






目录
一、决策树初步认识
叶子节点:存放决策结果
非叶子节点:特征属性,及其对应输出,按照输出选择分支
决策过程:从根节点出发,根据数据的各个属性,计算结果,选择对应的输出分支,直到到达叶子节点,得到结果
决策树的目的:为了产生一棵泛化能力强,处理未见示例能力强的决策树。
二、构建决策树
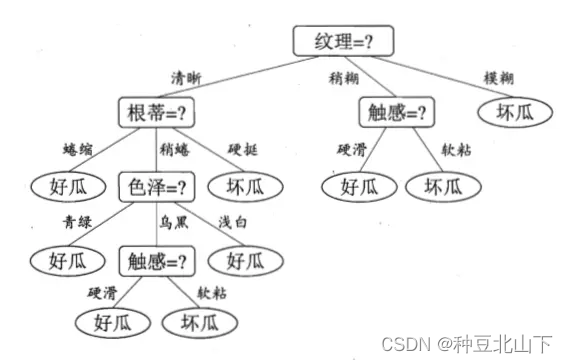
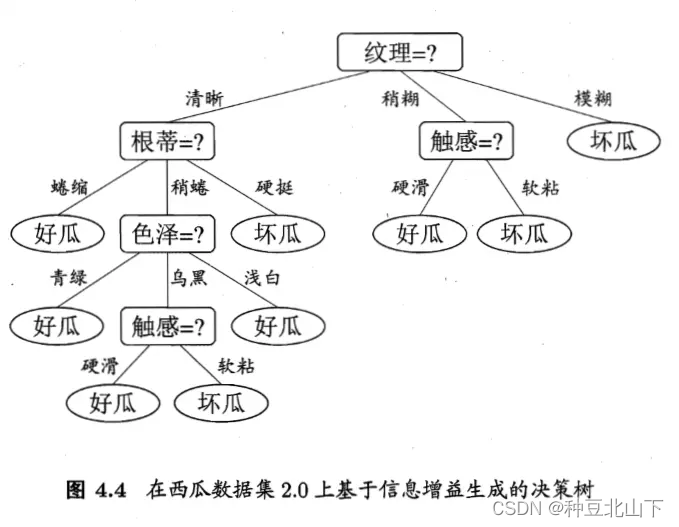
通过上述例子,构建过程的关键步骤是选择分裂属性,即纹理、根蒂、触感、色泽等属性的选择先后次序。分裂属性是在某个节点处按照某一特征属性的不同划分构造不同的分支,其目标是让各个分裂子集尽可能的“纯”,即每个子集尽量都属于同一分类项。
分裂属性分3种情况:
属性是离散值且不要求生成二叉树
属性的每个值作为一个分支
属性是离散值且要求生成二叉树
按照“属于”和“不属于”分成2个分支
属性是连续值
注意:决策树使用自顶向下递归分治法,并采用不回溯的贪心策略。分裂属性的选择算法很多,书中介绍3种常用的算法:信息增益(Information gain)、增益比率(gain ratio)、基尼指数(Gini index)
算法
第8步,选择属性遍历其中取值,可以理解为选择根蒂为划分属性,蜷缩、稍蜷、硬挺为划分值,这种情况下生成子节点,如果蜷缩的全为同一取值(如好瓜),那么就是叶子节点,如果不是再回到上步,以此类推。
在这个属性选择的过程中,使用的就是信息增益(Information gain)、增益比率(gain ratio)、基尼指数(Gini index)3种算法计算划分的属性,个人感觉这三种算法也是构成不同决策树算法的关键。

以下开始讨论 信息增益(Information gain)、增益比率(gain ratio)、基尼指数(Gini index)3种算法
“信息熵”

“信息增益”

“信息增益率”

需要注意的是信息增益率对取值较小的有偏好,所以信息增益和信息增益率都不是最佳的选择。C4.5算法并不是直接选择增益率最大的属性划分,而是使用了启发式的:先从候选属性中找出信息增益高于平均值的属性,再从中选择信息增益率最高的

三、代码实例
ps:样本数据集

1.导入相应的包和数据集
import pandas as pd
titan = pd.read_csv("D:/machine learning/MachineCode/train.csv")2.对数据集中缺失的数据集进行处理
titan.describe()
3.取特征值和目标值
x = titan[["Pclass","Age"]]
y = titan["Survived"]4.缺失值处理
x['Age'].fillna(value=titan["Age"].mean(), inplace=True)#对缺失值取平均值
x
5.数据集拆分
from sklearn.model_selection import train_test_split#导入拆分的包
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state = 22, test_size = 0.25)6.把x_train和x_test转成字典格式
from sklearn.feature_extraction import DictVectorizer#引入特征工程的包
x_train = x_train.to_dict(orient="records")#把数据集转成字典形式的
x_test = x_test.to_dict(orient="records")7.调用特征工程
transfer = DictVectorizer()#调用特征工程的这个包
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)8.调用决策树的包,进行模型训练
from sklearn.tree import DecisionTreeClassifier#调用决策树的这个包
estimator = DecisionTreeClassifier()
estimator.fit(x_train, y_train)#传入参数进行模型训练9.模型评估
y_predict = estimator.predict(x_test)10.模型准确率
ret = estimator.score(x_test, y_test)#准确率
print(ret)
四、代码讲解
1.titan.describe()
解析:查看各列属性的基本统计信息
2.x['Age'].fillna(value=titan["Age"].mean(), inplace=True)
解析:data.fillna会返回新的对象,如果在原有列上把空值进行填充,需要添加参数inplace=True
3.x_train, x_test, y_train, y_test = train_test_split(x, y, random_state = 22, test_size = 0.25)
解析:stratify是为了保持split前类的分布;控制随机状态,固定random_state后,每次构建的模型是相同的、生成的数据集是相同的、每次的拆分结果也是相同的。
4.x_train = x_train.to_dict(orient="records")
解析:df.to_dict(orient='records')是一个Pandas DataFrame对象的方法,用于将DataFrame转换为一个字典列表,其中每个字典表示DataFrame中的一行数据。具体来说,orient='records'参数指定了字典列表的格式,其中每个字典的键是DataFrame的列名,值是相应的行值。
5.x_train = transfer.fit_transform(x_train)
解析:it_transform(trainData)对部分数据先拟合fit,找到该part的整体指标,如均值、方差、最大值最小值等等(根据具体转换的目的),然后对该trainData进行转换transform,从而实现数据的标准化、归一化等等。
6.y_predict = estimator.predict(x_test)
解析:预测 【将测试集的特征值传入,根据先前计算出的模型,来预测所给测试集的目标值】
五、代码基本思路
1.获取数据
2.数据基本处理
2.1确定特征值,目标值
2.2缺失值处理
2.3数据集划分
3.特征工程(字典特征)
4.机器学习(决策树)
5.模型评估
六、实验总结
6.1 优点
简单的理解和解释,树木可视化
决策树学习者可以创建不能很好地推广数据的过于复杂的树,容易发生过拟合。
剪枝cart算法:适用于样本数据少的情况
随机森林:适用于样本数据多的情况















 4841
4841











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









