,将模型集中的客户分类为在来年中的高、中或低收益产生者。这将使用一个分类模型,它可能是决策树(具有三个目标)或三个逻辑回归模型(每个分组一个模型)。
5 减少暴露于违约的风险
此业务问题的目标是当仍有时间采取措施降低暴露时,检测出违约的警告信号。一种检测方法是使用二元响应模型,其以“违约”为目标。该模型集是在给定时间点(例如,第一年)所有客户的快照,同时也是一个标志,表明他们在快照日期之后的三个月是否违约。可以用二元响应模型对新客户打分,预测其违约的概率。也许,对于具有高违约水平的客户应该降低他们的信贷额度。
可以使用各种技术构建这样一个二元响应模型,如逻辑回归、决策树或神经网络等。甚至可以使用无指导技术,例如聚类。在输入变量上建立群集,然后度量群集的能力以分离目标值。这是一个将无指导技术用于有指导模型的例子。
另一种方法是将违约的概率与违约的数量相结合。这个两阶段模型会估计一个客户在违约后的欠款数额。为此,该模型集只包含已经违约的客户,其目标是欠款数额。该模型将用于计算预期的亏损值,即违约的概率乘以估计的欠款数额。对欠款数额的估计可以使用MBR、神经网络、回归或可能使用决策树来构建。
然而,另一种方法是把它当作实时事件(time-to-event)问题,当一个客户可能会违约时对其进行估计。在这种情况下,该模型集包含所有的客户,包括他们的开始日期、结束日期以及该客户是否违约。该模型将估计客户违约的时间。当对新客户打分时,如果违约的估计时间是在不久之后,那么将采取行动来降低违约风险。这种类型的模型通常会使用生存分析来构建。
6提高客户保留
有许多不同的方式可用来提高客户保留:
● 发现离开风险最高的客户,并鼓励他们留下来。
● 量化改进操作的价值,从而使得客户将继续保留。
● 确定哪些获取客户的方法会带来更好的客户。
● 确定哪些客户无益,并让他们离开。
本节只讨论其中的第一个方式。
确定谁将留下的任务列表与任何二元响应模型的任务列表类似。建立一个模型集,其中包含留下和离开的客户,同时构建模型以发现区分他们的模式。这会提供一个模型评分,你可以将它用于保留工作。
这种类型的二元响应模型可以使用许多诸如决策树、神经网络、逻辑回归与MBR之类的技术来构建。一种估计客户剩余持续期的替代方法是使用生存分析,并把保留信息应用到不久之后最有可能离开的客户。
有时,一个模型最重要的输出不是其产生的分数,而是通过检查该模型本身所产生的知识。该模型能够解释客户是否主要是由于服务中断、价格敏感性或者其他原因而离开。然而,这需要使用一种能够解释其结果的技术。决策树和逻辑回归是最具可解释性的突出代表。
7检测欺诈性索赔
把这一目标转换成模型任务取决于是否存在已知欺诈的例子。如果是,那么这是一个有指导数据挖掘任务:
(1) 构建一个能够从合法索赔中区分欺诈性索赔的剖析模型。
(2) 利用该模型对所有进来的索赔评分。标注得分高于某个阈值的索赔,从而在批准之前对其进行额外的审查。
决策树和逻辑回归是可用于在步骤(1)中构建剖析模型的技术。
有时,虽然涉嫌欺诈,但是并不清楚哪些事务是欺诈性的。这种情况要求无指导数据挖掘:
(1) 形成类似索赔的群集。大多数的索赔可能会落到少数几个大的群集中,它们代表了不同类型的合法索赔。
(2) 审查较小的群集,以了解它们如此特殊的原因。
在较小群集中的索赔也可以是完全合法的。聚类操作所能表明的仅仅是它们不同寻常。因为一些不寻常的索赔被证明是欺诈,所以所有这些都值得进一步审查。
一个目标,两个任务:赢得数据挖掘的比赛
