






【机器学习】KNN算法实现鸢尾花分类
目录
1.概述
KNN算法(K-NearestNeighbor)是机器学习领域的基础算法之一,常被用做分类问题与回归问题。
2.算法核心
KNN算法的原理可以总结为"近朱者赤近墨者黑",通过数据之间的相似度进行分类。具体来说,通过计算测试数据和已知数据之间的距离来进行分类。

测试数据的预测结果取决于已知数据和测试数据的距离以及人为设置的k值。如图所示,假设k设置为3,由于测试数据最相近的3个已知数据有2个红色,1个蓝色,则预测结果为红色;假设k设置为5,由于测试数据最相近的5个已知数据又3个蓝色,2个红色,则预测结果为蓝色。
2.1 算法实例
(1)引入相关的包
from sklearn.datasets import load_iris //加载数据集
from sklearn.model_selection import train_test_split //引用一个做模型划分的包
from sklearn.neighbors import KNeighborsClassifier //引入KNN算法的一个包
import numpy as np
(2)加载数据
data=load_iris()
X=data['data'] //特征
Y=data['target'] //类别
(3)对训练集和测试集进行划分
X_train:训练集的特征
Y_train:训练集的分类
X_test:测试集的特征
Y_test:测试集的分类
接下来用到train_test_split模型,输入两个参数,test_size表示最终测试集的数量150*0.2=30个,即会拿120个数据去做训练,剩下的30个数据做测试;random_state指随机数的种子,0表示每次都会得到不一样的随机数
X_train,X_test,Y_train,Y_test=train_test_split(X,Y,test_size=0.2,random_state=0)
(4)模型训练
model是KNN的算法,输入的参数n_neighbors=3表示k=3,然后使用model.fit()方法来执行训练过程
model=KNeighborsClassifier(n_neighbors=3)
model.fit(X_train,Y_train)
(5)模型预测
将X_test作为输入输进去,Y_pred表示得到的30个数据的数组,eg第0个数据属于第一种类别,第1个数据属于第二种类别等
Y_pred=model.predict(X_test)
(6)模型评估
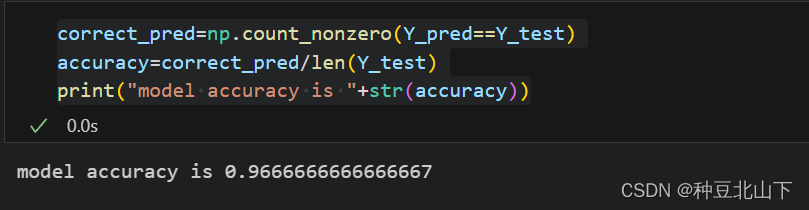
思路:如果Y_pred和实际的模型是一致的,就认为是个正确的预测
将Y_pred和Y_test作比较,就得到正确的个数correct_pred,将其与总测试个数30个相除,就得等到该模型的正确率accuracy
correct_pred=np.count_nonzero(Y_pred==Y_test)
accuracy=correct_pred/len(Y_test)
print("model accuracy is "+str(accuracy))
运行结果
3.谈论
KNN中的一个重要问题就是K值如何选取?这个问题是仁者见仁,智者见智。毕竟,这种问题逃不过多次尝试。但是,我们必须明确不同的K值对结果有不同的影响,不能简单的认为K值越大越好或越小越好。
4.总结
KNN算法的优点:
1. 思想简单,简洁明了
2. 对异常值不敏感
3. 输入数据限制小
4. 精度高
KNN算法的缺点:
1. 计算复杂度高
2. 预测速度缓慢
3. 受数据规模影响敏感















 556
556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