每年,学术界和工业界的竞争者们都会在一项与年度KDD(知识发现和数据挖掘)会议同时举行的竞赛中测试他们的数据挖掘技能。某一年,非常清楚的是优胜者与失败者的区别不在于他们使用的算法或软件,而是他们如何将业务问题转化为数据挖掘任务。
业务问题是要最大化一个非营利慈善团体的捐款。数据是一个关于捐献的历史数据库。
探索数据之后发现了第一个结论:某些人捐献的次数越多,则他们每次捐献的钱就越少。最好的捐助者是那些最频繁的响应者,这样的预期非常合理。
不过,在这种情况下,人们似乎是以年为基准计划他们的慈善捐款。他们可能会一次性捐赠,或者随着时间推移进行间隔捐献。更多的检查并不总是意味着更多的钱。这表明决定捐赠与捐赠多少是分离的。这两项决定很有可能受到不同因素的影响。也许,无论是哪个收入水平的人,如果他们自身在军队服过役,那么他们都更有可能捐赠给一个老兵组织。在他们已决定作出捐献之后,收入水平可能会影响捐赠多少。
这些结论可以导致赢的方法,即分别对响应和捐献的大小进行建模。响应模型是在一个同时包含捐献者和非捐献者的训练集上构建。这是一个二元结果分类任务。
捐献大小模型是在一个仅包含捐献者的训练集上构建。这是一种评估任务。下图显示了这两个模型,以及如何结合它们的结果以产生每个潜在客户的期望响应值。
三个优胜组都是采用这种模型相结合的方法。另一方面,大多数竞争者建立了一个以捐献数额为目标的单一模型。这些模型把整个问题看作是一个评估任务,其中未响应表示为一个零美元的捐献。
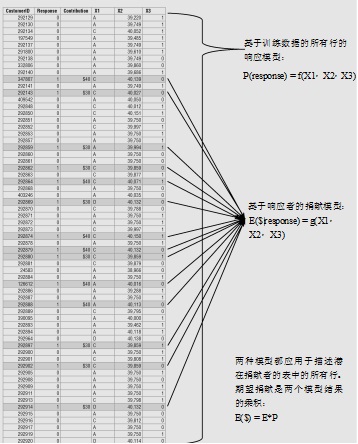
期望捐献值的两阶段模型
五 经验教训
数据挖掘过程可能会因为多种原因导致失败。失败的形式多种多样,包括仅仅是不能回答你提出的问题,以及“发现”你已经知道了的事情。一种特别有害的失败类型是学习的东西不真实。其发生的原因多种多样:当用于挖掘的数据不具代表性时;或者当它包含不能泛化的意外模式时;或者当它以破坏信息的方式进行了汇总时;或者当它把本应保持独立的不同时期的信息混合在一起时。
有三种类型的数据挖掘。探索性数据挖掘产生见解或回答问题,而不是生成用于评分的模型。探索性数据挖掘通常涉及构造出使用数据能够证明或不能证明的假设。探索性数据挖掘非常重要;然而,它不是本书高级技术的主题。
当历史数据包含正在寻找的实例时,使用有指导数据挖掘。对于流失模型,其假设历史数据中包含了已经留下或离开的客户实例。对于客户价值模型,其假设可以使用历史数据来估计客户价值。该模型的目标就是这些变量。该模型的“解释”变量是输入。
无指导数据挖掘不使用目标变量。这就像是把数据扔进计算机,然后看它在哪着陆。为了使无指导数据挖掘有意义,需要对结果进行理解和解释。由于没有目标,计算机无法判断结果是好还是坏。
你可以单独使用这三种数据挖掘,或者组合它们来完成一个范围广泛的业务目标。数据挖掘过程以业务目标作为开始。数据挖掘过程涉及将业务目标转化为一个或多个数据挖掘任务。在明确定义这些任务之后,任务的性质、可用的数据类型、提交结果的方式,以及模型的准确性和模型可解释性之间的折衷,都会影响数据挖掘技术的选择。
无论你选择哪种技术,以及无论采取什么数据挖掘类型,有效地使用数据挖掘都需要一些统计学知识。
《数据挖掘技术(第3版)——应用于市场营销、销售与客户关系管理》试读电子书免费提供,有需要的留下邮箱,一有空即发送给大家。 别忘啦顶哦!
















 3094
3094











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









